
ElaticSearch
ElaticSearch快速入门
全文检索是指:
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体的内容读取出来了
例如,在csdn中搜索elaticsearch快速入门:
倒排索引
索引类似目录,平时我们使用的都是索引,通过主键定位到某条数据,倒排索引则是数据对应到主键。
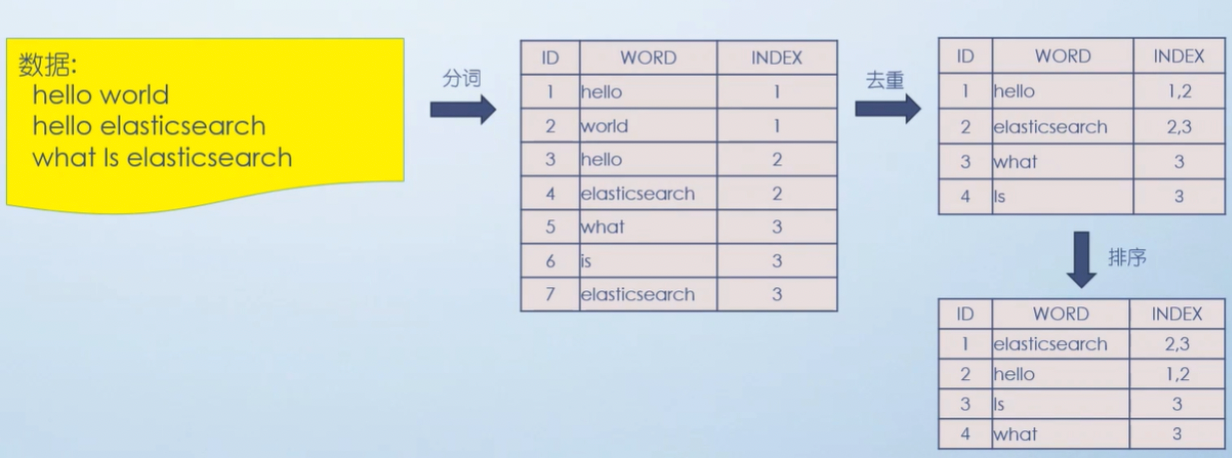
这里以一个博客文章的内容为例:
正排索引:
| 文章ID | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 浅析Java设计模式 | Java设计模式是每一个Java程序员都应该掌握的进阶知识 |
| 2 | Java多线程设计模式 | Java多线程与设计模式结合 |
假设有一个站内搜索的功能,是通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种我们就可以称之为倒排索引。
假设我们搜索关键词“Java设计模式”,那么就可以通过倒排索引,找到对应的文章的主键id。
| 关键词 | 文章ID |
|---|---|
| Java | 1,2 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
简单理解,正向索引是通过key找value,反向索引则是通过value找key。ElaticSearch底层在检索时使用的就是倒排索引。
ElaticSearch简介
ElaticSearch(简称ES)是一个分布式、RESTful风格的搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
ES起源于Lucene,基于Java语言开发,具有高性能,易扩展的优点,ES有以下应用场景:
- 站内搜索
- 日志管理与分析
- 大数据分析
- 应用性能监控
- 机器学习
传统的关系型数据库和ES的区别:
- ES:Schemaless/相关性/高性能全文检索
- RDMS:事务性/Join
ElaticSearch基本概念
可以将ES中的一些基本概念映射到关系型数据库:
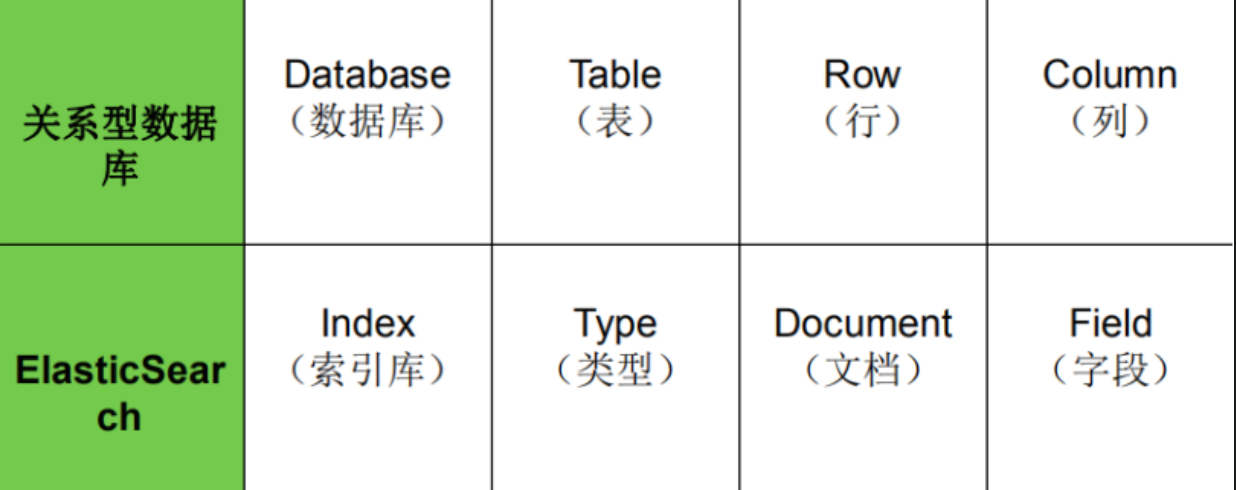
索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来表示同意(必须全部是小写字母的),并且当我们要对对应于这个索引的文档进行索引、搜索、更新和删除操作的时候,都要用到这个名字。
文档
ES是面向文档的,文档是所有可搜索数据的最小单位。例如:
- 日志文件中的日志项
- 一本电影的具体信息/一张唱片的详细信息
- MP3播放器里的一首歌/一篇PDF文档中的具体内容
文档会被序列化成JSON格式,保存在ES中:
- JSON对象由字段组成
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
每个文档都有一个Unique UD,可以自己指定ID或者通过ES自动生成。一篇文档包含了一系列字段,类似关系型数据库表中的一条记录。
JSON文档,格式灵活,不需要预先定义格式:
- 字段的类型可以指定或者通过ES自动推算
- 支持数组/支持嵌套
文档的元数据信息:
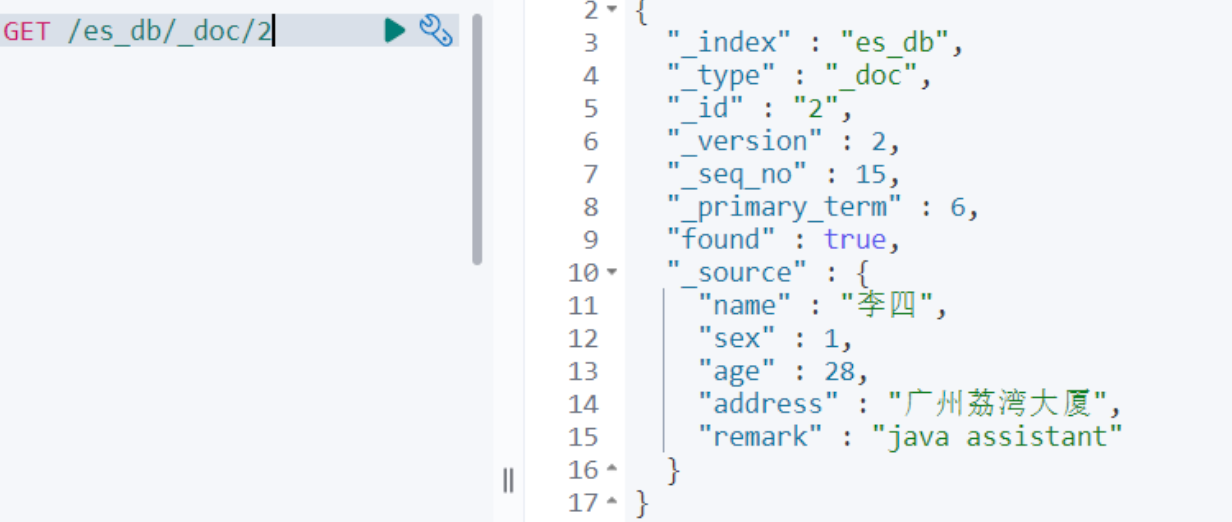
其中各项含义:
- _index:文档所属的索引名
- :文档所属的类型名
- _id:文档唯一Id
- _source:文档的原始JSON数据
- _version:文档的版本号,修改删除操作 _version 都会自增1
- _seq_no:和 _version 一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的 _seq_no 大于先写入Doc的 _seq_no。
- _primary_term: _primary_term 主要是用来恢复数据时处理当多个文档的 _seq_no 一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等, _primary_term 会递增1。
索引操作
注意:索引命名必须小写,不能以下划线开头。
创建索引格式:
#创建索引
PUT /es_db
#创建索引时可以设置分片数和副本数
PUT /es_db
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
#修改索引配置
PUT /es_db/_settings
{
"index": {
"number_of_replicas": 1
}
}
文档操作
添加示例数据:
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
PUT /es_db/_doc/2
{
"name": "李四",
"sex": 1,
"age": 28,
"address": "广州荔湾大厦",
"remark": "java assistant"
}
PUT /es_db/_doc/3
{
"name": "王五",
"sex": 0,
"age": 26,
"address": "广州白云山公园",
"remark": "php developer"
}
PUT /es_db/_doc/4
{
"name": "赵六",
"sex": 0,
"age": 22,
"address": "长沙橘子洲",
"remark": "python assistant"
}
PUT /es_db/_doc/5
{
"name": "张龙",
"sex": 0,
"age": 19,
"address": "长沙麓谷企业广场",
"remark": "java architect assistant"
}
PUT /es_db/_doc/6
{
"name": "赵虎",
"sex": 1,
"age": 32,
"address": "长沙麓谷兴工国际产业园",
"remark": "java architect"
}
添加文档:
# 创建文档,指定id
# 如果id不存在,创建新的文档,否则先删除现有文档,再创建新的文档,版本会增加
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
#创建文档,ES生成id
POST /es_db/_doc
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
POST和PUT都能起到创建/更新的作用,PUT需要对一个具体的资源进行操作,也就是要确定id才能进行更新/创建;POST时可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新。
使用PUT更新文档的时候,整个json都会被替换,也就是说,如果文档存在,现有文档会被删除,新的文档会被索引。
# 全量更新,替换整个json
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25
}
#查询文档
GET /es_db/_doc/1
如果需要部分更新,可以使用 _update,格式:POST /索引名称/_update/id。_update不会删除原来的文档,而是实现真正的数据更新。
# 部分更新:在原有文档上更新
# Update -文档必须已经存在,更新只会对相应字段做增量修改
POST /es_db/_update/1
{
"doc": {
"age": 28
}
}
#查询文档
GET /es_db/_doc/1
还可以使用_update_by_query更新文档:
POST /es_db/_update_by_query
{
"query": {
"match": {
"_id": 1
}
},
"script": {
"source": "ctx._source.age = 30"
}
}
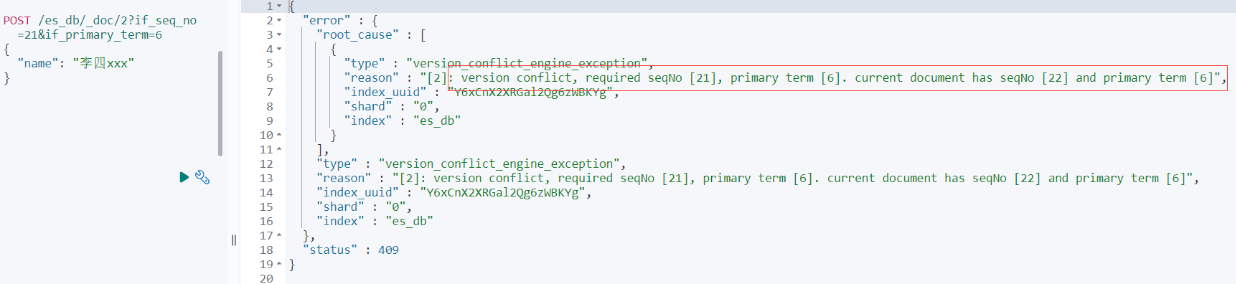
_seq_no 和 _primary_term 是对 _version的优化,7.x版本的ES默认使用这种方式控制版本,所以当在高并发环境下使用乐观锁机制修改文档时,要带上文档的 _seq_no 和 _primary_term 进行更新:
POST /es_db/_doc/2?if_seq_no=21&if_primary_term=6
{
"name": "李四xxx"
}
如果版本号不对,就会抛出版本冲突异常,如下图:
查询文档有两种方式。
根据id查询文档,格式:GET /索引名称/_doc/id
GET /es_db/_doc/1
条件查询_search,格式:GET /索引名称/_doc/_search
# 查询前10条文档
GET /es_db/_doc/_search
ES Search API提供了两种查询条件查询搜索方式:
- REST风格的请求URI,直接将参数带过去
- 封装到request body中,这种方式可以定义更加易读的JSON格式
#通过URI搜索,使用“q”指定查询字符串,“query string syntax” KV键值对
#条件查询, 如要查询age等于28岁的 _search?q=*:***
GET /es_db/_doc/_search?q=age:28
#范围查询, 如要查询age在25至26岁之间的 _search?q=***[** TO **] 注意: TO 必须为大写
GET /es_db/_doc/_search?q=age[25 TO 26]
#查询年龄小于等于28岁的 :<=
GET /es_db/_doc/_search?q=age:<=28
#查询年龄大于28前的 :>
GET /es_db/_doc/_search?q=age:>28
#分页查询 from=*&size=*
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1
#对查询结果只输出某些字段 _source=字段,字段
GET /es_db/_doc/_search?_source=name,age
#对查询结果排序 sort=字段:desc/asc
GET /es_db/_doc/_search?sort=age:desc
通过请求体搜索的示例:
GET /es_db/_search
{
"query": {
"match": {
"address": "广州白云"
}
}
}
删除文档的格式:DELETE /索引名称/_doc/id。
DELETE /es_db/_doc/1
ES文档批量操作
批量操作可以减少网络连接所产生的开销,提升性能。
- 支持在一次API调用中,对不同的索引进行操作
- 可以在URI中指定index,也可以在请求的Payload中进行
- 操作中单条操作失败,并不会影响其他操作
- 返回结果中包含了每一条操作执行的结果
批量对文档进行写操作是通过 _bulk 的API来实现的。
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过 _bulk 操作文档,一般至少有两行参数(或偶数行参数)
- 第一行参数为执行操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
actionName表示操作类型,主要有create,index,delete和update。
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":3}}
{"id":3,"title":"fox老师","content":"fox老师666","tags":["java","面向对象"],"create_time":1554015482530}
{"create":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"mark老师","content":"mark老师NB","tags":["java","面向对象"],"create_time":1554015482530}
如果原文档不存在,则会创建新文档,如果原文档存在,则是替换(全量修改原文档)。
批量删除delete:
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}
批量修改update:
POST _bulk
{"update":{"_index":"article","_type":"_doc","_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article","_type":"_doc","_id":4}}
{"doc":{"create_time":1554018421008}}
组合应用:
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":3}}
{"id":3,"title":"fox老师","content":"fox老师666","tags":["java","面向对象"],"create_time":1554015482530}
{"delete":{"_index":"article","_type":"_doc","_id":3}}
{"update":{"_index":"article","_type":"_doc","_id":4}}
{"doc":{"create_time":1554018421008}}
ES的批量查询可以用mget和msearch两种,其中mget是需要我们知道它的id,可以指定不同的index,也可以指定返回值source。msearch可以通过字段查询来进行一个批量的查找。
_mget 的使用方式如下:
#可以通过ID批量获取不同index和type的数据
GET _mget
{
"docs": [
{
"_index": "es_db",
"_id": 1
},
{
"_index": "article",
"_id": 4
}
]
}
#可以通过ID批量获取es_db的数据
GET /es_db/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 4
}
]
}
#简化后
GET /es_db/_mget
{
"ids": [
"1",
"2"
]
}
_msearch 的使用方式如下:
在 _msearch 中,请求格式和bulk类似。查询一条数据需要两个对象,第一个设置index和type,第二个设置查询语句。查询语句和search相同。如果只是查询一个index,我们可以在url中带上index,这样,如果查该index可以直接用空对象表示。
GET /es_db/_msearch
{}
{"query":{"match_all":{}},"from":0,"size":2}
{"index":"article"}
{"query":{"match_all":{}}}
ElaticSearch高级查询语法Query DSL
参考链接:https://note.youdao.com/ynoteshare/index.html?id=924a9d435d78784455143b1dda4a874a&type=note&_time=1684249060388
当数据写入ES时,数据将会通过分词被切分为不同的trem,ES将term与其对应的文档列表建立一种映射关系,这种结构就是倒排索引。如下图所示:
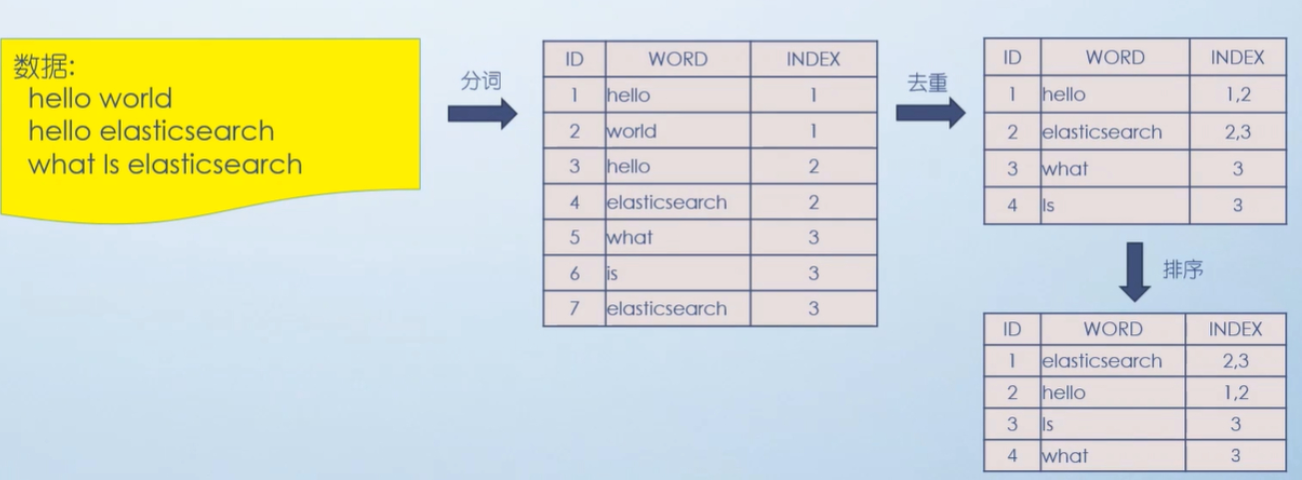
为了进一步提升索引的效率,ES在term的基础上利用term的前缀或者后缀构建了term index,用于对term本身进行索引,ES实际的索引结构如下图所示:
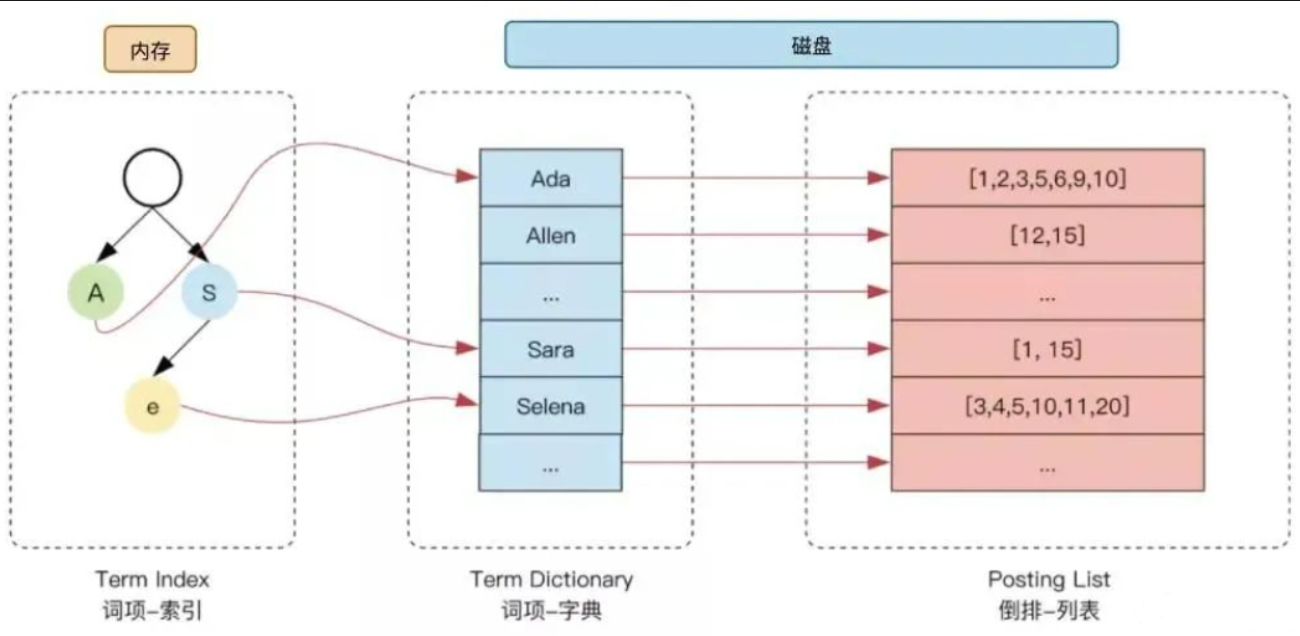
这样当我们去搜索某个关键词时,ES首先根据它的前缀或者后缀迅速缩小关键词在term dictionary中的范围,大大减少了磁盘IO的次数。
- 单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排所列的关联关系。
- 倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项(Posting):
- 文档ID
- 词频TF-该单词在文档中出现的次数,用于相关性评分
- 位置(Position)-单词在文档中的分析的位置,用于短语搜索(match phrase query)
- 偏移(Offset)-记录单词的开始结束位置,实现高亮线显示
ES的JSON文档中的每个字段,都有自己的倒排索引,可以指定对某些字段不做索引:
- 优点:节省内存空间
- 缺点:字段无法被搜索
文档映射mapping
Mapping类似数据库中的schema的定义,作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔等
- 字段,倒排索引的相关配置(Analyzer)
ES中Mapping映射可以分为动态映射和静态映射。
在关系型数据库中,需要先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而ES中不需要预先定义Mapping映射(即关系型数据库的表、字段等),在文档写入ES时,会根据文档的字段自动识别类型,这种机制称之为动态映射。
与之对应的,在ES中预先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
动态映射的机制,使得我们无需手动定义Mappings,ES会自动根据文档信息,推算出字段的类型,但是由的时候会推算的不对,例如地理位置信息。当类型如果设置的不对时,会导致一些功能无法正常运行,例如Range查询。
Dynamic Mapping类型自动识别:
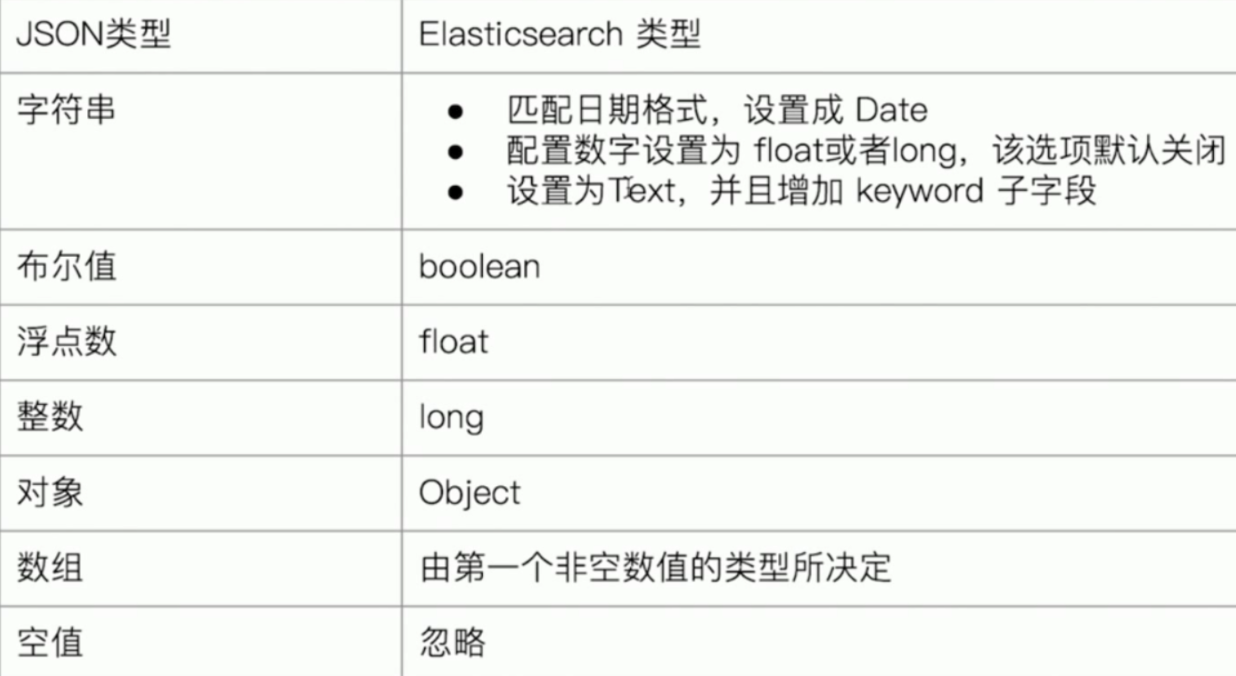
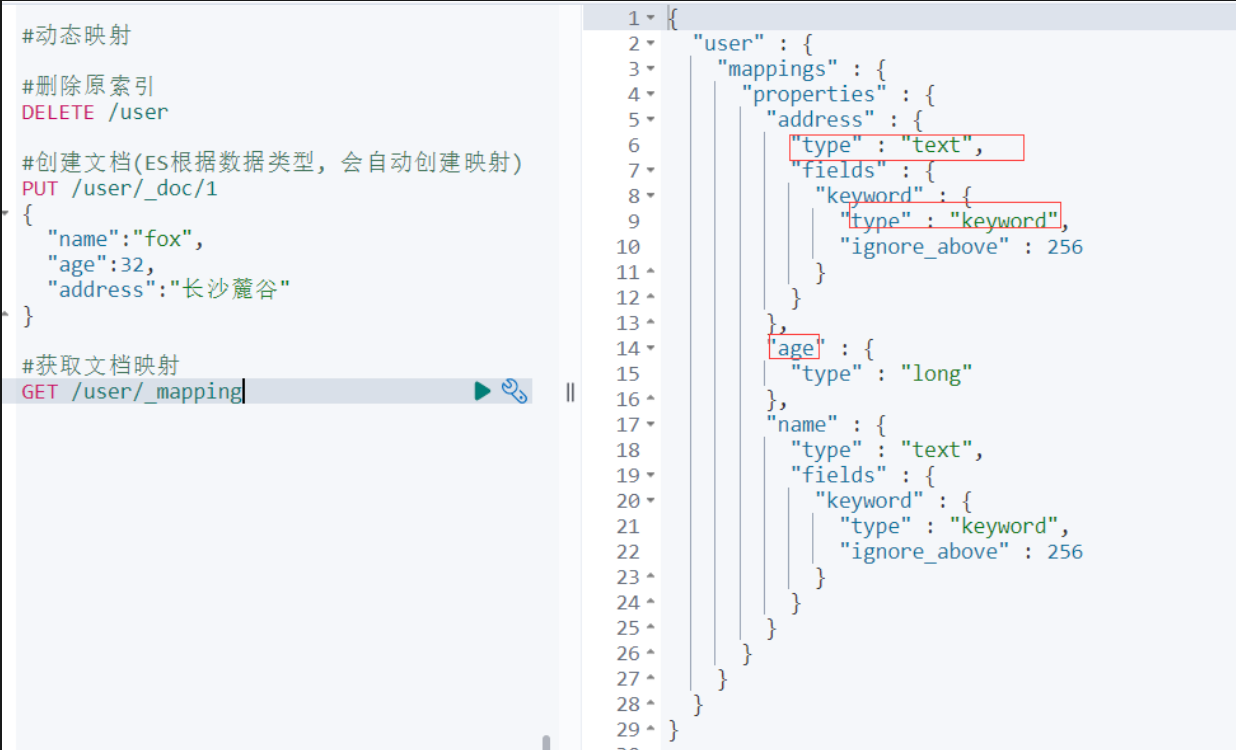
示例:
#删除原索引
DELETE /user
#创建文档(ES根据数据类型, 会自动创建映射)
PUT /user/_doc/1
{
"name":"fox",
"age":32,
"address":"长沙麓谷"
}
#获取文档映射
GET /user/_mapping
执行结果:
对于已经创建的文档,如果要更改Mapping的字段类型,有两种情况:
- 新增加的字段
- dynamic设为true时,一旦有新增的文档写入,Mapping也同时被更新
- dynamic设为false,Mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在 _source 中
- dynamic设置为strict(严格控制策略),文档写入失败,抛出异常
- 对于已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene实现的倒排索引,一旦生成后,就不允许修改
- 如果希望改变字段类型,可以利用reindex API,重建索引
这样设计的原因是:
- 如果修改了字段的数据类型,会导致已经被索引的数据无法被搜索
- 但是如果是增加新的字段,就不会有这样的影响
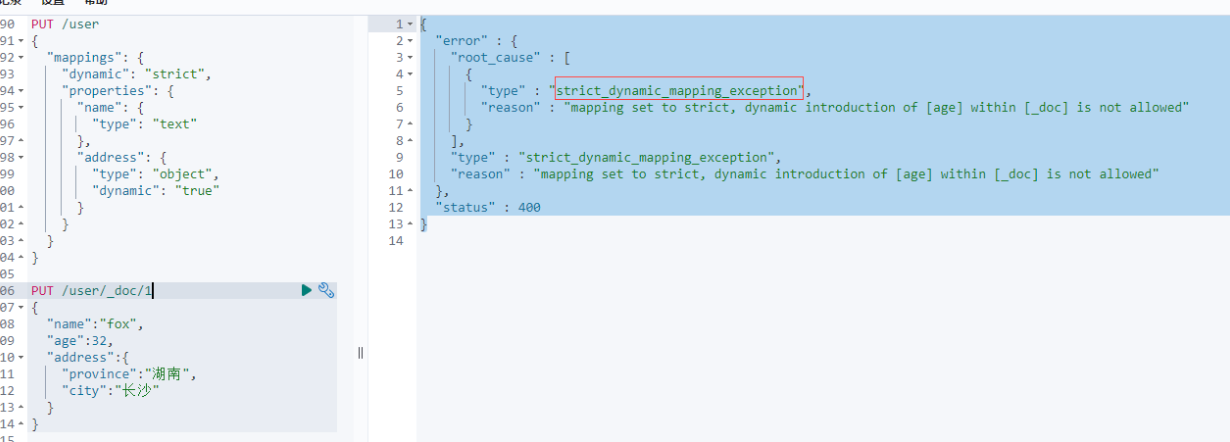
测试用例:
PUT /user
{
"mappings": {
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
# 插入文档报错,原因为age为新增字段,会抛出异常
PUT /user/_doc/1
{
"name":"fox",
"age":32,
"address":{
"province":"湖南",
"city":"长沙"
}
}
dynamic设置成strict,新增age字段导致文档插入失败:
修改dynamic后再次插入文档成功
#修改daynamic
PUT /user/_mapping
{
"dynamic":true
}
ElaticSearch搜索技术与聚合查询
ElaticSearch高阶功能
ElaticSearch集群架构实战及其原理
链接:https://note.youdao.com/ynoteshare/index.html?id=16ca3fcfcdda46a976cfd978e20df4be&type=note&_time=1684856471454
为什么说ElaticSearch是一个近实时的搜索引擎?