
Java虚拟机
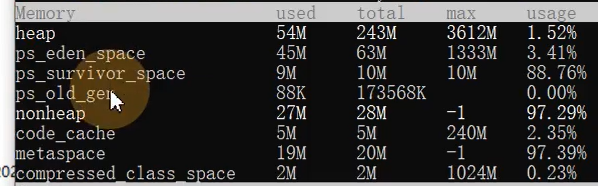
运行时数据区中包含哪些区域?哪些线程共享?哪些线程独享?
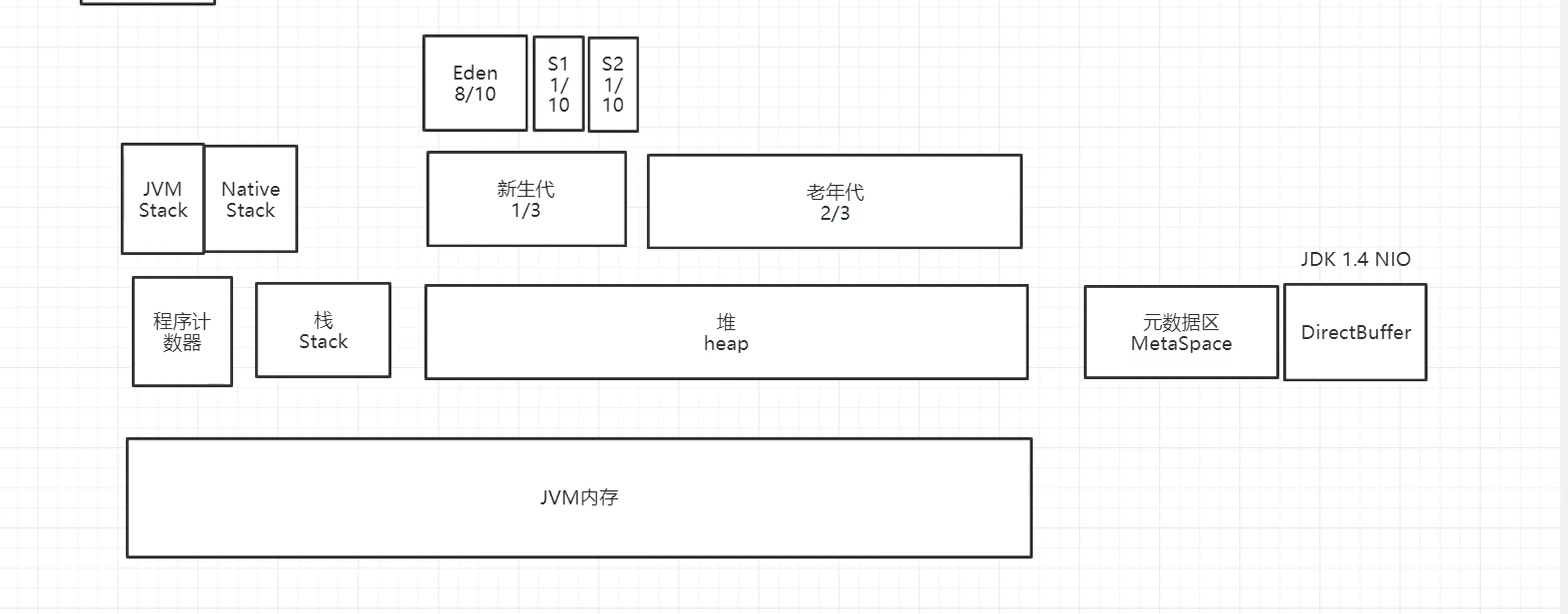
Java 创建一个对象的过程?
- 检查类是否已经被加载
- 为对象分配内存空间
- 为分配的内存空间初始化零值(为对象字段设置零值)
- 对对象进行其它设置(设置对象头)
- 执行构造方法
如何访问对象?
- 使用句柄的方式
- 使用直接指针的方式
Java 内存模型的原子性、可见性和有序性是通过哪些操作实现的?
- 原子性:synchronized
- 可见性:volatile
- 有序性:volatile和synchronized
什么是双亲委派机制?有什么作用?
Java的类加载器:AppClassLoader -> ExtClassLoader -> BootStrapClassLoader
每一种类加载器都有自己的加载目录,Java中的AppClassLoader、ExtClassLoader 都继承了URLClassLoader,URLClassLoader继承了SecureClassLoader,SecureClassLoader又继承了ClassLoader,每个类加载器对他加载过的类,都是有一个缓存的:
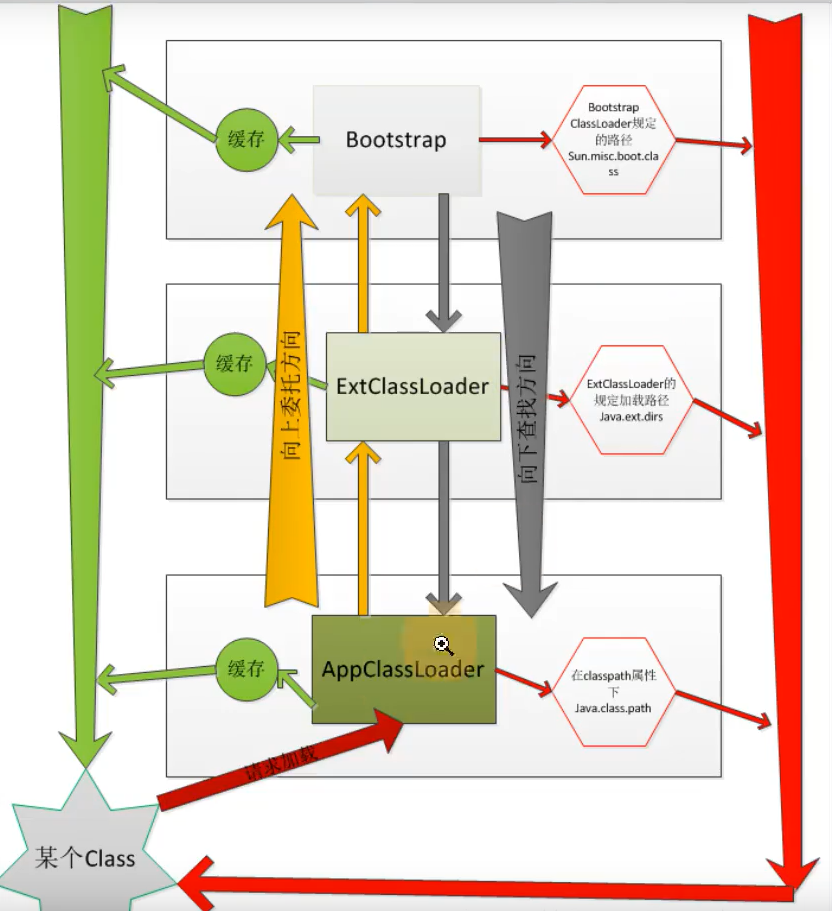
双亲委派:向上委托查找,向下委托,作用:保护Java的层的类不会被应用程序覆盖
核心代码:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
Java类加载的全过程是怎么样的?
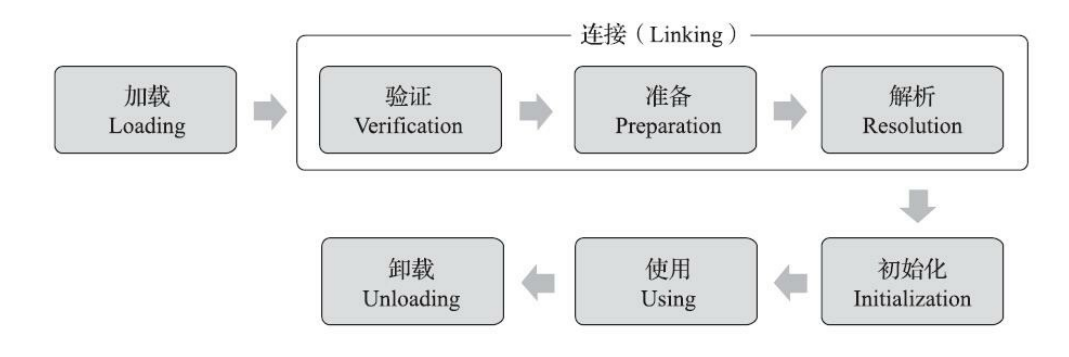
类加载过程:加载 -> 连接 -> 初始化 -> 使用 -> 卸载
- 加载:把Java的字节码数据加载到JVM内存当中,并映射成JVM认可的数据结构
- 连接:可以分为三个小的阶段:
- 验证:检查加载到的字节码信息是否符合JVM规范
- 准备:创建类或接口的静态变量,并赋初始值,半初始化状态
- 解析:将符号引用转为直接引用
- 初始化:创建对象
你了解分代理论吗?
目前绝大部分的JJVM,在针对对象进行垃圾收集的时候,会将对象熬过垃圾收集的次数,视为对象的年龄,依次将对象至少划分为新生代和老年代。分代收集理论基于以下三种假说和经验法则:
弱分代假说
绝大数对象,在第一次垃圾收集时就会被回收,按照经验法则,这个值高达百分之九十八
强分代假说
熬过越多次收集过程的对象就越难以消亡
跨代引用假说
该假说认为只会存在很少的跨代引用。因为只要经过一些次数的垃圾收集,即使还存在跨代引用,新生代会变成老年代,跨代引用也就自然小时了,所以跨代引用的数量不会多
Java堆分为新生代和老年代,针对收集对象处于哪一代,一共有以下四种收集方式:
- 部分收集
- 新生代收集(Minor GC/Young GC),只收集新生代垃圾对象
- 老年代收集(Major GC/Old GC),只收集老年代垃圾对象,目前只有CMS收集器会单独收集老年代对象
- 混合收集(Mixed GC),收集来自整个新生代以及部分老年代中的垃圾对象,目前只有G1会有这种行为
- 整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集
JDK 中有几种引用类型?分别的特点是什么?
在JDK1.2之前,一个对象只有“被引用”或者“未被引用”两种状态,但这种描述方式不能满足所有的场景,譬如我们希望描述一类对象:当内存空间还足够时,能保留在内存之中,如果内存空间在垃圾收集器后仍然非常警长,那就可以抛弃这些对象,这个时候就需要对引用的概念进行扩充。
| 引用类型 | 定义 | 特点 |
|---|---|---|
| 强引用(Strong Reference) | 通过new关键赋值的引用 | 只要强引用关系还存在,垃圾收集器永远不会回收掉引用的对象 |
| 软引用(Soft Reference) | 还有用,但非必须的对象 | 内存不够时一定会被GC,长期不用也会被GC |
| 弱引用(Weak Reference) | 非必须对象 | 被弱引用关联的对象只能生存到下一次垃圾收集发生为止。无论当前内存是否足够,都会回收 |
| 虚引用(Phantom Reference) | “幽灵引用”或者“幻影引用” | 对象被垃圾收集器回收时收到一个系统通知 |
一个对象从加载到JVM,再到GC清除,都经历了什么过程?
详细步骤说明:
用户创建一个对象,JVM首先需要到方法区去找对象的类型信息,然后再创建对象。
JVM要实例化一个对象,首先要在堆中先创建一个对象 -> 半初始化状态
对象首先会分配在堆内存中新生代的Eden区,然后经过一次Minor GC,对象如果存活,就会进入S区,在后续的每次GC中,如果对象一直存活,就会在S区来回拷贝,每移动一次,年龄加1,年龄最大值是15,默认就是最大年龄是15。超过年龄先之后,对象转入老年代。
当方法执行结束后,栈中的指针会先移除掉。
堆中的对象,经过Full GC就会被标记为垃圾,然后被GC线程清理掉。
怎么样确定一个对象不是垃圾?
有两种定位垃圾的方式:
- 引用计数法:这种方式是给堆内存当中的每个对象记录一个引用个数,引用个数为0的就认为是垃圾。这是早期JDK采用的方式,引用计数无法解决循环引用的问题
- 根可达算法:这种方式是在内存中,从引用根对象向下一直找引用,找不到的对象就是垃圾
什么是GC Root?
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量
- 在方法区中常量引用的对象,譬如字符串常量池里的引用。
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointException),还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
JVM有哪些垃圾回收算法?
| 算法 | 速度 | 空间开销 | 移动对象 |
|---|---|---|---|
| Mark-Sweep | 中等 | 少(但会堆积碎片) | 否 |
| Mark-Compact | 最慢 | 少(不堆积碎片) | 是 |
| Copying | 最快 | 通常需要活对象的2倍大小(不堆积碎片) | 是 |
什么是STW?
STW:stop the world,是在垃圾回收算法执行过程当中,需要将JVM内存冻结的一种状态,在STW状态下,Java所有的线程都是停止执行的,GC线程除外,只有native方法可以执行,但是,不能与JVM交互,GC各种算法优化的重点,就是减少STW,同时这也是JVM调优的重点。
JVM有哪些垃圾回收器?
| 收集器 | 串行、并行或并发 | 新生代、老年代 | 算法 |
|---|---|---|---|
| Serial | 串行 | 新生代 | 复制算法 |
| Serial Old | 串行 | 老年代 | 标记-整理 |
| ParNew | 并行 | 新生代 | 复制算法 |
| Parallel Scavenge | 并行 | 新生代 | 复制算法 |
| Parallel Old | 并行 | 老年代 | 标记-整理 |
| CMS | 并发 | 老年代 | 标记-清除 |
| G1 | 并发 | 不区分 | 标记-整理+复制算法 |
什么是三色标记算法?
CMS的核心算法就是三色标记。
三色标记:是一种逻辑上的抽象,将每个内存对象分成三种颜色:黑色:表示自己和成员变量都已经标记完毕。灰色:自己标记完了,但是成员变量还没有完全标记完。白色:自己未标记完。
CMS通过增量标记increment update的方式来解决漏标的问题。
在G1当中采用SATB的方式来避免错标和漏标的情况。
如何回收方法区?
方法区的垃圾回收主要有两种,废弃的常量和无用的类,其中要称为无用的类,要同时满足下面三个条件:
- Java堆中不存在该类的任何实例对象
- 加载该类的类加载器已经被回收
- 该类对应的java.lang.Class对象不在任何地方被引用,且无法在任何地方通过反射访问该类的方法
JVM 中的安全点和安全区各代表什么?
写屏障你了解吗?
解决并发扫描时对象消失问题的两种方案?
CMS 垃圾收集器的步骤?
1、初始标记阶段:STW 只标记出根对象直接引用的对象
2、并发标记:继续标记其他对象,与应用程序时并发执行
3、重新标记:STW对并发执行阶段的对象进行重新标记
4、并发清除:并行。将产生的垃圾清除。清除过程中,应用程序又会不断的产生新的垃圾,叫做浮动垃圾。这些垃圾就要留到下一次GC过程中清除。
CMS 有什么缺点?
- CMS收集器对CPU资源非常敏感
- CMS处理器无法处理浮动垃圾
- 在收集结束的时候,会产生大量的空间碎片
G1垃圾收集器的步骤,G1有什么优缺点?
G1的优点:
- 停顿时间短
- 用户可以指定最大的停顿时间
- 不会产生内存碎片:G1的内存布局并不是固定大小以及固定数量的分代区域划分
缺点:
G1需要记忆集(卡表)来记录新生代和老年代之间的引用关系,这种数据结构在G1中需要占用大量的内存,可能达到整个堆内存容量的20%甚至更多。而且G1中维护记忆集的成本较高,带来了更高的执行负载,影响效率。
CMS在小内存应用上的表现要优于G1,而大内存应用上G1更有优化,大小内存的界限是6GB到8GB。
讲一下内存分配策略?
内存溢出和内存泄漏的区别?
内存溢出(Out of Memory)是指程序在申请内存时,没有足够的空间供其使用
内存泄漏(Memory Leak)是指程序在申请内存后,无法释放已申请的内存空间
如何进行JVM调优?
JVM调优主要是通过定制JVM运行参数来提高Java应用程序的运行速度。
JVM参数有哪些?
JVM参数大致可以分为三类:
1、标准指令:-开头,这些是所有的HotSpot都支持的参数。可以用Java -help打印出来。
2、非标准指令:-开头,这些指令通常是跟特定的HotSpot版本对应的,可以用Java -X打印出来
3、不稳定参数:-XX开头,这一类参数是跟特定HotSpot版本对应的,并且变化非常大,详细的文档资料非常少,在JDK1.8版本下,有几个常用的不稳定指令:Java -XX:+PrintCommandLineFlags:查看当前命令的不稳定指令。
虚拟机基础故障处理工具有哪些?
| 工具 | 作用 |
|---|---|
| jps | 虚拟机进程状况工具 |
| jstat | 虚拟机统计信息监视工具 |
| jinfo | Java配置信息工具 |
| jmap | Java内存映射工具 |
| jstack | Java堆栈跟踪工具 |
| JVisualVM | 图形化展示 |
| JConsole | 远程控制 |
怎么查看一个Java进程的JVM参数,谈谈你了解的JVM参数
打印出所有不稳定参数所有默认值:java -XX:+PrintFlagsInitial
打印出所有最终生效的不稳定指令:java -XX:+PrintFlagsFinal
什么情况下堆内存会溢出,什么情况方法区会内存溢出?
栈溢出的典型例子:
private static void fun() {
//递归,调用自己
fun();
}
方法区内存溢出的例子:
private static void fun() {
//递归,调用自己
fun();
}
JDK8 为什么要将永久代改为元空间?
在JDK8之前,Java虚拟机中的永久代(Permanent Generation)用于存储类的元数据信息、静态变量、常量等。然而,永久代存在一些问题,例如固定大小、难以调优、容易导致内存溢出等。
为了解决这些问题,并引入更灵活和可调整大小的内存区域,JDK8将永久代(Permanent Generation)替换为元空间(Metaspace),并将其定义为方法区(Method Area)的一部分。
以下是一些原因解释为什么JDK8将永久代改为元空间,并将其归类为方法区:
内存动态分配:永久代的大小是固定的,无法动态调整,这在一些场景下可能会导致内存溢出。元空间通过使用本地内存(Native Memory)来存储元数据,可以根据应用程序的需要进行动态分配和释放,更加灵活。
类元数据卸载:永久代存储的类元数据在应用程序运行期间是不可卸载的,即使类已经不再使用。而元空间中的类元数据可以进行卸载,当类不再被引用时,虚拟机可以回收其占用的内存,避免了永久代中的内存泄漏问题。
自动调整空间大小:元空间可以根据应用程序的需要自动调整大小,避免了调整永久代大小的繁琐工作。在元空间中,可以通过设置参数来控制元数据的大小和增长策略,以满足应用程序的需求。
元数据分配效率:元空间使用本地内存存储元数据,相较于永久代,元空间的元数据分配效率更高。在永久代中,由于采用传统的JVM对象分配方式,需要进行内存分配和垃圾回收等操作,而元空间中的元数据分配是基于本地内存的,更加高效。