
集合
集合的优点
数组的缺点:
- 长度开始时必须指定,而且一旦指定,不能更改
- 保存的必须为同一类型的元素
- 使用数组进行增加元素、删除元素、插入元素等相对复杂
使用集合的好处:
- 可以动态保存任意多个对象,使用比较方法
- 提供了一系列方便操作对象的方法:add、remove、set、get等
在Java中,集合主要分为两大类:单例集合和多列集合,其中单例集合有List、Set,双列集合有Map。
单列集合
核心API - java.util.List
- java.util.ArrayList
- java.util.Vector(线程安全)
- java.util.LinkedList
核心API - java.util.Set
- java.util.HashSet
- java.util.TreeSet
多列集合
核心API - java.util.Map
- java.util.Hashtable
- java.util.HashMap
- java.util.TreeMap
List
ArrayList源码分析
核心特点:
ArrayList中维护了一个Object类型的数组elementData:
transient Object[] elementData; // non-private to simplify nested class access当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍
transient表示该属性不会被序列化。
LinkedList源码分析
Map
Map接口的不同实现之间的关系:
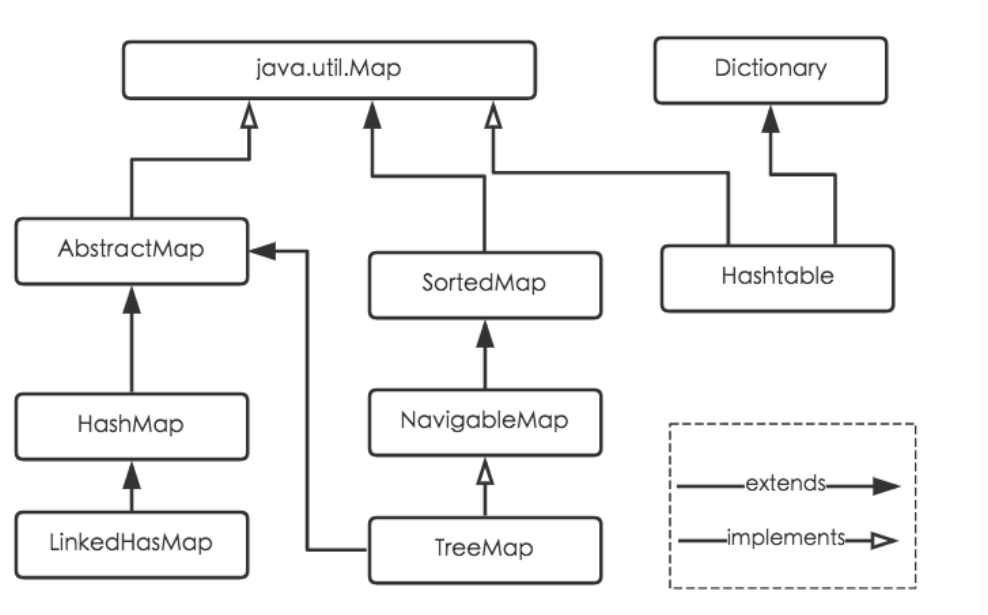
具体实现类特点的说明:
- HashMap:它根据键的hashCode值缓存数据,大多数情况下可以直接定位它的值,因而具有很快的访问速度,但是遍历顺序却是不确定的。HashMap最多只允许一条记录的键位null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致,如果需要满足线程安全,可以用Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap
- Hashtable:Hashtable是历史遗留类,官方建议使用HashMap替代它,与HashMap不同的是,它继承自Dictionary类,并且是线程安全的,如果需要在线程安全的场合下使用,建议使用ConcurrentHashMap
- LinkedHashMap:LinkedHashMap保存了记录的插入顺序,可以按照插入的顺序使用Iterator遍历
- TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排列,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap,在使用TreeMao的时候,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常
对于上述四种类型的类,要求映射种的key是不可变对象。不可变对象可以保证该对象在创建后它的哈希值不会被改变,如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
HashMap原理分析
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。JDK1.8对HashMap底层的实现进行了优化,例如引入了红黑树的数据结构和扩容优化等,因此,分析HashMap需要注意区别JDK1.7和JDK1.8的区别。
存储方式
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加红黑树部分)实现的,如下图所示:
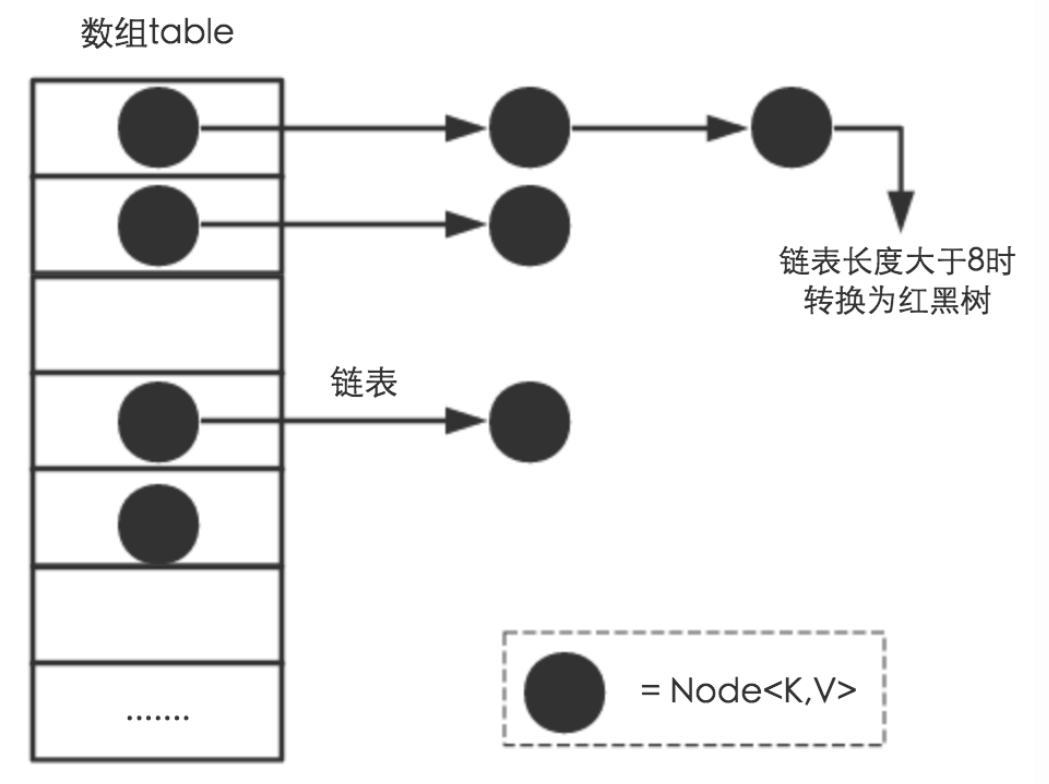
在HashMap的底层存储实现上是存储在:
transient Node<K,V>[] table;
其中Node具体如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
Node是HashMap的一个内部类,实现了Map.Enrty接口,本质就是一个映射(键值对)。上图中每个黑色圆点就是一个Node对象。
HashMap就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,HashMap就是采用了链地址法,即数组加链表的方式,在每个数组元素上都加上一个链表结构,当数据被Hash后,得到数组下标,把数据房子啊对应下标元素的链表上,例如程序执行如下代码:
map.put("jycoder","吉永超");
系统将调用“jycoder”这个key的hashCode方法得到其哈希值,然后通过哈希算法的后两步运算(高位运算和取模运算)来定位该键值对的存储位置,有时两个key会定位到相同的问题,这个时候就发生了哈希碰撞。对于哈希算法而言,计算的结果越分散,哈希碰撞的概率就越小,Map的存取效率就会越高。
如果哈希桶的数组很大,即使较差的哈希算法也会比较分散,如果哈希桶的数组很小,即使再好的哈希算法也会出现较多碰撞,所以就需要根据实际情况确定哈希桶数组的大小,并且在此基础上设计好的哈希算法来减少哈希碰撞。
HashMap中有几个非常重要的属性:
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount; // HashMap内部结构发生变化的次数
int size; // HashMap中实际存在的键值对数量
其中,Node[] table的初始长度length默认值是16,负载因子loadFactor默认值是0.75,threshold是HashMap所能容纳的最大数量的Node(键值对)的个数。它们之间的关系是:,也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数就越多。
当超过threshold所能容纳的数量,HashMap就需要重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。默认的负载因子0.75是对空间和时间效率的平衡选择,一般不要轻易修改,如果内存很多而又对时间效率要求很高,可以降低负载因子loadFactor的值;相反,如果内存紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
size这个字段的含义就是HashMap中实际存在的键值对数量,而modCount主要记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败。这里的内部结构发生变化指的是强调的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖步属于结构变化。
在HashMap中,哈希桶数组table的长度length大小必须为2n,HashMap采用这种设计,主要是为了取模和扩容时做优化,同时为了减少冲突,具体可以参考:关于hashMap的容量为什么是2的幂次方。定位哈希桶索引位置时,也加入例如高位参与运算的过程。
不过,即使负载因子和哈希算法设计的再合理,也避免不了拉链过长的情况,一旦拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8中,对数据结构做了进一步的优化,引入了红黑树,当链表长度太长(默认超过8)时,链表就转换为了红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会运用到红黑树的插入、删除、查找等算法。具体可以参考红黑树。
方法实现
确定哈希桶数组索引位置
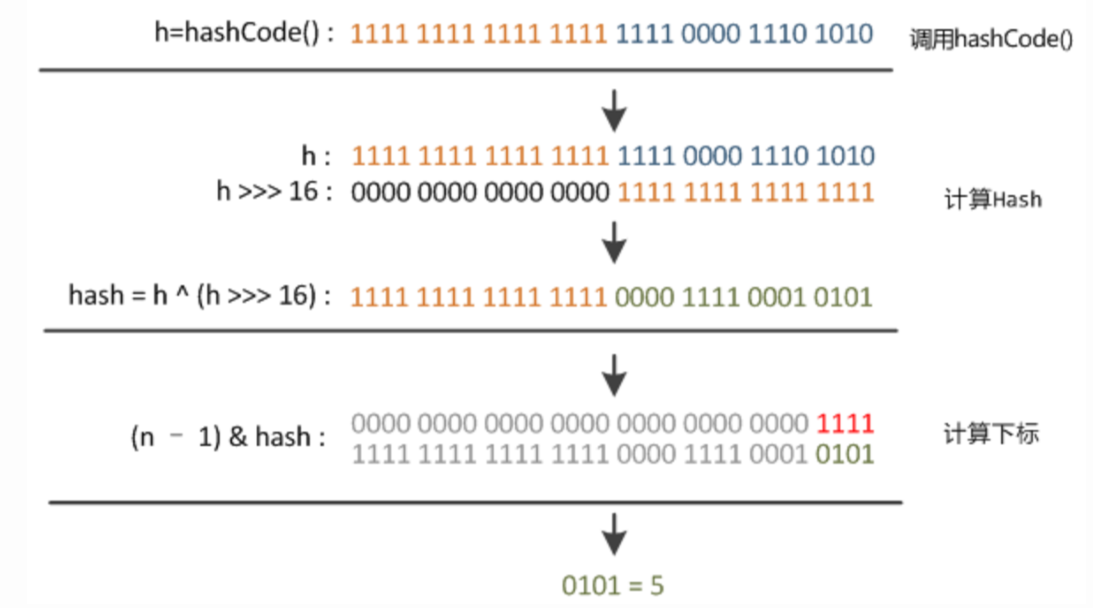
不管增加、删除、查找键值对,定位到哈希桶数组的都是很关键的第一步,前面提到过HashMap的数据结构是数组和链表的结合, 如果每个位置上的元素数量只有一个,那么当我们使用哈希算法求得这个位置的时候,马上就可以获取对应位置的元素,而不需要遍历整个链表。HashMap定位数组索引位置的方法,直接决定了哈希方法的离散性能,源码的实现如下:
// 方法一
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 方法二
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length - 1); //第三步 取模运算,JDK1.8在计算位置的时候采用方法一返回的哈希值 & 长度-1
}
可以发现,在JDK1.8中,哈希算法基本步骤就是三步:取key的hashCode值、高位运算、取模运算。
对于任意给定的对象,只要它的hashCode方法返回值相同,那么程序调用方法所计算得到的Hash码值总是相同的。其中一种方式对将哈希值对数组长度取模运算,这样做的好处是元素的分布会相对来说比较均匀,但是,模运算的消耗还是比较大的。在HashMap中会调用方法二来计算对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h&(table.length-1)来得到该对象的保存位,而HashMap的长度length总是为2n,此时,h&(table.length-1)与h%length这两种运算结果式等价的,但是&比%具有更高的效率。
假设容量为2的n次幂的化,那么table.length的二进制就是一个1后面n个0,而length - 1就是一个0后面n个1,那么在计算为了说明h & (table.length - 1),由于length - 1的二进制前面都是0,相当于舍弃了高位,只保留了后面的n位,后面的n刚好在0到length之间,也就是等于h % length取余。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高位异或低16位实现的:(h = k.hashcode())^(h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
下面举例说明,n位table的长度:
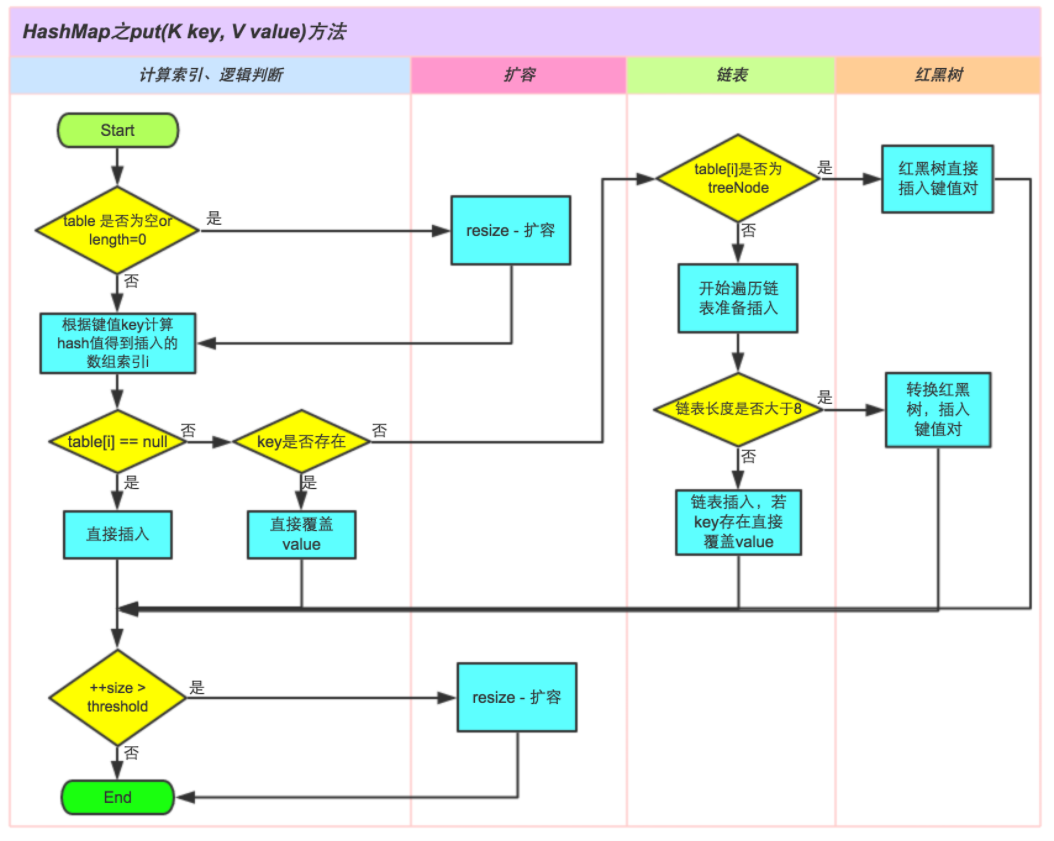
put方法
put方法的整体执行过程如下图:
JDK1.8put方法的源代码如下:
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤1:table位空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤2:计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 步骤3:节点key存在,直接value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 步骤4:判断该链表为红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤5:该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表长度大于8转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 步骤6:超过最大容量就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
详细说明如下:
- 判断键值对数组table[i]是否为空或者为null,否则执行resize()进行扩容
- 根据键值key计算hash值得到插入元素数组的索引i,如果
table[i] == null,直接新建节点添加,转向步骤6,否则转向步骤3 - 判断table[i]的首个元素是否和key一样,如果相同(hashCode && equals)直接覆盖value,否则转向步骤4
- 判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向步骤5
- 遍历table[i],判断链表的长度是否大于8,大于8的话就把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作,遍历过程中若发现key已经存在直接覆盖value即可
- 插入成功后,判断实际存在的键值对数量size是否超过了最大容量,如果超过,就进行扩容操作
扩容机制
扩容就是重新计算容量。在向HashMap对象中不断地添加元素,而HashMap对象内部地数组无法装在更多地元素时,对象就需要扩大数组的长度,以便能装入更多的元素。
JDK1.7中的扩容过程:
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int)(newCapacity * loadFactor);//修改阈值
}
newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上的新元素总会被放在链表的头部位置,这样先放一个索引上的元素会被放到Entry链的尾部(如果发生了哈希冲突的话),在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
下面通过具体的例子来说明扩容过程。假设我们所使用的哈希算法就是简单的用key mod 一下表的大小(也就是数组的长度)。其中的哈希桶数组table的size等于2,所以key3、5、7,put顺序依次为5、7、3/在mod 2以后冲突都在table[1]这里了。这里假设负载因子loadFactor=1,即当键值对的实际大小size大于table的实际大小时进行扩容。接下来三个步骤时哈希桶数组resize成4,然后所有的Node重新rehash的过程。

在JDK1.8中,由于融入了红黑树,相对而言就比较复杂:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引 + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引 + oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
JDK1.8中对扩容做了一些优化,经过观察可以发现,我们每次扩容都会将长度扩容为原来的2倍,所以,元素的位置要么是在原来的位置,要么就是在原位置再移动2次幂的位置。在下图中,n为table的长度,图(a)表示扩容前key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算的结果。
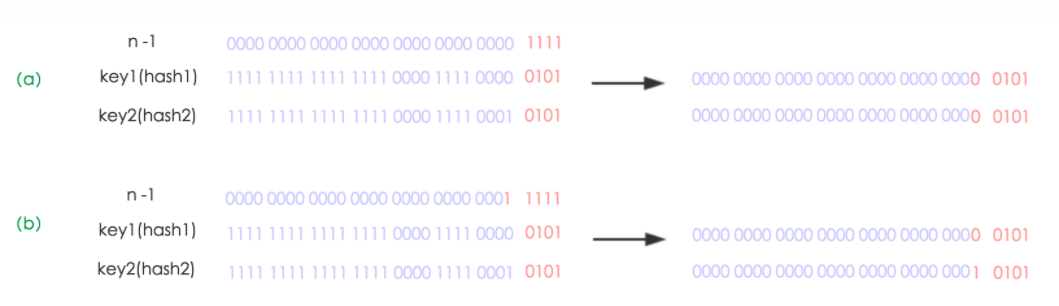
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
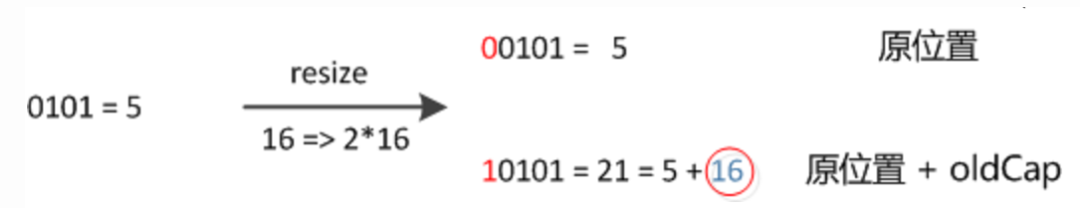
因此,我们在扩充HashMap的时候,不再需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的哪个bit是1还是0就好了,是0就表示索引没有变化,是1就表示索引变成了“原索引+oldCap”,下图为16扩充至32的过程的示意图:
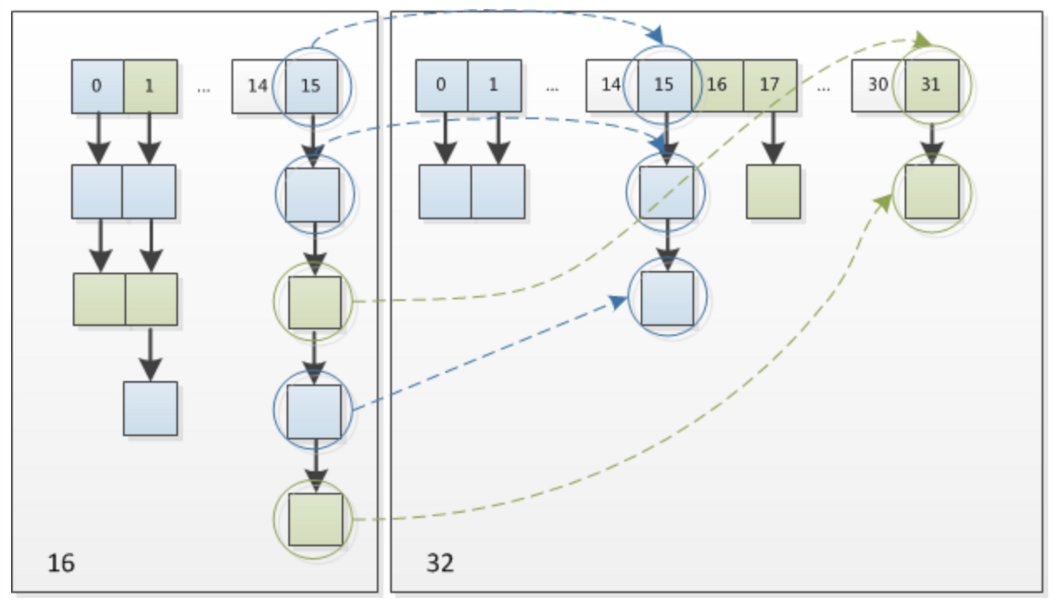
这个设计非常的巧妙,既省去了重新计算hash值得时间,同时,由于新增的1bit是0还是1可以认为是随机的,因为resize的过程,均匀的把之前的冲突节点分散到新的bucket了。需要注意的是,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但从上图可以看出,JDK1.8不会倒置。
线程安全性
在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。HashMap线程不安全的主要原因是在多线程的使用场景下可能会造成死循环,如果多个线程同时put时,如果同时触发了rehash操作,会导致HashMap中的链表中出现循环节点,进而使得后面get的时候,会出现死循环。
JDK1.7的示例如下:
public class HashMapInfiniteLoop {
private static HashMap<Integer,String> map = new HashMap<Integer,String>(2,0.75f);
public static void main(String[] args) {
map.put(5, "C");
new Thread("Thread1") {
public void run() {
map.put(7, "B");
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, "A);
System.out.println(map);
};
}.start();
}
}
其中,map初始化为一个长度为2的数组,loadFactor=0.75,threshold=2*0.75=1,也就是说当put第二个元素的时候,map就需要进行resize了。
通过设置断点让线程1和线程2同时debug到transfer方法的首行,注意此时两个线程已经成功添加数据。放开thread1的断点至transfer方法的Entry next = e.next,这一行,然后放开线程2的断点,让线程2进行resize,结果如下图:
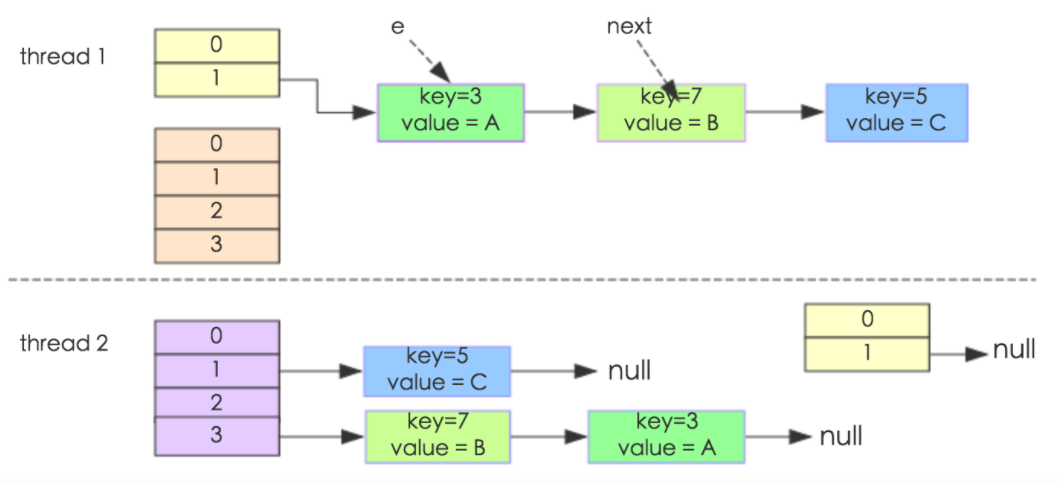
注意,Thread1的e指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。
线程一被调度回来执行,先是执行newTable[i] = e,然后是e = next,导致了e指向了key(7),而下一次循环的next = e.next导致了next指向了key(3)。
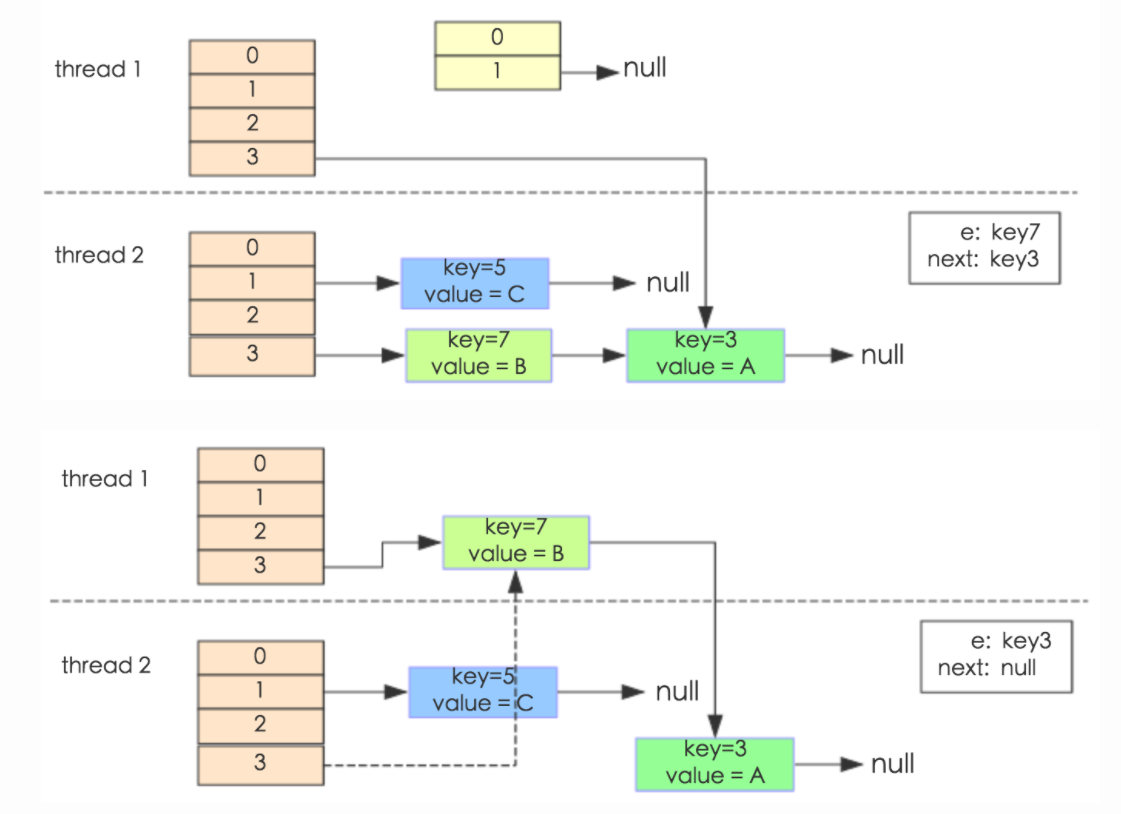
e.next = newTable[i]导致key(3)指向了key(7)。注意:此时的key(7).next已经指向了key(3),环形链表就这样出现了。
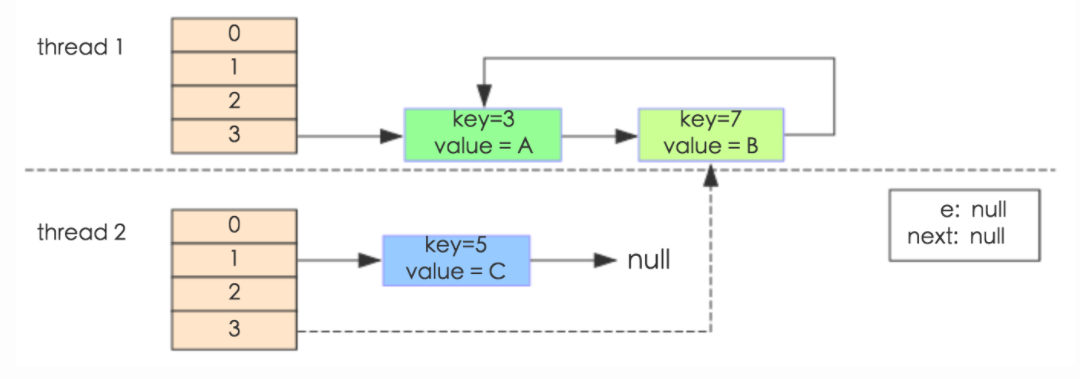
此时,再对map做索引位置为3的get操作,就会死循环在这里,CPU成功达到100%,比如,调用map.get(11),即会引起死循环,而且map中还丢失了元素,(5,“c”)也已经不再map中了。
以上是JDK7的情况,JDK8虽然不会出现死循环的情况,但是会发生数据被覆盖的情况。
https://zhuanlan.zhihu.com/p/76735726
ConcurrentHashMap源码分析
JDK1.7的实现
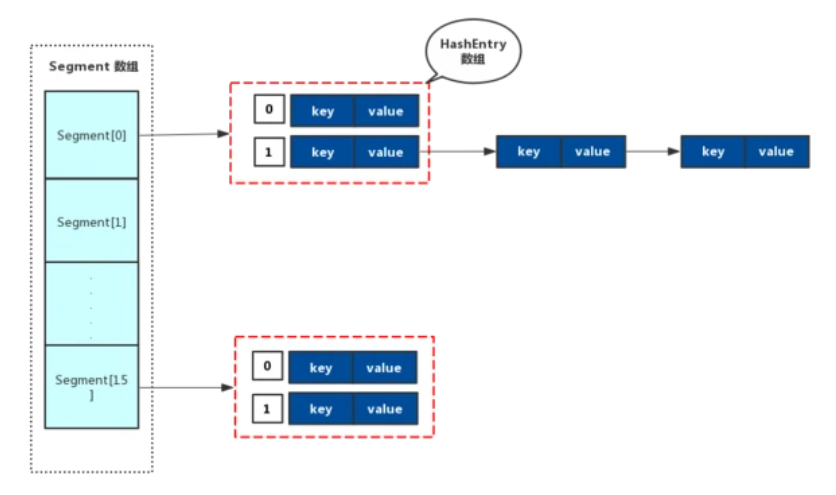
ConcurrentHashMap的成员变量中,包含了一个Segment的数组,Segment是ConcurrentHashMap的内部类,然后在Segment这个类中,包含了一个HashEntry数组,而HashEntry也是ConcurrentHashMap的内部类。HashEntry中,包含了key和value以及next指针(类似于HashMap中的Entry),所以HashEntry可以构成一个链表。
简单来说,ConcurrentHashMap数据结构为一个Segment数组,Segment的数组结构为HashEntry的数组,而HashEntry存放的就是我们的键值对,可以构成链表,它们之间的关系如下图:
它的put方法:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 二次哈希,以保证数据的分散性,避免哈希冲突
int hash = hash(key.hashCode());
int j = (hash >>> segmentShift) & segmentMask;
// Unsafe 调用方式,直接获取相应的 Segment
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
在put方法中,首先是通过二次哈希减小哈希冲突的可能性,根据hash值以Unsafe调用方式,直接获取响应的Segment,最终将数据添加到容器中是由segment对象的put方法来完成。Segment对象的put方法源代码如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 无论如何,确保获取锁 scanAndLockForPut会去查找是否有key相同Node
ConcurrentHashMap.HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
ConcurrentHashMap.HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
ConcurrentHashMap.HashEntry<K,V> first = entryAt(tab, index);
for (ConcurrentHashMap.HashEntry<K,V> e = first;;) {
// 更新已存在的key
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new ConcurrentHashMap.HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 判断是否需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
由于Segment对象本身就是一把锁,所以在新增数据的时候,相应的Segment对象块是被锁住的,其它线程并不能操作这个Segment对象,这样就保证了数据的安全性,在扩容的时候也是这样的,在JDK1.7中的ConcurrentHashMap扩容只是针对Segment对象中的HashEntry数组进行扩容,这个时候,由于Segment对象是一把锁,所以在rehash的过程中,其他线程无法对Segment的hash表做操作,这就解决了HashMap中由于put数据引起的闭环问题。
JDK1.8的实现
在容器的安全上,1.8中的ConcurrentHashMap放弃了JDK1.7的分段技术,而是采用了CAS机制 + synchronized来保证并发安全性,但是在ConcurrentHashMap实现里保留了Segment定义,这仅仅是为了保证序列化时的兼容性,并没有结构上的用处。
在存储结构上,JDK1.8中ConcurrentHashMap放弃了HashEntry结构而是采用了跟HashMap结构非常相似,采用Node数组加链表(链表长度大于8的时候转为红黑树)的形式,Node节点设计如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...省略...
}
JDK1.8的ConcurrentHashMap的示意图如下:
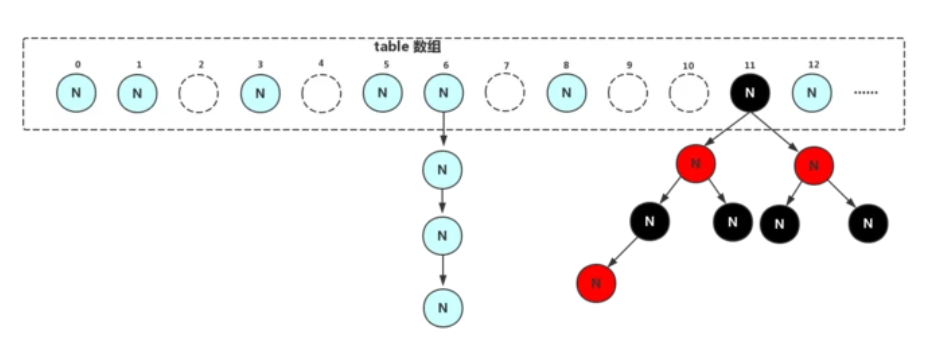
ConcurrentHashMap新增的核心方法有两个:putVal(新增)和transfer(扩容)。
public V put(K key, V value) {
return putVal(key, value, false);
}
可以看到put方法本身也是调用putVal方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果 key 为空,直接返回
if (key == null || value == null) throw new NullPointerException();
// 两次 hash ,减少碰撞次数
int hash = spread(key.hashCode());
// 记录链表节点得个数
int binCount = 0;
// 无条件得循环遍历整个 node 数组,直到成功
for (ConcurrentHashMap.Node<K,V>[] tab = table;;) {
ConcurrentHashMap.Node<K,V> f; int n, i, fh;
// lazy-load 懒加载的方式,如果当前 tab 容器为空,则初始化 tab 容器
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 通过Unsafe.getObjectVolatile()的方式获取数组对应index上的元素,如果元素为空,则直接无所插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//// 利用CAS去进行无锁线程安全操作
if (casTabAt(tab, i, null,
new ConcurrentHashMap.Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果 fh == -1 ,说明正在扩容,那么该线程也去帮扩容
else if ((fh = f.hash) == MOVED)
// 协作扩容操作
tab = helpTransfer(tab, f);
else {
// 如果上面都不满足,说明存在 hash 冲突,则使用 synchronized 加锁。锁住链表或者红黑树的头结点,来保证操作安全
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {// 表示该节点是链表
binCount = 1;
// 遍历该节点上的链表
for (ConcurrentHashMap.Node<K,V> e = f;; ++binCount) {
K ek;
//这里涉及到相同的key进行put就会覆盖原先的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
ConcurrentHashMap.Node<K,V> pred = e;
if ((e = e.next) == null) {//插入链表尾部
pred.next = new ConcurrentHashMap.Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof ConcurrentHashMap.TreeBin) {// 该节点是红黑树节点
ConcurrentHashMap.Node<K,V> p;
binCount = 2;
if ((p = ((ConcurrentHashMap.TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 插入完之后,判断链表长度是否大于8,大于8就需要转换为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// 如果存在相同的key ,返回原来的值
if (oldVal != null)
return oldVal;
break;
}
}
}
//统计 size,并且检测是否需要扩容
addCount(1L, binCount);
return null;
}
详细说明:
- 在ConcurrentHashMap中不允许key val字段为空,所以第一步先校验key value的值。key、val两个字段都不是null才继续往下走,否则直接抛出了NullPointerException异常,这是与HashMap有区别的地方,HashMap是可以允许为空的
- 判断容器是否初始化,如果容器没有初始化,则调用initTable方法初始化
initTable方法具体如下:
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 负数表示正在初始化或扩容,等待
if ((sc = sizeCtl) < 0)
// 自旋等待
Thread.yield(); // lost initialization race; just spin
// 执行 CAS 操作,期望将 sizeCtl 设置为 -1,-1 是正在初始化的标识
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// CAS 抢到了锁
try {
// 对 table 进行初始化,初始化长度为指定值,或者默认值 16
if ((tab = table) == null || tab.length == 0) {
// sc 在初始化的时候用户可能会自定义,如果没有自定义,则是默认的
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 创建数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 指定下次扩容的大小,相当于 0.75 × n
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
Table本质上就是一个Node数组,其初始化过程也就是对Node数组的初始化过程,方法中使用了CAS策略执行初始化操作。初始化流程为:
- 判断sizeCtl值是否小于0,如果小于0表示ConcurrentHashMap正在执行初始化操作,所以需要先等待一会,如果其他线程初始化失败还可以顶替上去
- 如果sizeCtl值大于等于0,则基于CAS策略抢占标记sizeCtl为-1,表示ConcurrentHashMap正在执行初始化,然后构造table,并更新sizeCtl的值
初始化号table之后继续添加元素:
- 根据双哈希之后的hash值找到数组对应的小标位置,如果该位置未存放节点,也就是说不存在哈希冲突,则使用CAS无锁的方法将数据添加到容器中,并且结束循环
- 如果并未满足第三步,加入到扩容大军中(ConcurrentHashMap扩容采用的是多线程的方式),扩容时并未跳出死循环,这一点就保证了容器在扩容的时候并不会有其他的线程进行数据添加操作,这也保证了容器的安全性
- 如果哈希冲突,则进行链表操作或者红黑树操作(如果链表树超过8,则修改链表为红黑树),在进行链表或者红黑树操作时,会使用synchronized锁把头结点锁住,保证了同时只有一个线程修改链表,防止出现链表成环
- 进行addCount(1L,binCount)操作,该操作会更新size大小,判断是否需要扩容
addCount方法的源码如下:
// X传入的是1,check 传入的是 putVal 方法里的 binCount,没有hash冲突的话为0,冲突就会大于1
private final void addCount(long x, int check) {
ConcurrentHashMap.CounterCell[] as; long b, s;
// 统计ConcurrentHashMap里面节点个数
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
ConcurrentHashMap.CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// check就是binCount,binCount 最小都为0,所以这个条件一定会为true
if (check >= 0) {
ConcurrentHashMap.Node<K,V>[] tab, nt; int n, sc;
// 这儿是自旋,需同时满足下面的条件
// 1. 第一个条件是map.size 大于 sizeCtl,也就是说需要扩容
// 2. 第二个条件是`table`不为null
// 3. 第三个条件是`table`的长度不能超过最大容量
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
// 该判断表示已经有线程在进行扩容操作了
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 如果可以帮助扩容,那么将 sc 加 1. 表示多了一个线程在帮助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 如果不在扩容,将 sc 更新:标识符左移 16 位 然后 + 2. 也就是变成一个负数。高 16 位是标识符,低 16 位初始是 2
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
addCount 方法做了两个工作:
- 对 map 的 size 加一
- 检查是否需要扩容,或者是否正在扩容。如果需要扩容,就调用扩容方法,如果正在扩容,就帮助其扩容。
最后是ConcurrentHashMap的扩容过程:
HashTable源码分析
HashTable底层基于数组与链表实现,通过synchronized关键字保证线程安全,但作为已经废弃的类,建议使用ConcurrentHashMap。
HashTable的默认构造函数,容量为11,加载因子为0.75,扩容大小2倍+1。
Set
HashSet源码分析
HashSet实现了Set接口,在底层就是在HashMap的基础上包了一层,只不过存储的时候value默认存储了一个Object的静态变量,取的时候也是只返回key:
private static final Object PRESENT = new Object();
核心方法的实现:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
HashSet是调用HashMap的put()方法,而put方法中有这样的逻辑,如果哈希值和key都一样,就会直接拿新的值覆盖旧值,而HashSet就是利用这个特性来保证唯一性的。
反射
反射的定义
反射主要指程序可以访问、检测和修改其本身状态或行为的一种能力,在Java环境中,反射机制允许程序在执行时获取类自身的定义信息,例如实现动态创建属性、方法和类的对象、变更属性的内容和执行特定的方法的功能,从而使Java具有动态语言的特性,增强了程序的灵活性可移植性。
反射的作用
Java反射机制的主要用于实现以下功能:
- 在运行时判断任意一个对象所属的类型
- 在运行时构造任意一个类的对象
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时调用任意一个对象的方法,哪怕可以调用private方法
核心API
核心包 - java.lang.reflect
- java.lang.Class:代表一个类
- java.lang.reflect.Method:代表类的方法
- java.lang.reflect.Constructor:代表类的构造方法
- java.lang.reflect.Array:提供了动态创建数组及访问数组元素的静态方法。该类中的所有方法都是静态的
IO模型
IO基础
参考:Linux IO模式及select poll epoll详解。
文件描述符:是计算机科学中的一个术语,用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
关于句柄的解释;牧童的手为指针,杏花村的牌子为句柄,杏花村酒店为对象的实例。句柄是资源在创建过程中由Windows赋予的,它就是代表这个资源的。而指针实质上是某个变量或者对象所在内存位置的首地址,是指向对象的。一个是指向,一个是代表,二者是不同的。一个是直接找到对象(指针),一个是间接找到对象(句柄)。例如,杏花村可以搬家(实际上程序运行过程中,资源在内存中的地址是变化的),那么牧童的手的指向也就不同(指针)了,然而即使搬了家,“杏花村”这块牌匾是不变的,通过打听“杏花村”这个名称,还是可以间接找到它的(地址)。HANDLE的本意是把柄,把手的意思,是你与操作系统打交道的东西。
对于一次IO访问(以read为例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
- 等待数据准备
- 将数据从内核拷贝至进程中
基于这两个阶段,Linux操作系统有以下四种IO模型的方案:
- 阻塞IO
- 非阻塞IO
- IO多路复用
- 异步IO
Linux网络编程IO模型
阻塞IO模型
这是最传统的IO模型,即在读写数据的过程中会阻塞,一个典型的读操作流程大致如下:
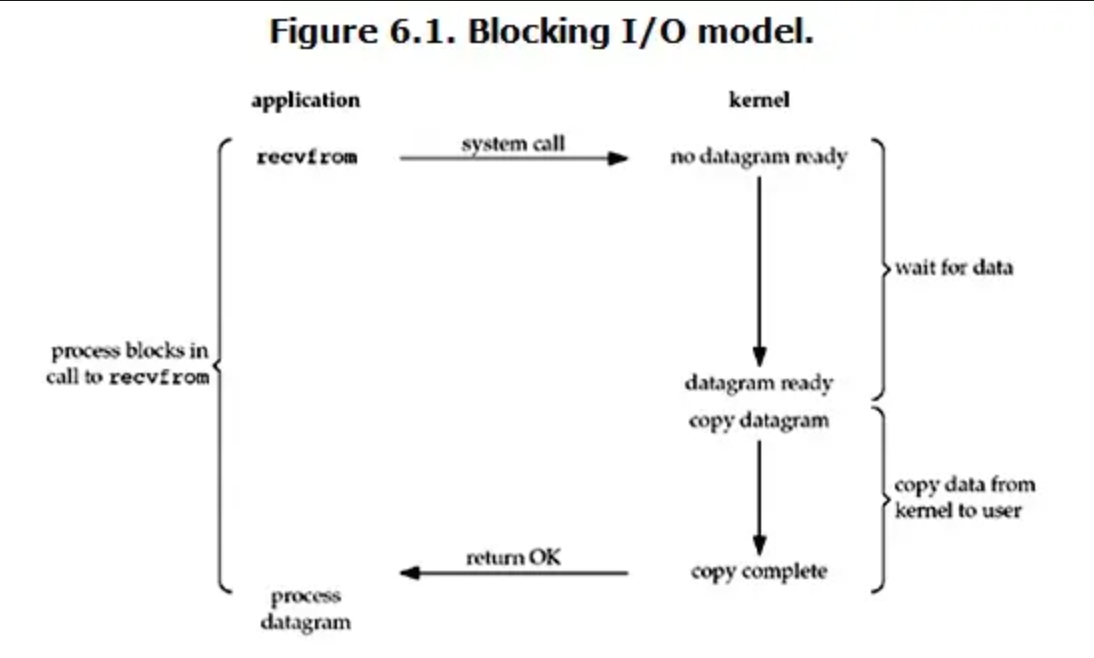
当用户进程调用了recvfrom这个系统调用,kernel就开始IO的第一个阶段:准备数据(对于网络IO来说,很多时候一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区是需要一个过程的。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
也就是说,阻塞IO的特点就是在IO执行的两个阶段都被block了。
非阻塞IO
linux下,可以通过设置socket使其变为non-blocking。当对于一个non-blocking socket 执行读操作时,流程大致如下:
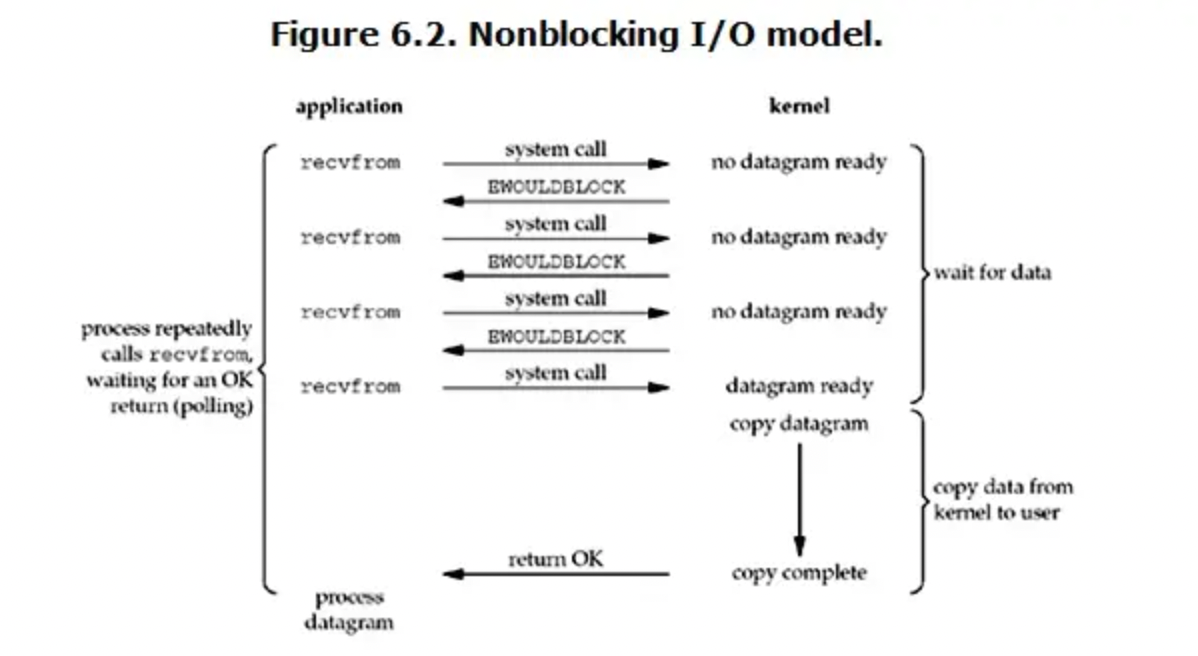
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
也就是说,非阻塞IO的特点是用户进行需要不断的主动询问kernel数据好了没有。
IO多路复用
IO多路复用就是我们通常说的select、poll、epoll,有些地方也称这种IO方式为event driven IO。
select/epoll的好处在于单个process就可以同时处理多个网络连接的IO。它的基本原来就是select、poll、epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
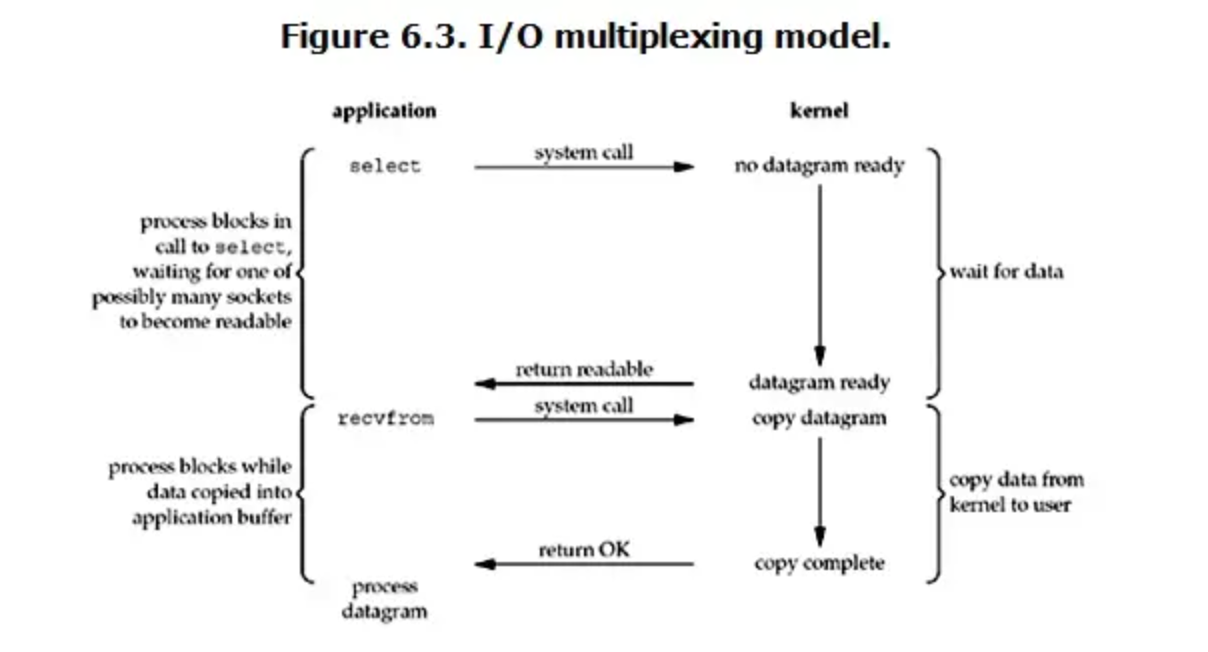
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
总结来看,IO多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
IO多路复用模型与阻塞IO其实并没有太大的区别,事实上,还更差一些。因为这里需要使用两个system call(select 和 recvfrom分别调用一次),而阻塞IO值调用了一次system call(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用mutli-threading+blocking的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
在IO多路复用模型中,一般会将socket都设置为非阻塞,但是用户进程会被select函数阻塞。
异步IO
Linux下的异步IO其实用的很少,整体流程大致如下:

用户进程发起read操作之后,立刻就可以开始去做其它的事,而另一方面,从kernel的角度,当它收到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
阻塞、非阻塞和同步、异步
阻塞、非阻塞说的是调用者。同步、异步说的是被调用者。
同步IO和异步IO的区别:
- 同步IO:真实IO 操作的时候会将process阻塞
- 异步IO:真实IO 操作的时候不会将process阻塞
按照如上定义,阻塞IO、非阻塞IO、IO多路复用均属于同步IO。
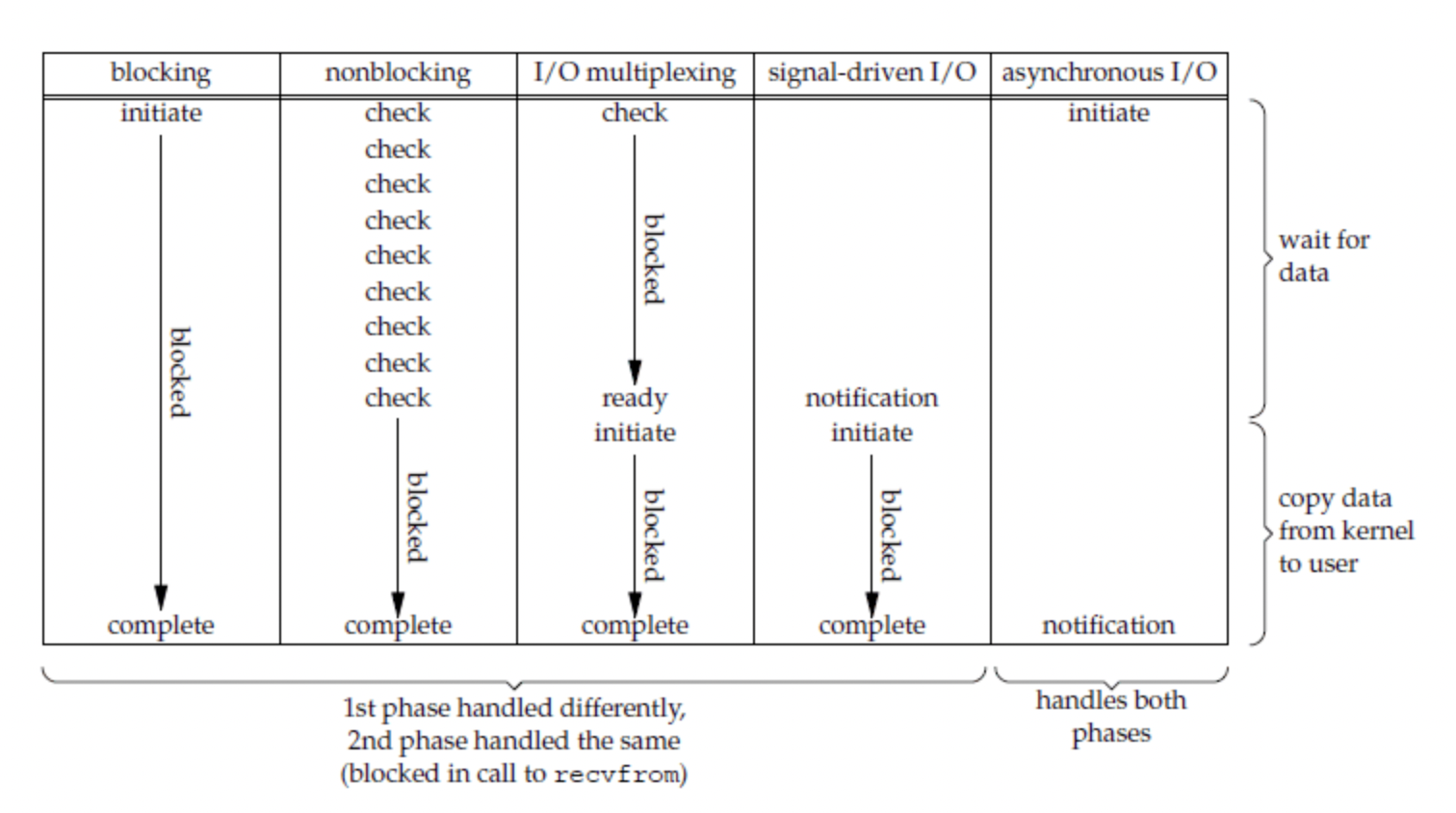
五种线程模型对比:
IO多路复用之select、poll、epoll
select、poll和epoll都是IO多路复用的机制。IO多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select、poll、epoll本质上都是同步IO,因为它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步IO则无需自己负责进行读写,异步IO的实现会负责把数据从内核拷贝到用户空间。
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select函数监视的文件描述符分为3类,分别是readfds、writefds和exceptfds。调用select函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同于select使用三个位图来表示三个fdset的方式,poll使用一个pollfd的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时pollfd并没有最大数量限制(但是数量过大后性能也会下降)。和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。实际上,同时连接的大量客户端在同一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线程下降。
epoll
epoll是在Linux内核2.6版本中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的时间存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需要一次。
Java中的IO模型
在JDK1.4之前,基于Java的所有socket通信都使用了同步阻塞模式(bloking IO),这种一请求一应答的通信模型简化了上层开发,但性能可能性存在巨大瓶颈,对高并发和低时延支持不好。
在JDK1.4之后,提供了新的NIO类库,Java开始支持非阻塞IO。在JDK1.7以后,将原来的NIO类库进行了升级,提供了AIO功能,支持基于文件的异步IO操作和针对套接字的异步IO操作等功能。
JDK1.7之后,将原来的NIO类库进行了升级,提供了AIO功能,支持基于文件的异步IO操作和针对套接字的异步IO操作等功能。
BIO
使用BIO通信模型的服务端,通常通过一个独立的Acceptor线程负责监听客户端的连接,监听到客户端连接请求后为每一个客户端创建一个新的线程链路进行处理,处理完成通过输出流回应客户端,线程消耗,这就是典型一对一答模型,下面我们通过代码对BIO模型进行具体分析,我们实现客户端发送消息服务端将消息回传我们的功能。
服务端:
int port = 3000;
try(ServerSocket serverSocket = new ServerSocket(port)) {
Socket socket = null;
while (true) {
//主程序阻塞在accept操作上
socket = serverSocket.accept();
new Thread(new BioExampleServerHandle(socket)).start();
}
} catch (Exception e) {
e.printStackTrace();
}
private Socket socket;
public BioExampleServerHandle(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try(BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter writer = new PrintWriter(socket.getOutputStream(), true)) {
String message = reader.readLine();
System.out.println("收到客户端消息:" + message);
writer.println("answer: " + message);
} catch (Exception e) {
e.printStackTrace();
}
}
客户端:
String host = "127.0.0.1";
int port = 3000;
try(Socket socket = new Socket(host, port);
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter writer = new PrintWriter(socket.getOutputStream(), true)) {
Scanner input = new Scanner(System.in);
System.out.println("输入你想说的话:");
String message = input.nextLine();
writer.println(message);
String answer = reader.readLine();
System.out.println(answer);
} catch (Exception e) {
e.printStackTrace();
}
通过代码我们可以发现BIO的主要问题在于,每当一个连接接入时我们都需要new一个线程进行处理,这显然是不合适的,因为一个线程功能只能处理一个连接,这显然是不合适的,因为一个线程只能处理一个连接,如果在高并发的情况下,我们的程序肯定无法满足性能需求,同时我们对线程创建也缺乏管理。为了改进这种模型我们可以通过消息队列和线程池技术对它加以优化,我们称它为伪异步IO,代码如下:
int port = 3000;
ThreadPoolExecutor socketPool = null;
try(ServerSocket serverSocket = new ServerSocket(port)) {
Socket socket = null;
int cpuNum = Runtime.getRuntime().availableProcessors();
socketPool = new ThreadPoolExecutor(cpuNum, cpuNum * 2, 1000,
TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(1000));
while (true) {
socket = serverSocket.accept();
socketPool.submit(new BioExampleServerHandle(socket));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
socketPool.shutdown();
}
可以看到每当有新的连接接入,我们都将他投递给线程池处理,由于我们设置了线程池大小和阻塞队列大小,因此在并发情况下都不会导致服务崩溃,但是如果并发数大于阻塞队列大小,或服务端处理连接缓慢时,阻塞队列无法继续处理,会导致客户端连接超时,影响用户体验。
NIO
NIO弥补了同步阻塞IO的不足,它提供了高速、面向块的IO,NIO中的一些概念:
- Buffer:Buffer用于和NIO通道进行交互。数据从通道读入缓冲区,从缓冲区写入到通道中,它的主要作用就是和channel进行交互
- Channel:Channel是一个通道,可以通过它读取和写入数据,通道是双向的,通道可以用户读、写或者同时读写
- Selector:Selector会不断的轮询注册在它上面的Channel,如果Channel上面有新的连接读写事件的时候就会被轮询出来,一个Selector可以注册多个Channel,只需要一个线程负责Selector轮询,就可以支持成千上万的连接,可以说为高并发服务器的开发提供了很好的支撑
服务端:
int port = 3000;
ServerSocketChannel socketChannel = null;
Selector selector = null;
try {
selector = Selector.open();
socketChannel = ServerSocketChannel.open();
//设置连接模式为非阻塞模式
socketChannel.configureBlocking(false);
socketChannel.socket().bind(new InetSocketAddress(port));
//在selector上注册通道,监听连接事件
socketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
//设置selector 每隔一秒扫描所有channel
selector.select(1000);
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterable = selectionKeys.iterator();
SelectionKey key = null;
while (iterable.hasNext()) {
key = iterable.next();
//对key进行处理
try {
handlerKey(key, selector);
} catch (Exception e) {
if (null != key) {
key.cancel();
if (null != key.channel()) {
key.channel().close();
}
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != selector) {
selector.close();
}
if (null != socketChannel) {
socketChannel.close();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
handlerKey代码如下:
private void handlerKey(SelectionKey key, Selector selector) throws IOException {
if (key.isValid()) {
//判断是否是连接请求,对所有连接请求进行处理
if (key.isAcceptable()) {
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel();
SocketChannel channel = serverSocketChannel.accept();
channel.configureBlocking(false);
//在selector上注册通道,监听读事件
channel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
//分配一个1024字节的缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
int readBytes = channel.read(byteBuffer);
if (readBytes > 0) {
//从写模式切换到读模式
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
byteBuffer.get(bytes);
String message = new String(bytes, "UTF-8");
System.out.println("收到客户端消息: " + message);
//回复客户端
message = "answer: " + message;
byte[] responseByte = message.getBytes();
ByteBuffer writeBuffer = ByteBuffer.allocate(responseByte.length);
writeBuffer.put(responseByte);
writeBuffer.flip();
channel.write(writeBuffer);
}
}
}
}
客户端代码:
int port = 3000;
String host = "127.0.0.1";
SocketChannel channel = null;
Selector selector = null;
try {
selector = Selector.open();
channel = SocketChannel.open();
channel.configureBlocking(false);
if (channel.connect(new InetSocketAddress(host, port))) {
channel.register(selector, SelectionKey.OP_READ);
write(channel);
} else {
channel.register(selector, SelectionKey.OP_CONNECT);
}
while (true) {
selector.select(1000);
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
SelectionKey key = null;
while (iterator.hasNext()) {
try {
key = iterator.next();
handle(key, selector);
} catch (Exception e) {
e.printStackTrace();
if (null != key.channel()) {
key.channel().close();
}
if (null != key) {
key.cancel();
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != channel) {
channel.close();
}
if (null != selector) {
selector.close();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
write 方法:
private void write(SocketChannel channel) throws IOException {
Scanner in = new Scanner(System.in);
System.out.println("输入你想说的话:");
String message = in.next();
byte[] bytes = message.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(bytes.length);
byteBuffer.put(bytes);
byteBuffer.flip();
channel.write(byteBuffer);
}
handle 方法:
private void handle(SelectionKey key, Selector selector) throws IOException {
if (key.isValid()) {
SocketChannel channel = (SocketChannel) key.channel();
if (key.isConnectable()) {
if (channel.finishConnect()) {
channel.register(selector, SelectionKey.OP_READ);
write(channel);
}
} else if (key.isReadable()) {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
int readBytes = channel.read(byteBuffer);
if (readBytes > 0) {
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
byteBuffer.get(bytes);
String message = new String(bytes, "UTF-8");
System.out.println(message);
} else if (readBytes < 0) {
key.cancel();
channel.close();
}
}
}
}
通过代码我们会发现,NIO比BIO复杂很多。NIO虽然编码复杂,但优势同样明显,比起BIO客户端连接操作时异步的,我们可以注册OP_CONNET事件等待结果而不用像BIO那样被同步阻塞,Channel的读写操作都是异步的,没有等待数据它不会等待,而是直接返回。比起BIO我们不需要频繁的创建线程来处理客户端连接,而是通过一个Selector处理多个客户端连接,而且性能也可以得到保证,适合做高性能服务器开发。
AIO
通过对比,AIO要比BIO简单,这是因为我们不需要创建一个独立的IO线程来处理读写操作,AsynchronousSocketchannel、AsynchronousServerSocketChannel由JDK底层线程池负责回调驱动读写操作。
服务端:
int port = 3000;
AsynchronousServerSocketChannel socketChannel = null;
try {
socketChannel = AsynchronousServerSocketChannel.open();
socketChannel.bind(new InetSocketAddress(port));
//接收客户端连接,传入AcceptCompletionHandler作为回调来接收连接消息
socketChannel.accept(socketChannel, new AcceptCompletionHandler());
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != socketChannel) {
socketChannel.close();
}
} catch (Exception e1) {
throw new RuntimeException(e1);
}
}
AcceptCompletionHandler 类:
public class AcceptCompletionHandler implements CompletionHandler<AsynchronousSocketChannel, AsynchronousServerSocketChannel> {
@Override
public void completed(AsynchronousSocketChannel result, AsynchronousServerSocketChannel attachment) {
//继续接受其他客户端的连接请求,形成一个循环
attachment.accept(attachment, this);
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
//调用read操作进行异步读取操作,传入ReadCompletionHandler作为回调
result.read(byteBuffer, byteBuffer, new ReadCompletionHandler(result));
}
@Override
public void failed(Throwable exc, AsynchronousServerSocketChannel attachment) {
//异常失败处理在这里
}
}
ReadCompletionHandler 类
public class ReadCompletionHandler implements CompletionHandler<Integer, ByteBuffer> {
private AsynchronousSocketChannel channel;
public ReadCompletionHandler(AsynchronousSocketChannel channel) {
this.channel = channel;
}
@Override
public void completed(Integer result, ByteBuffer byteBuffer) {
try {
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
byteBuffer.get(bytes);
String message = new String(bytes, "UTF-8");
System.out.println("收到客户端消息:: " + message);
write(message);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
try {
channel.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private void write(String message) {
message = "answer: " + message;
byte[] bytes = message.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(bytes.length);
byteBuffer.put(bytes);
byteBuffer.flip();
channel.write(byteBuffer, byteBuffer, new WriteCompletionHandler(channel));
}
}
客户端:
int port = 3000;
String host = "127.0.0.1";
AsynchronousSocketChannel channel = null;
try {
channel = AsynchronousSocketChannel.open();
channel.connect(new InetSocketAddress(host, port), channel, new AioClientHandler());
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != channel) {
channel.close();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
AioClientHandler 类(由于客户端比较简单我这里使用了嵌套类部类):
public class AioClientHandler implements CompletionHandler<Void, AsynchronousSocketChannel> {
@Override
public void completed(Void result, AsynchronousSocketChannel channel) {
Scanner in = new Scanner(System.in);
System.out.println("输入你想说的话:");
String message = in.next();
byte[] bytes = message.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(bytes.length);
byteBuffer.put(bytes);
byteBuffer.flip();
channel.write(byteBuffer, byteBuffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
//判断是否写完如果没有继续写
if (buffer.hasRemaining()) {
channel.write(buffer, buffer, this);
} else {
ByteBuffer readBuffer = ByteBuffer.allocate(1024);
channel.read(readBuffer, readBuffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
try {
attachment.flip();
byte[] bytes1 = new byte[attachment.remaining()];
attachment.get(bytes1);
String message = new String(bytes1, "UTF-8");
System.out.println(message);
System.exit(1);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
try {
channel.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
});
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
try {
channel.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
});
}
@Override
public void failed(Throwable exc, AsynchronousSocketChannel attachment) {
}
IO模型对比
| 同步阻塞I/O(BIO) | 伪异步I/O | 非阻塞I/O(NIO) | 异步I/O(AIO) | |
|---|---|---|---|---|
| 是否阻塞 | 是 | 是 | 否 | 否 |
| 是否同步 | 是 | 是 | 是 | 否(异步) |
| 程序员友好程度 | 简单 | 简单 | 非常难 | 比较难 |
| 可靠性 | 非常差 | 差 | 高 | 高 |
| 吞吐量 | 低 | 中 | 高 | 高 |
零拷贝
零拷贝从字面上来看包含两个意思:
- 拷贝:就是指数据从一个存储区域转移到另一个存储区域
- 零:它表示拷贝数据的次数为0
合起来理解,零拷贝就是不需要将数据从一个存储区域复制到另一个存储区域。实际上,最早零拷贝的定义,来源于Linux系统的sendfile方法逻辑。
在Linux 2.4内核中,sendfile系统调用方法,可以将磁盘数据通过DMA拷贝到内核态Buffer后,再通过DMA拷贝到NIC Buffer(socket buffer 即网卡),无需CPU拷贝,这个过程被称之为零拷贝。也就是说,站在操作系统的角度,零拷贝并不是不需要拷贝数据,而是省掉了CPU拷贝环节,减少了不必要的拷贝次数,提升数据拷贝效率。要想深入了解这其中的原理,就得从IO拷贝机制说起。
基本概念
DMA
DMA,即直接内存访问。DMA本质上是主板上一块独立的芯片,允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与。
内核空间和用户空间
操作系统的核心是内核,与普通的应用程序不同,它可以访问受保护的内核空间,也有访问底层硬件设备的权限。
为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两个部分,一部分是内核空间,一部分是用户空间。在Linux系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
内核空间总是驻留在内存中,它是为操作系统的内核保留的。应用程序是不允许直接在该区域进行读写或者直接调用内核代码定义的函数。
当启动某个应用程序时,操作系统会给应用程序分配一个单独的用户空间,其实就是一个用户独享的虚拟内存,每个普通的用户进程之间的用户空间是完全隔离的、不共享的,当用户进程结束的时候,用户空间的虚拟内存也会随之释放。
同时处于用户态的进程不能访问内核空间中的数据,也不能直接调用内核函数的,如果要调用系统资源,就要将进程切换到内核态,由内核程序来进行操作。
IO拷贝机制
以客户端从服务器下载文件为例,服务端需要做两件事:
- 从磁盘读取文件内容
- 将文件内容通过网络传输给客户端
实际上,这个看似简单的操作,里面的流程却没有那么简单,应用程序从磁盘中读取文件内容的操作,大体会经过以下几个流程:
- 用户应用程序调用read方法,向操作系统发起IO请求,CPU上下文从用户态转为内核态,完成第一次CPU切换
- 操作系统通过DMA控制器从磁盘中读取数据,并把数据存储到内核缓冲区
- CPU把内核缓冲区的数据,拷贝到用户缓冲区,同时上下文从内核态转为用户态,完成第二次CPU切换
整个读取的数据的过程,完成了1次DMA拷贝,1次CPU拷贝,2次CPU切换,反之写入的过程,也是一样的。整个拷贝的过程,可以用如下流程图来描述:
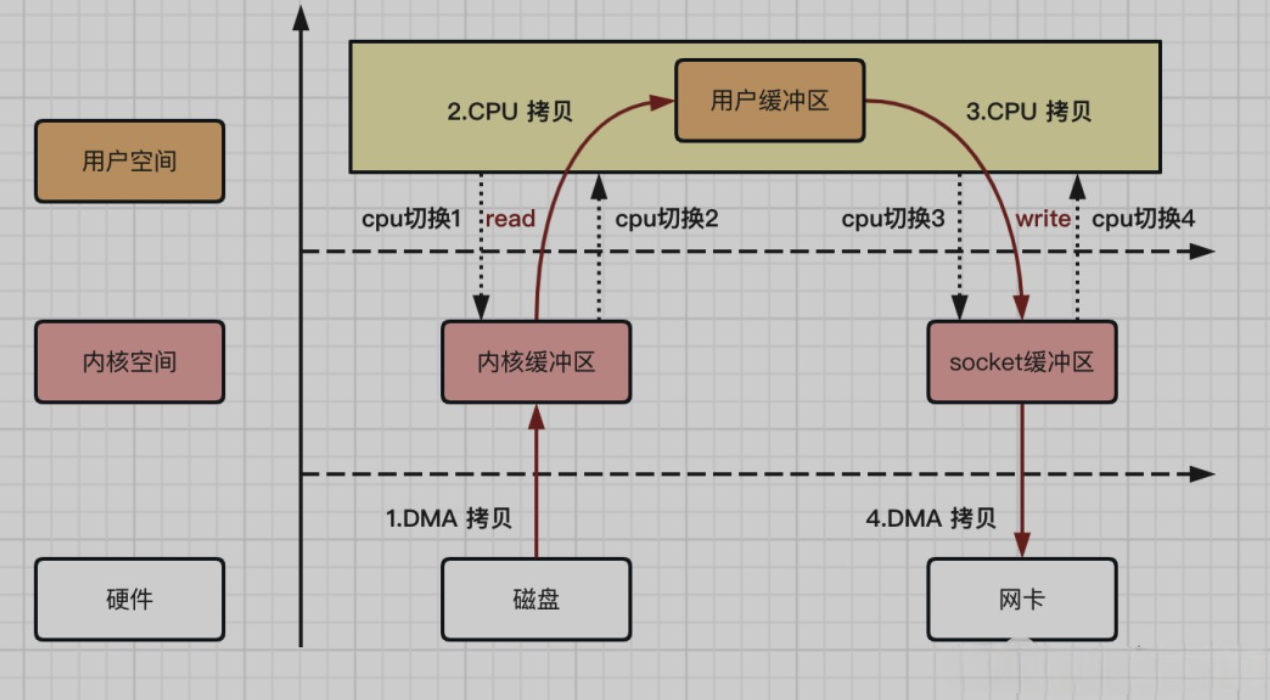
从上图,我们可以得出如下结论,4次拷贝次数,4次上下文切换次数。
- 数据拷贝次数:2次DMA拷贝,2次CPU拷贝
- CPU切换次数:4次用户态和内核态切换
而实际IO读写,有时候需要进行IO中断,同时也需要CPU响应中断,拷贝次数和切换次数比预期的还要多,以至于当客户端进行资源文件下载的时候,传输速度总是不尽人意。
mmap内存映射拷贝流程
mmap内存映射的拷贝,指的是将用户应用程序的缓冲区和操作系统的内核缓冲区进行映射处理,数据在内核缓冲区和用户缓冲区之间的CPU拷贝将其省略,进而加快资源拷贝效率。
mmap内存映射拷贝流程:
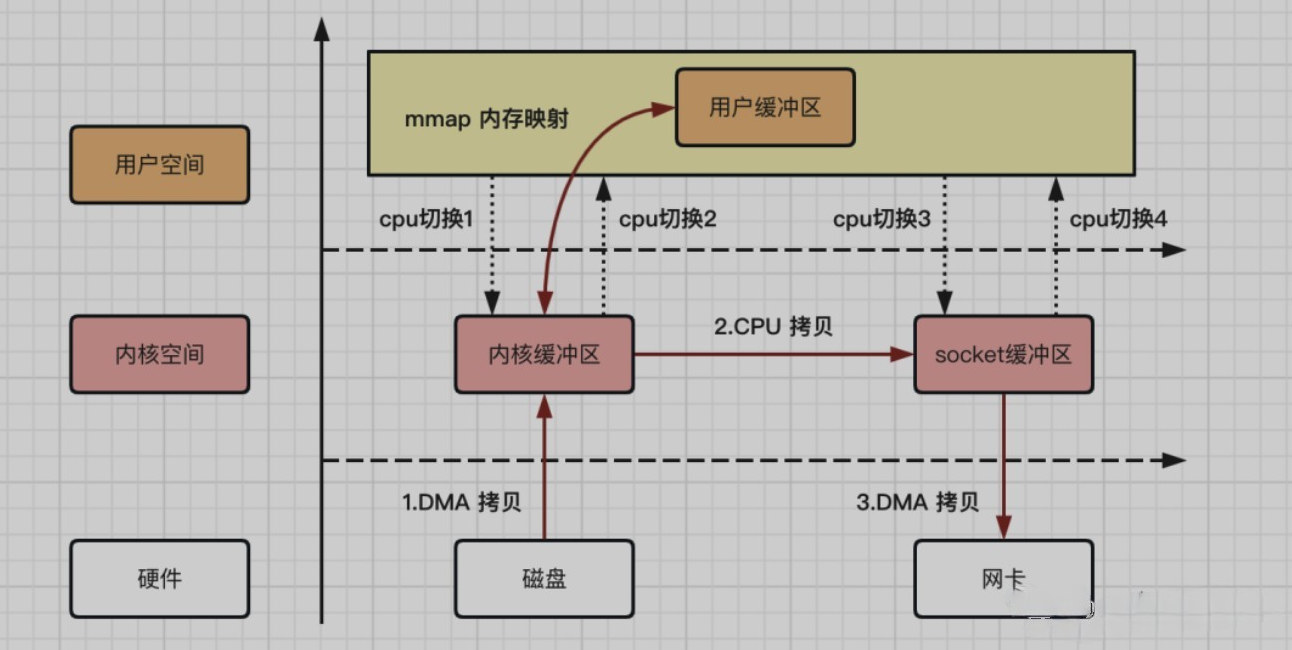
- 数据拷贝次数:2次DMA拷贝,1次CPU拷贝
- CPU切换次数:4次用户态和内核态的切换
整个过程省掉了数据在内核缓冲区和用户缓冲区之间的CPU拷贝环节,在实际的应用中,对资源的拷贝速度性能提升不少。
Linux系统sendfile拷贝流程
在Linux 2.1 内核版本中,引入了一个系统调用方法:sendfile。
当调用sendfile()时,DMA将磁盘数据复制到内核缓冲区kernel buffer;然后将内核中kernel buffer直接拷贝到socket buffer,最后利用DMA将socket buffer通过网卡传输给客户端。整个拷贝过程,可以用如下流程图来描述:
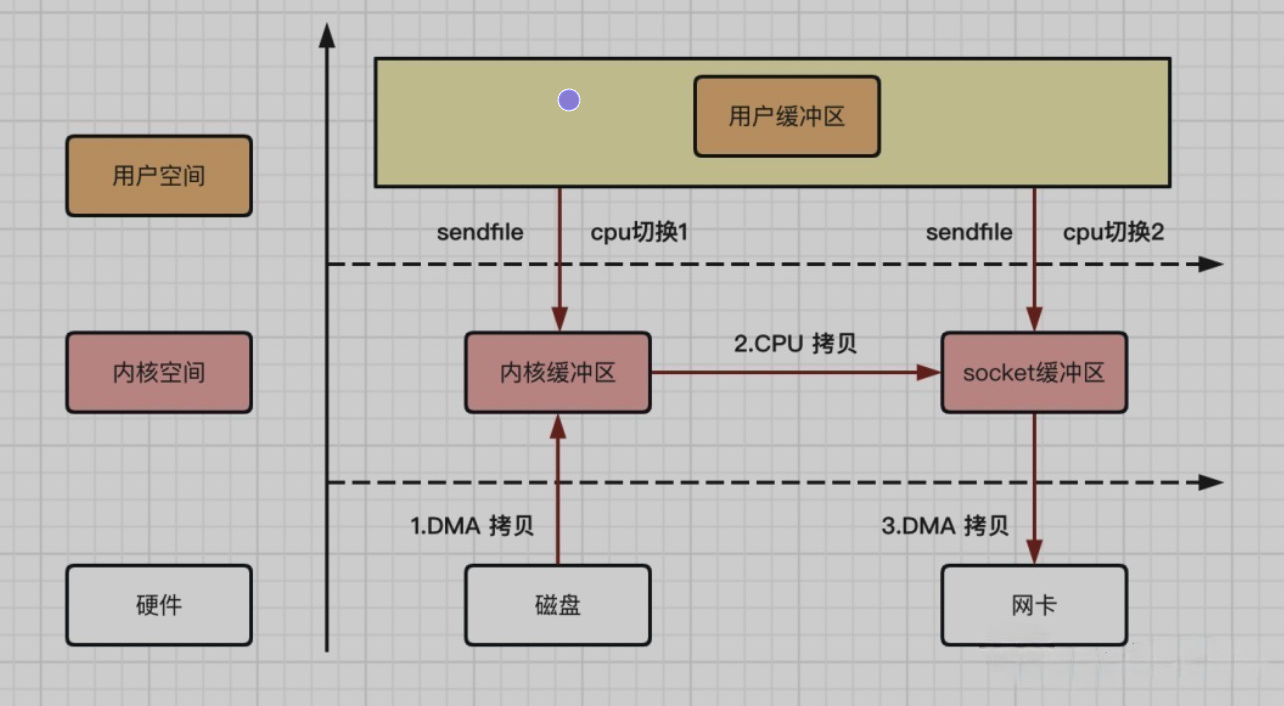
Linux 系统 sendfile 拷贝流程:
- 数据拷贝次数:2 次 DMA 拷贝,1 次 CPU 拷贝
- CPU 切换次数:2 次用户态和内核态的切换
相比mmap内存映射方式,sendfile拷贝流程省掉了2次用户态和内核态的切换,同时内核缓冲区和用户缓冲区也无需建立内存映射,对资源的拷贝性能提升不少。
sendfile With DMA scatter/gather 拷贝流程
在 Linux 2.4 内核版本中,对 sendfile 系统方法做了优化升级,引入 SG-DMA 技术,需要 DMA 控制器支持。
其实就是对 DMA 拷贝加入了 scatter/gather 操作,它可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点来实现数据拷贝,可以多省去一次 CPU 拷贝。
整个拷贝过程,可以用如下流程图来描述:
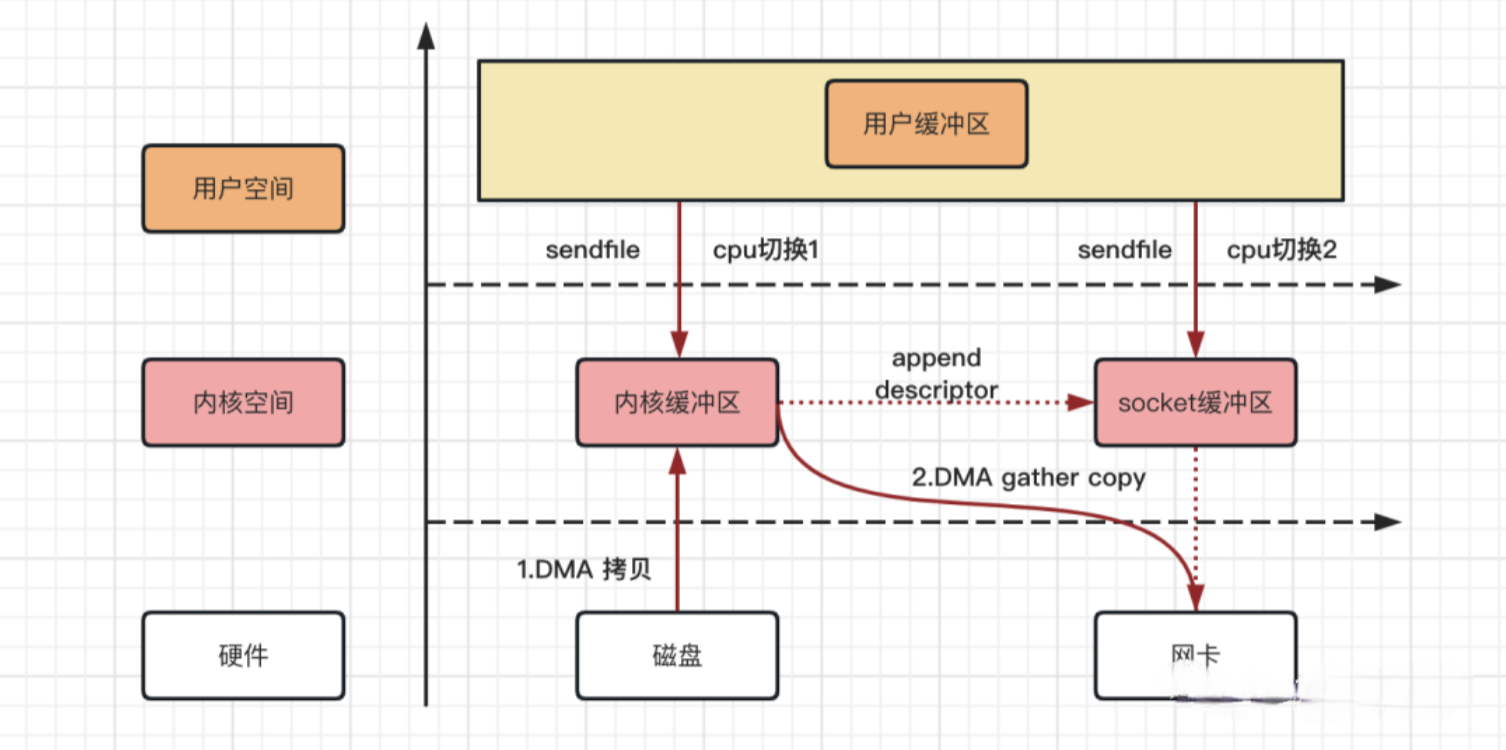
Linux 系统 sendfile With DMA scatter/gather 拷贝流程,从上图可以得出如下结论:
- 数据拷贝次数:2 次 DMA 拷贝,0 次 CPU 拷贝
- CPU 切换次数:2 次用户态和内核态的切换
可以发现,sendfile With DMA scatter/gather 实现的拷贝,其中 2 次数据拷贝都是 DMA 拷贝,全程都没有通过 CPU 来拷贝数据,所有的数据都是通过 DMA 来进行传输的,这就是操作系统真正意义上的零拷贝(Zero-copy) 技术,相比其他拷贝方式,传输效率最佳。
Linux 系统 splice 零拷贝流程
在 Linux 2.6.17 内核版本中,引入了 splice 系统调用方法,和 sendfile 方法不同的是,splice 不需要硬件支持。
它将数据从磁盘读取到 OS 内核缓冲区后,内核缓冲区和 socket 缓冲区之间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
整个拷贝过程,可以用如下流程图来描述:
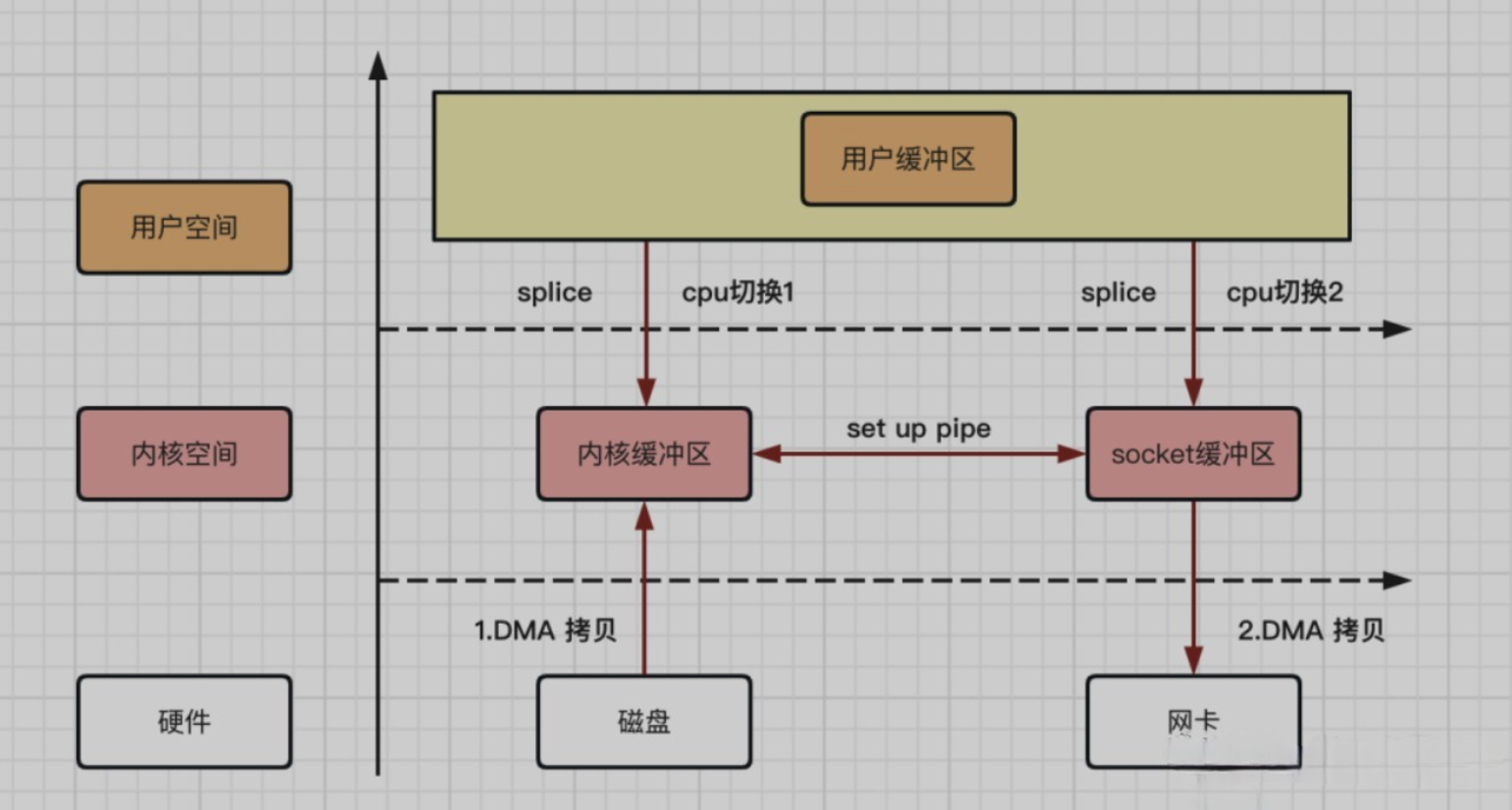
Linux 系统 splice 拷贝流程,从上图可以得出如下结论:
- 数据拷贝次数:2 次 DMA 拷贝,0 次 CPU 拷贝
- CPU 切换次数:2 次用户态和内核态的切换
Linux 系统 splice 方法逻辑拷贝,也是操作系统真正意义上的零拷贝。
IO拷贝机制对比
从上面的IO拷贝机制中可以看出,无论是传统的IO方式,还是引入零拷贝之后,2次DMA copy都是少不了的,唯一的区别就是省掉CPU参与环节的方式不同。
以Linux系统为例,拷贝机制对比的结果如下:
| 拷贝机制 | 系统调用 | CPU拷贝次数 | CPU拷贝次数 | 上下文切换次数 | 特点 |
|---|---|---|---|---|---|
| 传统拷贝方式 | read/write | 2 | 2 | 4 | 消耗资源比较多,拷贝数据效率慢 |
| mmap | mmap/write | 1 | 2 | 4 | 相比传统方法,少了用户缓冲区与内核缓冲区的数据拷贝,效率更高 |
| sendfile | sendfile | 1 | 2 | 2 | 相比mmap方式,少了内存文件映射步骤,效率更高 |
| sendfile With DMA scatter/gather | sendfile | 0 | 2 | 2 | 需要DMA控制器支持,没有CPU拷贝数据环节,真正的零拷贝 |
| splice | splice | 0 | 2 | 2 | 没有CPU拷贝数据环节,真正的零拷贝,编程逻辑复杂 |
需要主要的是,零拷贝所有的方式,都需要操作系统的支持,具体采用哪种方式,是由操作系统来决定的。
Java中的零拷贝
Linux提供的零拷贝技术,Java并不是全部支持,目前只支持一下两种;
- mmap(内存映射)
- sendfile
Java NIO 对mmap的支持
Java NIO有一个MappedByteBuffer的类,可以用来实现内存映射,它的底层时调用了Linux内核的mmap的API。
实现代码如下:
public static void main(String[] args) {
try {
FileChannel readChannel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
// 建立内存文件映射
MappedByteBuffer data = readChannel.map(FileChannel.MapMode.READ_ONLY, 0, 1024 * 1024 * 40);
FileChannel writeChannel = FileChannel.open(Paths.get("b.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
// 拷贝数据
writeChannel.write(data);
// 关闭通道
readChannel.close();
writeChannel.close();
}catch (Exception e){
System.out.println(e.getMessage());
}
}
其中MappedByteBuffer的作用,就是将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射,读取小文件,效率并不高,但是读取大文件,效率很高。
Java NIO 对sendfile的支持
Java NIO 中的FileChannel.transferTo方法,底层调用的就是Linux内核的sendfile系统调用方法。实例代码如下:
public static void main(String[] args) {
try {
// 原始文件
FileChannel srcChannel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
// 目标文件
FileChannel destChannel = FileChannel.open(Paths.get("b.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
// 拷贝数据
srcChannel.transferTo(0, srcChannel.size(), destChannel);
// 关闭通道
srcChannel.close();
destChannel.close();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
Java NIO 提供的FileChannel.transferTo并不保证一定能使用零拷贝。只有操作系统提供sendfile这样的零拷贝系统调用方法,才可以用的上零拷贝。