
Elasticsearch
什么是倒排索引?有什么好处?
索引:从id到内容。
倒排索引:从内容到id。好处:比较适合做关键字检索。可以控制数据的总量。提高查询效率。
搜索引擎为什么MySQL查询快?
ES了解多少?说说你们公司的ES集群架构。
是一个基于Lucene框架(是一个非常高效的全文检索引擎框架)的搜索引擎产品,you know for search,提供了restful风格的操作接口。
ES包含了一些核心概念:
索引 index:类似关系型数据库中的table
文档 document:row
- 字段 field text\keyword\byte:列
映射Mapping:Schema
- 查询方式:DSL(ES的新版本也支持SQL)
分片sharding和副本replicas:index都是由sharding组成的。每个sharding都有一个或者多个备份。
另外关于ES的使用场景:ES可以用在大数量的搜索场景下,另外ES也有很强大的计算能力,可以用在用户画像等场景。
如何进行中文分词?
IK分词器。HanLp中文分词器。
ES写入数据与查询数据的原理。
写入数据的原理:
客户端发写数据的请求是,可以发往任意节点,这个节点就会成为coordinating node 协调节点
计算的点文档要写入的分片:计算时就采用hash取模的方式计算
协调节点就会进行路由,将请求转发给对应的primary sharding所在的datanode。
datanode节点上的primary sharding处理请求,写入数据到索引库,并且将数据同步到对应的replica sharding
等promary sharding 和 replica sharding都保存好文档了之后,返回客户端响应
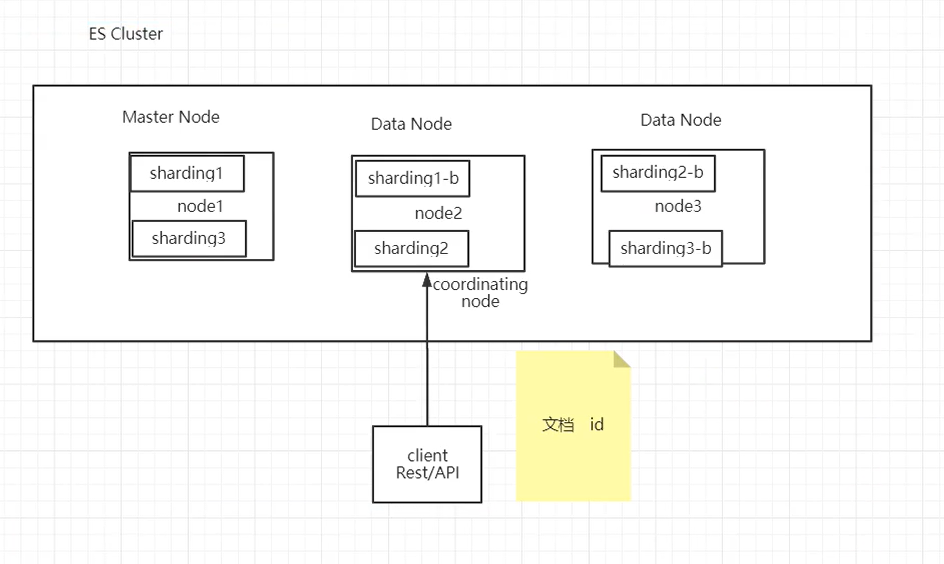
查询数据的原理:
- 客户端发送请求可发给任意节点,这个节点就成为协调节点;
- 协调节点将查询请求广播到每一个数据节点,这些数据节点的分片就会处理该查询请求;
- 每个分片进行数据查询,将符合条件的数据放在一个队列当中,并将这些数据的文档ID、节点信息、分片信息都返回给协调节点;
- 由协调节点将所有的返回结果进行汇总,并排序;
- 协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据整合返回给客户端。
ES部署时,要如何进行优化?
- 集群部署优化
- 调整ES的一些重要参数。path.data尽量使用固态硬盘,定制JVM堆内存大小,ES的参数,实际上大部分情况下是不需要调优的,如果有性能问题,最好的办法是安排更合里的sharding布局并且增加节点数据。
- 更合理的sharding布局,让sharding对应的replica sharding尽量在同一个机房。
- Linux服务器上一些优化策略,不要用root用户:修改虚拟内存大小,修改普通用户可以创建的最大线程数。
ES生态:ELK日志收集解决方案:filebeat -> logstash -> elaticsearch -> kibana。