
RocketMQ是一个分布式消息和流数据平台,具有低延迟、高性能、高可靠性、万亿级容量和灵活的可扩展性。RcoketMQ是2012年阿里巴巴开源的第三代分布式消息中间,2017年2月20日,Apache软件基金会宣布Apache RocketMQ成为顶级项目。
概念和特性
概念
消息模型
RocketMQ主要由Producer、Broker、Consumer三部分组成,其中Producer负责生产消息,Consumer负责消费消息,Broker负责存储消息,Broker在实际部署过程中对应一台服务器,每个Broker可以存储多个Topic的消息,每个Topic的消息也可以分片存储于不同的Broker。Message Queue用于存储消息的物理地址,每个Topic中的消息地址存储于多个Message Queue中。ConsumerGroup由多个Consumer实例构成。
生产者组
同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。
消费者组
同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错变的容易。特别需要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。
一个生产者可以同时发送多种Topic消息;而一个消费者只对某种特定的Topic感兴趣,即只可以订阅和消费一种Topic消息。
集群消费
集群消费模式下,相同的Consumer Group的每个Consumer实例平均分摊消息。
广播消息
广播消费模式下,相同的Consumer Group的每个Consumer实例都接收全量的消息。
标签
为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
队列
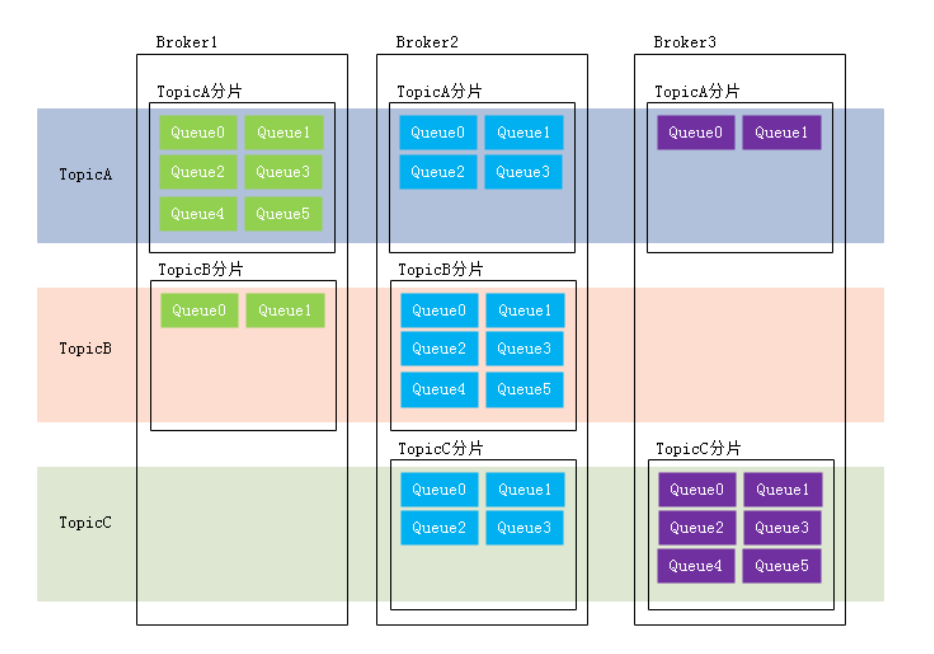
队列是存储消息的物理实体。一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
一个Topic的Queue中的消息只能被一个消费者组中的一个消费者消费。一个Queue中的消息不允许同一个消费者组中的多个消费者同时消费。
与分区相关的还有一个概念:分片(Sharding)。分片不同于分区。在RocketMQ中,分片指的是存放相同Topic的Broker。每个分片中会创建相应数量的分区,即Queue,每个Queue的大小都是相同的。
协议
常见MQ的实现都遵循一些常规性的协议,例如:JMS、STOMP、AMQP、MQTT,它们的具体含义如下:
- JMS(Java Messaging Service即Java消息服务),是Java平台上有关MOM(Message Oriented Middleware,面向消息的中间件PO/OO/AO)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口,简化企业应用的开发,ActiveMQ是该协议的典型实现
- STOMP(Streaming Text Oriented Message Protocol即面向流文本的消息协议),是一种MOM设计的简单文本协议,STOMP提供一个可互操作的连接格式,允许客户端与任意STOMP消息代理(Broker)进行交互。ActiveMQ是该协议的典型实现,RabbitMQ通过插件可以支持该协议
- AMQP(Advanced Message Queuing Protocol即高级消息队列协议),一个提供统一消息服务的应用层便准,是应用层协议的一个开放标准,是一种MOM设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同开发语言等条件的限制。RabbitMQ是该协议的典型实现
- MQTT(Message Queuing Telemetry Transport即消息队列遥测传输),是IBM开发的一个即时通讯协议,是一种二进制协议,主要用于服务器和低功耗IOT(物联网)设备间的通信。该协议支持所有平台,几乎可以把所有物联网物品和外部连接起来,被用来当作传感器和致动器的通信协议。RabbitMQ通过插件可以支持该协议
特性
消息顺序
消息有序指的是一类消息消费时,能按照发送来的顺序来消费。例如:一个订单产生了三条消息分别是订单创建、订单付款、订单完成。消费要按照这个顺序消费才能有意义,但是同时订单之间是可以并行消费的。
顺序消息分为全局顺序消息与分区顺序消息,全局顺序是指某个Topic下所有的消息都要保证顺序;部分顺序消息只要保证每一组消息被顺序消费即可。
- 全局顺序是指对于指定的一个Topic,所有消息按照严格的先入先出的顺序发布和消费,适用于性能要求不高,所有的消息严格按照FIFO原则进行消息发布和消费的场景
- 分区顺序对于指定一个Topic,所有的消息根据sharding key进行区块分区。同一个分区内的消息按照严格的FIFO顺序进行发布和消费
消息重试
Consumer消费消息失败后,要提供一种重试机制,让消息再消费一次。Consumer消费消息失败通常可以认为有以下几种情况:
- 由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消息的手机号被注销,无法充值)等。这种错误通常需要跳过这条消息,再消费其它消息,而这条失败的消息即使立刻重试消息,也大概率不会成功,所以最好提供一种定时重试机制,即过10秒后再重试
- 由于依赖的下游应用服务不可用,例如db连接不可用,外系统网络不可达等。遇到这种错误,即使跳过当前失败的消息,消费其它消息同样也会报错。这种情况建议应用sleep 30s,再消费下一条消息,这样可以减轻Broker重试消息的压力
RocketMQ会为每个消费组都设置一个Topic名称为“%RETRY%+consumerGroup”的重试队列(这里需要注意的是,这个Topic的重试队列是针对消费组,而不是针对每个Topic设置的),用于暂时保存因为各种异常而导致Consumer端无法消费的消息。考虑到异常恢复起来需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ对于重试消息的处理是先保存至Topic名称为“SCHEDULE_TOPIC_XXXX”的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至“%RETRY%+consumerGroup”的重试队列中。
延迟队列
延迟队列(定时消息)是指消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic,broker有配置项messageDelayLevel,默认值为“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”,18个level。可以配置自定义messageDelayLevel。注意,messageDelayLevel是broker的属性,不属于某个topic。
死信队列
死信队列用于处理无法被正常消费的消息,当一条消息初次消费失败,消费队列会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
RocketMQ将这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),将存储死信消息的特殊队列称为死信队列(Dead Letter Queue)。在RocketMQ中,可以通过使用console控制台对死信队列中的消息进行重发来使得消费者实例再次进行消费。
架构和设计
技术架构
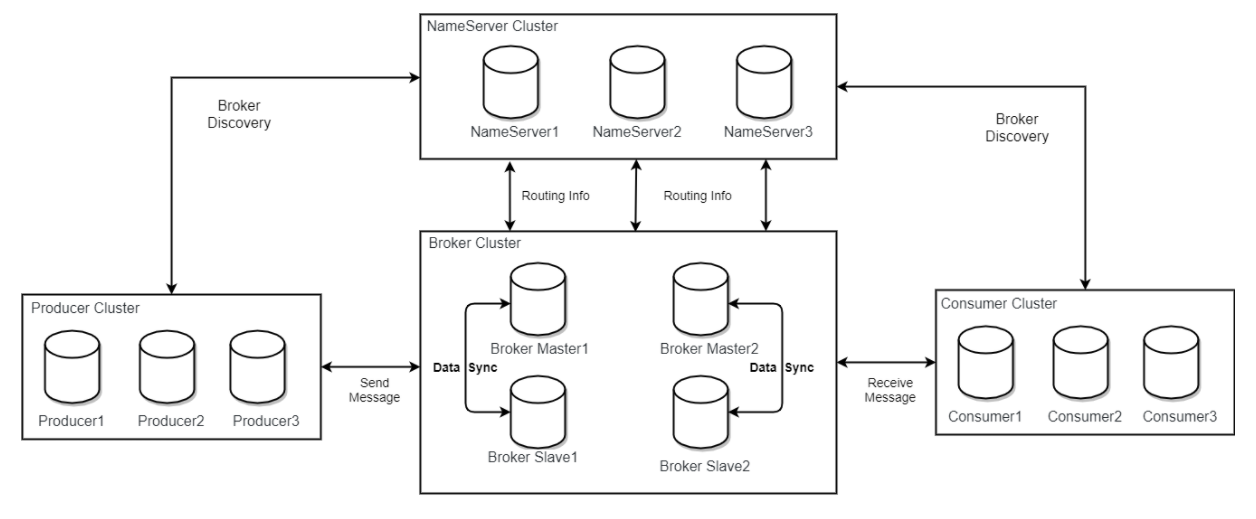
RocketMQ架构上主要分为四部分,如下图所示:
其中各个部分的详细作用:
Producer:消息发布的角色,支持分布式集群方式部署。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟
Consumer:消息消费的角色,支持分布式集群方式部署;支持以push、pull两种模块消费消息;同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求
NameServer:NameServer是一个非常简单的Topic路由注册中心,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。主要包括两个功能:
- Broker管理:NameServer接收Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活
- 路由信息管理:每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Consumer通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费
NameServer通常也是集群的方式部署,各实例间互相不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以动态感知Broker的路由信息
BrokerServer:Broker主要负责消息的存储、投递和查询以及服务高可用保证,为了实现这些功能,Broker包含了以下几个重要的子模块
集群工作流程
集合部署架构图,描述集群工作流程:
- 启动NameServer,NameServer起来后监听端口,等待Broker、Producer、Conusmer连接上来,相当于一个路由控制中心
- Broker启动,跟所有的NameServer保持长连接,定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系
- 收发消息前,先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic
- Producer发送消息,启动时先跟NamerServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,轮询从队列列表中选择一个队列,然后与队列所在的Broker建立长连接从而向Broker发消息
- Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息
架构设计
消息存储
消息存储整体架构
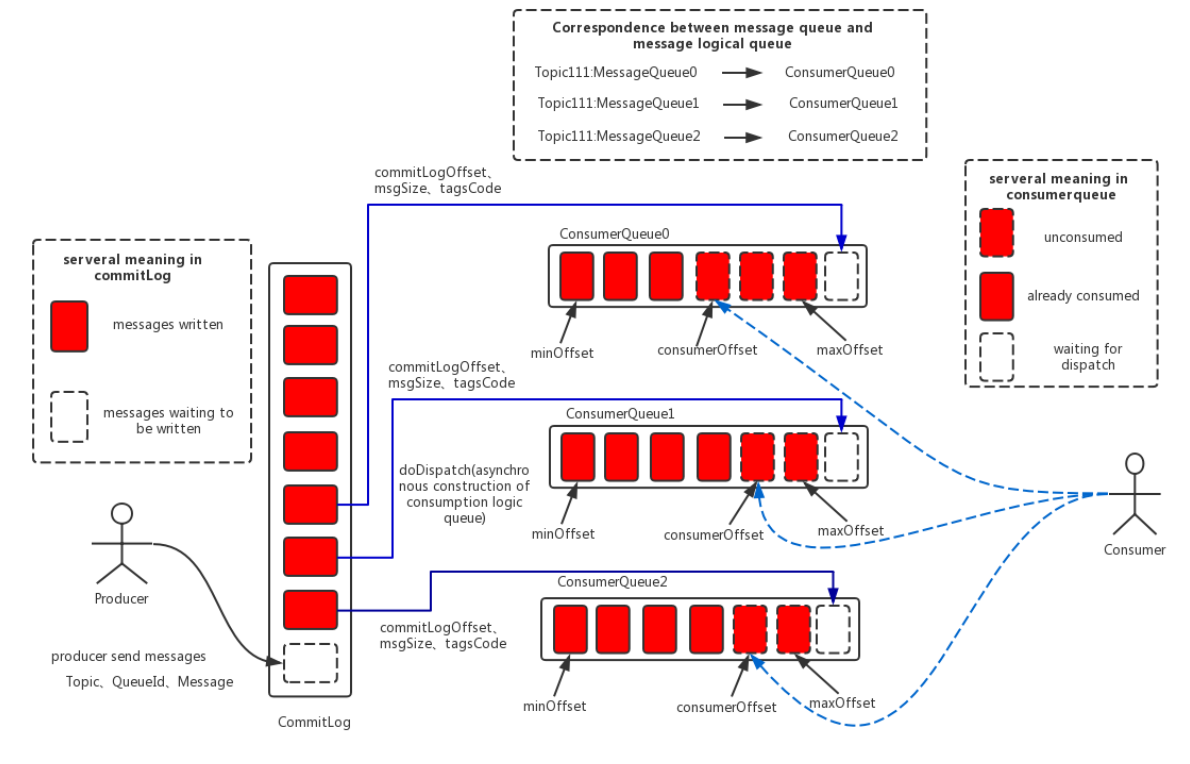
消息存储的架构中主要由三个部分构成:
- CommitLog:消息主体以及元数据的存储主体,存储Producer端写入的消息主题内容,消息内容不是定长的。单个文件大小默认1G,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;
- ConsumeQueue:消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历CommitLog文件中根据Topic检索消息是非常低效的。Conusmer即可根据ConsumerQueue来查找待消费的消息。其中,ConsumerQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。ConsumerQueue文件可以堪称是基于Topic的CommitLog索引文件,故ConsumerQueue文件夹的组织方式是:topic/queue/file三层组织结构,具体存储路径为:
$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样ConsumerQueue文件采取定长设计,每一个条目共20个字节,分别为8个字节的CommitLog物理偏移量,4字节的消息长度,8字节的tag hashcode,单个文件由30w个条目组成,可以像数组一样随机访问每一个条目,每个ConsumerQueue文件大小约5.72M; - IndexFile:IndexFile(索引文件)提供了一种可以通过key或者时间区间来查询消息的方法。Index文件的存储位置是:
$HOME \store\index${fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故RocketMQ的索引文件其底层实现为hash索引。
从以上RocketMQ的消息存储整体架构图可以看出,RocketMQ采用的是混合型的存储结构,即单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储。RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个CommitLog文件中)针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用或者异步的方式对消息刷盘持久化,保存至CommitLog中。只要消息被刷盘持久化至磁盘文件CommitLog中,那么Producer发送的消息就不会丢失。正因为如此,Consumer也就肯定有机会去消费这条消息。当无法拉取到消息后,可以等下一次消息拉取,同时服务端也支持长轮询模式,如果一个消息拉取请求未拉取到消息,Broker允许等待30s的时间,只要这段时间内有新消息到达,将直接返回给消费端。这里,RocketMQ的具体做法是,使用Broker端的后台服务线程——ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
页缓存与内存映射
页缓存(PageCache)是OS对文件地缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。对于数据的读写,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其它相邻块的数据文件进行预读取。
在RocketMQ中,ConsumeQueue逻辑消费队列存储的数据较少,并且是顺序读取,在PageCache机制的预读取作用下,ConsumeQueue文件的读性能几乎接近内存,即使在有消息堆积的情况下也不会影响性能,而对于CommitLog消息存储的日志数据来说,读取消息内容的时候会产生较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,比如设置调度算法为“Deadline”(此时块存储采用SSD的话),随机读的性能也会有所提升。
另外,RocketMQ主要通过MappedByteBuffer对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。
消息刷盘
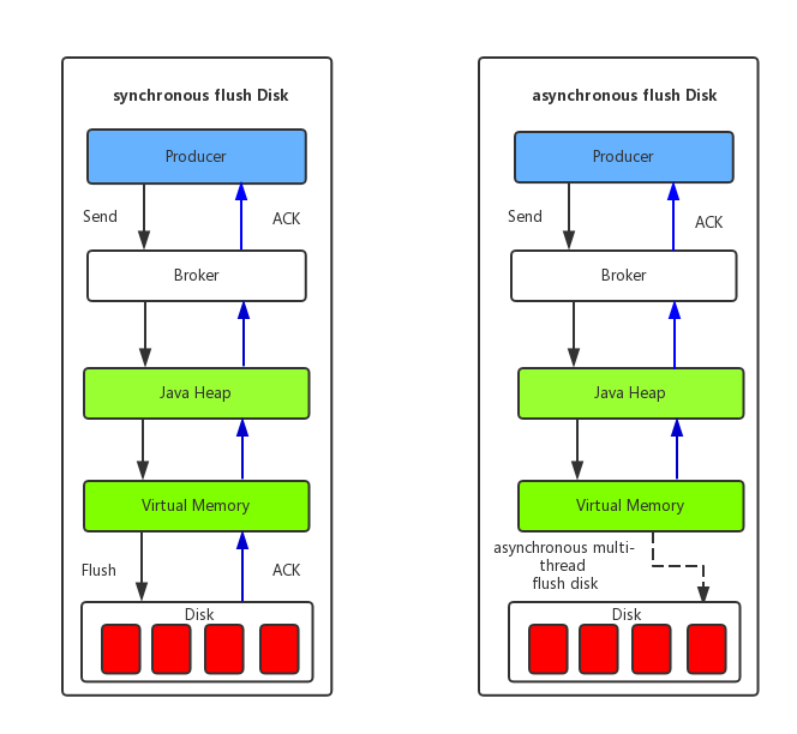
刷盘的方式有以下两种:
- 同步刷盘:如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘时MQ消息可靠性来说是一种不错的保障,但是性能上会有较大的影响,一般适用于金融业务应用该模式较多
- 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量
通信机制
RocketMQ消息队列集群主要包括NameServer、Broker(Master、Slave)、Producer、Consumer4个角色,基本通讯流程如下:
- Broker启动后需要完成一次将自己注册至NameServer的操作;随后每隔30s时间定时向NameServer上报Topic路由信息
- 消息生产者Producer作为客户端发送消息的时候,需要根据消息的Topic从本地缓存的TopicPublishInfoTable获取路由消息。如果没有则更新路由信息会从NameServer上重新拉取,同时Producer会默认每隔30s向NameServer拉取一次路由信息
- 消息生产者Producer会根据第二步中获取的路由信息选择一个队列(MessageQueue)进行消息发送;Broker作为消息的接收者接收消息并落盘存储
- 消息消费者Consumer会根据第二步中获取的路由信息,并在完成客户端的负载均衡后,选择其中的某一个或者几个消费队列来拉取消息并进行消费
RoketMQ集群中的角色几乎都会进行通信,rocketmq-remoting模块是RocketMQ消息队列中负责网络通信的模块,它几乎被其它所有需要网络通信的模块(诸如rocketmq-client、rocketmq-broker、rocketmq-namesrv)所依赖和引用。为了实现客户端与服务器之间的高效的数据请求与结构,RocketMQ消息队列自定义了通信协议并在Netty的基础之上扩展了通信模块。
RocketMQ通信类结构
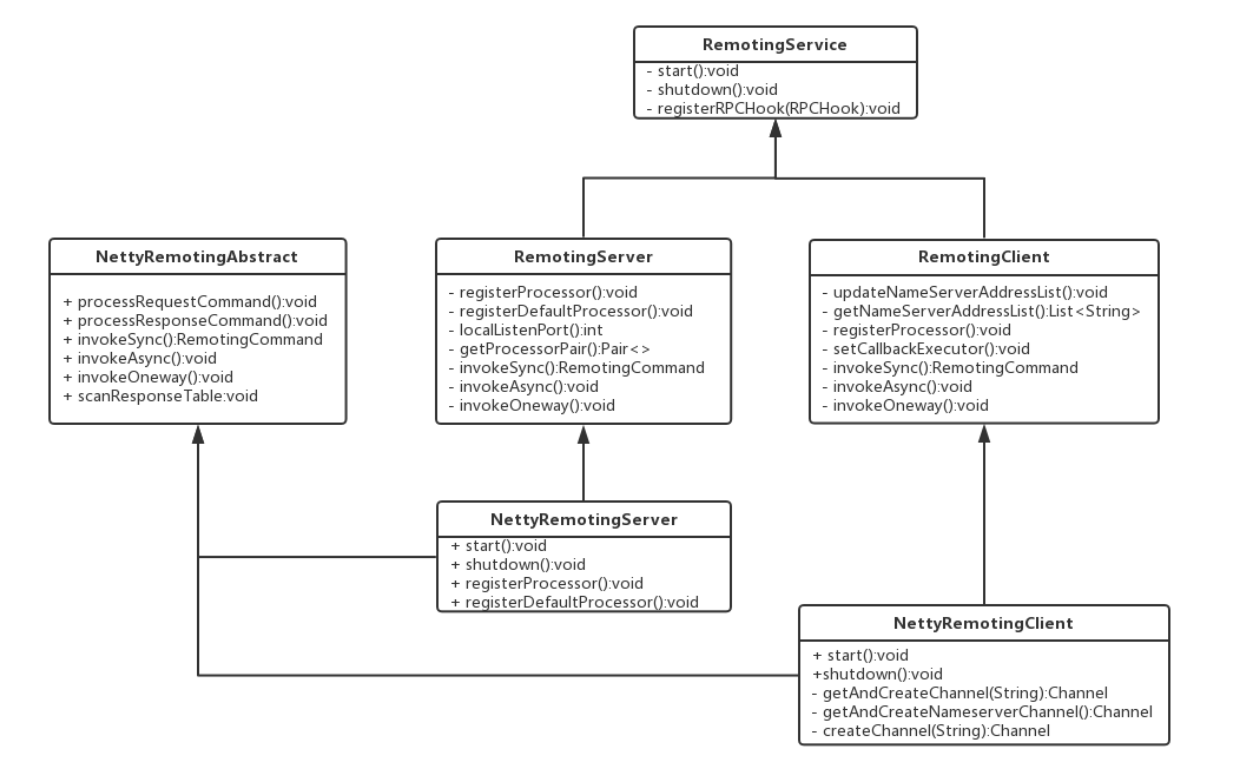
在RocketMQ中使用了自定义协议,RemotingCommand这个类在消息传输过程中对所有数据内容的封装,不但包含了所有的数据结构,还包含了编解码的操作。
传输的内容主要分为4个部分:

详细含义如下:
- 消息长度:总长度,四个字节存储,占用一个int类型
- 序列化类型&消息长度:同样占用一个int类型,第一个字节表示序列化类型,后面三个字节表示消息头长度
- 消息头数据:经过序列化后的消息头数据
- 消息主体数据:消息主体的二进制字节数据内容
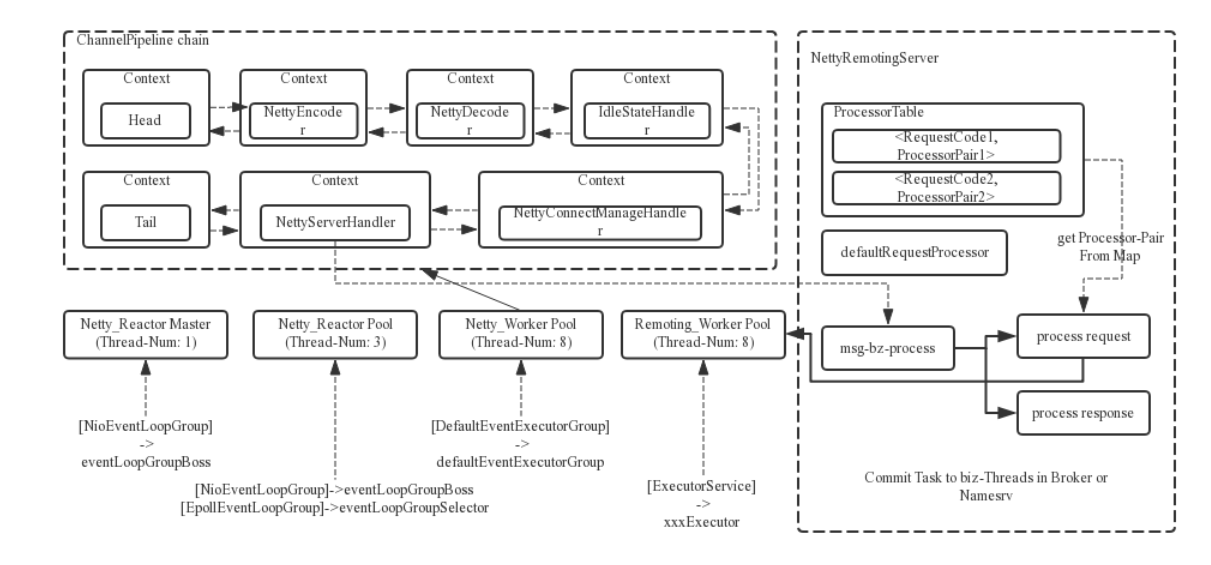
Reactor线程设计
RocketMQ的RPC通信采用Netty组件作为底层通信库,同样也遵循了Reactor线程模型,同时又在这之上做了一些扩展和优化。
消息过滤
RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的。RocketMQ这么做是在于其Producer端写入消息和Consumer订阅消息采用分离存储的机制来实现的。Consumer端订阅消息是需要通过ConsumerQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也还是绕不开其存储结构。其ConsumerQueue的存储结构如下,可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤正是基于这个字段值的。

主要支持如下两种的方式的过滤:
- Tag过滤方式:Consumer端在订阅消息时除了指定Topic还可以指定Tag,如果一个消息有多个TAG,可以用“||”分隔。其中,Conusmer端会将这个订阅请求构建成一个SubscriptionData,发送一个pull消息的请求给Broker端。Broker端从RocketMQ的文件存储层——Store读取数据之前,会用这些数据先构建一个MessageFilter,然后传给Store。Store从ConsumerQueue读取到一条记录后,会用它记录的消息tag hash值去做过滤,由于在服务端只是根据hashcode进行判断,无法精确对tag原始字符串进行过滤,故消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费
- SQL92的过滤方式:这种方式的大致做法和上面Tag过滤方式一样,只是在Store层的具体过滤过程不太一样,真正的SQL expression的构建和执行由rocketmq-filter模块负责的。每次过滤都去执行SQL表达式会影响效率,所以RocketMQ使用了BloomFilter避免了每次都去执行。SQL92的表达式上下文为消息的属性
负载均衡
消息消费队列在同一消费者组不同消费者之间的负载均衡,其核心设计理念是在一个消息队列时间在同一时间只允许被同一消费者组的一个消费者消费,一个消息消费者能同时消费多个消息队列。
最佳实践
生产者
Tags的使用
一个应用尽可能用一个Topic,而消息子类型则可以用tags来标识。tags可以由应用自由设置,只有生产者在发送消息设置了tags,消费方在订阅消息时才可以利用tags通过broker做消息过滤:message.setTags("TagsA||TagsB")。
Keys的使用
每个消息在业务层面的唯一标识码要设置到keys字段,方便来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过topic、key来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
选择oneway形式发送
通常消息的发送时这样的一个过程:
- 客户端发送请求到服务器
- 服务器处理请求
- 服务器向客户端返回应答
所以,一次消息发送的耗时时间时上述三个步骤的总和,而某些场景要求耗时非常短,但是对可靠性要求并不高,例如日志收集类应用,此类应用可以采用oneway形式调用,oneway形式只发送请求不等待应答,而发送请求在客户端实现层面仅仅是一个操作系统调用的开销,即将数据写入客户端的socket缓冲区,此过程通常在微秒级。
消费者
消费过程幂等
RocketMQ无法避免消息重复(Exactly-Once),所以如果业务对消费重复非常敏感,务必要在业务层面进行去重处理。可以借助关系数据库进行去重。首先需要确定消息的唯一键,可以是msgId,也可以是消息内容中的唯一标识字段,例如订单id等。在消费之前判断唯一键是否在关系数据库中存在,如果不存在则插入,并消费,否则跳过(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过)。
msgId一定是全局唯一标识符,但是实际使用中,可能会存在相同的消息有两个不同的msgId的情况(消息主动重发、因客户端重投机制导致重复等),这种情况就需要业务字段进行重复消费。
提升消费速度
提高消费并行度
绝大部分消息消费行为都属于IO密集型,即可能是操作数据库,或者调用RPC,这类消费行为的消费速度取决于后端数据库或者外部系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须设置合理的并行度,可以通过如下几种方式修改消费并行度的方法:
- 同一个ConsumerGroup下,通过增加Consumer实例数量来提高并行度(需要注意的是超过订阅队列数的Consumer实例无效)。可以通过增加及其或者在已有机器启动多个进程的方式
- 提高单个Consumer的消费并行线程,通过修改参数consumerThreadMin、consumerThreadMax实现
批量方式消费
- 某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时1s,一次处理10个订单可能也只耗时2s,这样即可大幅度提高消费的吞吐量,通过设置consumer的consumerMessageBatchMaxSize参数,默认是1,即一次只消费一条消息,例如设置为N,那么每次消费的消息数小于等于N
跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送的速度,如果业务对数据的要求不高的话,可以选择丢弃不重要的消息。例如,当队列的消息数堆积到100000条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度,示例代码如下:
public ConsumeConcurrentlyStatus consumeMessage( List<MessageExt> msgs, ConsumeConcurrentlyContext context) { long offset = msgs.get(0).getQueueOffset(); String maxOffset = msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET); long diff = Long.parseLong(maxOffset) - offset; if (diff > 100000) { // TODO 消息堆积情况的特殊处理 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; } // TODO 正常消费过程 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; }优化每条消息消费过程
优化消息消费时的速度,可以优化消费流程,也可以将部分耗时的操作交由线程池处理
顺序消费
并发消费
无序消息也指普通消息,Producer只管发送消息,Consumer只管接收消息,至于消息和消息之间的顺序并没有保证。
生产者并发消费的示例:
@Slf4j
public class concurrentProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("op");
producer.setNamespace("localhost:9876");
producer.start();
for (int i = 0; i < 100; i++) {
byte[] body = ("Hi" + i).getBytes();
Message msg = new Message("TopicA", "TagA", body);
SendResult sendResult = producer.send(msg);
log.info("发送结果: {}", sendResult);
}
producer.shutdown();
}
}
消费者并发消费的示例:
@Slf4j
public class ConcurrentConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("op");
consumer.setNamespace("localhost:9876");
consumer.start();
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
for (MessageExt messageExt : list) {
log.info("并发消费: {}", messageExt);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.shutdown();
}
}
顺序消费
顺序消息指的是,严格按照消息的发送顺序进行消费的消息(FIFO)。
默认情况下生产者会把消息以Round Robin轮询方式发送到不同的Queue分区队列;而消费消息时会从多个Queue上拉取消息,这种情况下的发送和消费是不能保证顺序的。如果将消息仅发送到同一个Queue中,消费时也只从这个Queue上拉取消息,就严格保证了消息的顺序性。
全局有序
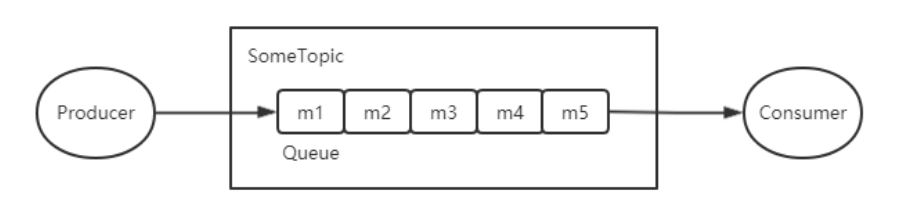
当发送和消费参与的Queue只有一个时所保证的有序是整个Topic中消息的顺序,称为全局有序。创建Topic时指定Queue的数量有以下三种方式:
- 在代码中创建Producer时,可以指定其自动创建的Topic的Queue的数量
- 在RocketMQ可视化控制台中手动创建Topic时指定Queue的数量
- 使用mqadmin命令手动创建Topic时指定Queue的数量
分区有序
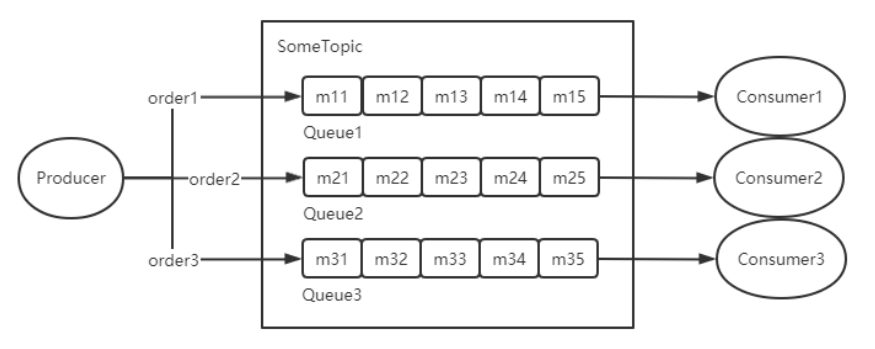
如果有多个Queue参与,其仅可保证在该Queue分区队列上的消息顺序,则称为分区有序。那么我们该如何Queue的选择呢?在定义Producer的时候我们可以指定消息队列选择器,这个选择器是我们自己实现了MessageQueueSelector接口定义的。
public class CustomMessageQueueSelector implements MessageQueueSelector {
/**
* @param list 该Topic下所有可选的MessageQueue
* @param message 待发送的消息
* @param o send方法传入的第三个参数
*/
@Override
public MessageQueue select(List<MessageQueue> list, Message message, Object o) {
return null;
}
}
在定义选择器的选择算法时,一般需要使用选择key。这个选择key可以是消息key也可以是其它数据。但无论谁做选择key,都不能重复,都是唯一的。
取模算法存在一个问题:不同选择key与Queue数量取模结果可能会是相同的,即不同选择key的消息可能会出现相同的Queue,即同一个Consumer可能会消费到不同选择key的消息。解决这个问题的一般性做法是,从消息中获取到选择key,对其进行判断,若是当前Consumer需要消费的消息,则直接消费。否则,什么也不做。这种做法要求选择key要能够随着消息一起被Consumer获取到,此时使用消息key作为选择key是比较好的做法。
以上做法会不会出现如下新的问题呢?不属于那个Consumer的消息被拉取走了,那么应该消费该消息的Consumer是否还能再消费该消息呢?同一个Queue中的消息不可能被同一个Group中的不同Consumer同时消费。所以,消费同一个Queue的不同选择key的消息的Consumer一定属于不同的Group,而不同的Group中的Consumer间的消费是相互隔离的,互不影响。
生产者顺序消费的示例:
@Slf4j
public class OrderedProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("op");
producer.setNamespace("localhost:9876");
producer.start();
for (int i = 0; i < 100; i++) {
Integer orderId = i;
byte[] body = ("Hi" + i).getBytes();
Message msg = new Message("TopicA", "TagA", body);
// 实现自定义的队列选择器
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> list, Message message, Object o) {
Integer id = (Integer) o;
int index = id % list.size();
return list.get(index);
}
}, orderId);
log.info("发送结果: {}", sendResult);
}
producer.shutdown();
}
}
消费者顺序消费的示例:
@Slf4j
public class OrderedConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("op");
consumer.setNamespace("localhost:9876");
consumer.start();
// 这里必须是MessageListenerOrderly才会保证接收到的消息是有序的
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> list, ConsumeOrderlyContext consumeOrderlyContext) {
for (MessageExt messageExt : list) {
log.info("顺序消费: {}", messageExt);
}
consumeOrderlyContext.setAutoCommit(true);
return ConsumeOrderlyStatus.SUCCESS;
}
});
consumer.shutdown();
}
}
订阅关系的一致性
在使用RocketMQ可能会出现消费者无法消费的情况,即consume but filter,这是因为订阅关系不一致导致的,订阅关系的一致性指的是,同一个消费者组(Group ID相同)下所有的Consumer实例所订阅的Topic与Tag及对消息的处理逻辑必须完全一致。否则,消息消费的逻辑就会混乱,甚至导致消息丢失。
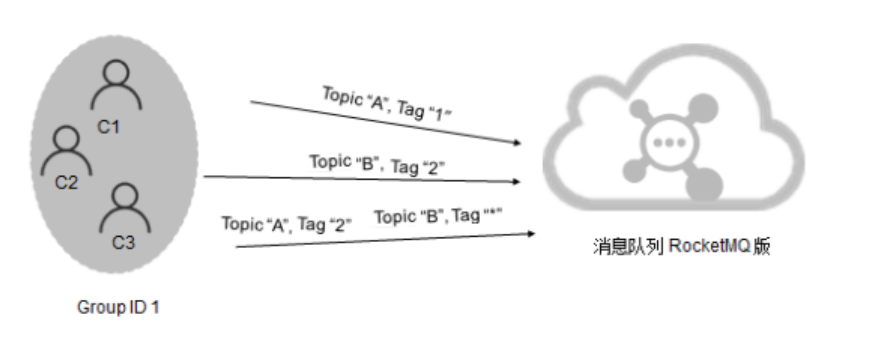
正确的订阅关系
多个消费者组订阅了多个Topic,并且每个消费者组里的多个消费者实例的订阅关系保持了一致。
错误的订阅关系
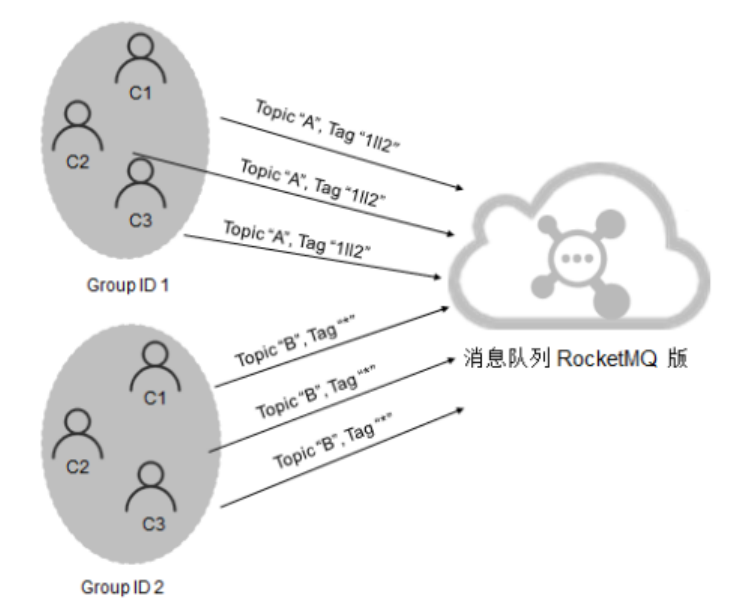
一个消费者组订阅了多个Topic,但是该消费者组里的多个Consumer实例的订阅关系并没有保持一致。
订阅了不同的Topic
实例1:
@Slf4j
public class differentTopicConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group1");
consumer.subscribe("test_topic_A", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
实例2:
@Slf4j
public class differentTopicConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group1");
consumer.subscribe("test_topic_B", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
以上在同一个消费者组中的两个相同的Consumer实例订阅了不同的Topic,就会导致无法消费消息。
订阅了不同Tag
实例1:
@Slf4j
public class differentTagsConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group2");
consumer.subscribe("test_topic_A", "TagA");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
实例2:
@Slf4j
public class differentTagsConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group2");
consumer.subscribe("test_topic_A", "TagB");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
同一个消费者组中的两个Consumer订阅了相同Topic的不同Tag也会导致无法消费,这也是实际开发中比较容易犯得错误。
订阅不同数量的Topic
实例1:
@Slf4j
public class differentNumberTopicConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group3");
consumer.subscribe("test_topic_B", "TagA");
consumer.subscribe("test_topic_B", "TagB");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
实例2:
@Slf4j
public class differentNumberTopicConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("group3");
consumer.subscribe("test_topic_B", "TagA");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
log.info("消费消息: {}", list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
}
}
同一个消费者中的两个Consumer订阅了不同数量的Topic也会导致消费失败。
SpringBoot整合RocketMQ
在之前的例子当中,我们都使用的是DefaultMQProducer/DefaultMQPushConsumer,通过设置一些参数来改变MQ的行为,但这种方式并没有那么的“Spring”,实际上,RocketMQ针对于SpringBoot也提供了相应的starter,使得RocketMQ可以做到“开箱即用”。
配置管理
依赖管理
<!-- https://mvnrepository.com/artifact/org.apache.rocketmq/rocketmq-spring-boot-starter -->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.1</version>
</dependency>
引入了这个依赖之后,就无需再引入rocketmq-client相应的依赖了。
外部化配置
在SpringBoot中,我们可以通过内置的配置项来改变Producer和Consumer的行为:
rocketmq:
# 可以有多个,多个的情况使用;隔开
name-server: 127.0.0.1:9876
producer:
group: my-group
# 开启消息轨迹,消费端需要在消费者中指定
enable-msg-trace: true
customized-trace-topic: my-trace-topic
# ACL功能,消费端需要在消费者中指定
access-key: AK
secret-key: SK
配置类
如果想要自定义更多的DefaultMQPushConsumer的其它配置,我们就需要采用如下的方式:
@Slf4j
@Component
@RocketMQMessageListener(topic = "test-topic-1", consumerGroup = "my-consumer_test-topic-1")
public class MyConsumer1 implements RocketMQListener<String>, RocketMQPushConsumerLifecycleListener {
@Override
public void onMessage(String message) {
log.info("received message: {}", message);
}
@Override
public void prepareStart(final DefaultMQPushConsumer consumer) {
// set consumer consume message from now
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_TIMESTAMP);
consumer.setConsumeTimestamp(UtilAll.timeMillisToHumanString3(System.currentTimeMillis()));
}
}
消费消息的时候,除了获取消息payload外,还想获取RocketMQ消息的其它系统属性,那么我们在实现RocketMQListener接口时,只需要指定泛型为MessageExt即可,这样在onMessage方法就可以接收到RocketMQ原生的MessageExt消息:
@Slf4j
@Service
@RocketMQMessageListener(topic = "test-topic-1", consumerGroup = "my-consumer_test-topic-1")
public class MyConsumer2 implements RocketMQListener<MessageExt> {
public void onMessage(MessageExt messageExt) {
log.info("received messageExt: {}", messageExt);
}
}
发送消息
发送普通消息
发送消息的示例:
@Component
public class ProducerDemo implements CommandLineRunner {
@Resource
private RocketMQTemplate rocketMQTemplate;
@Override
public void run(String... args) throws Exception {
// 同步发送消息
rocketMQTemplate.convertAndSend("test-topic-1", "Hello, World!");
//send spring message
rocketMQTemplate.send("test-topic-1", MessageBuilder.withPayload("Hello, World! I'm from spring message").build());
// 异步发送消息
rocketMQTemplate.asyncSend("test-topic-2", new OrderPaidEvent("T_001", new BigDecimal("88.00")), new SendCallback() {
@Override
public void onSuccess(SendResult var1) {
System.out.printf("async onSucess SendResult=%s %n", var1);
}
@Override
public void onException(Throwable var1) {
System.out.printf("async onException Throwable=%s %n", var1);
}
});
// 发送单向消息
rocketMQTemplate.sendOneWay("springboot-topic:tag1", "这是一条单向消息");
// 同步顺序发送
rocketMQTemplate.syncSendOrderly("orderly_topic", MessageBuilder.withPayload("Hello, World").build(), "hashkey");
// 发送多条
for (int i = 0; i < 10; i++) {
rocketMQTemplate.sendOneWayOrderly("springboot-topic:tag1", "这是一条顺序消息" + i, "2673");
rocketMQTemplate.sendOneWayOrderly("springboot-topic:tag1", "这是一条顺序消息" + i, "2673");
}
// 延迟发送
// messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
// 这里设置4,即30s的延迟
Message<String> msg = new GenericMessage<>("我是一条延迟消息");
rocketMQTemplate.asyncSend("topic-delay", msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
//发送成功
}
@Override
public void onException(Throwable throwable) {
//发送失败
}
}, 100, 4);
//rocketMQTemplate.destroy(); // notes: 一旦rocketMQTemplate被销毁了,就无法使用它来发送消息了
}
@Data
@AllArgsConstructor
public static class OrderPaidEvent implements Serializable {
private String orderId;
private BigDecimal paidMoney;
}
}
发送事务消息
发送事务消息的示例:
@Component
public class TransactionProducer implements CommandLineRunner {
@Resource
private RocketMQTemplate rocketMQTemplate;
@Override
public void run(String... args) throws Exception {
// Build a SpringMessage for sending in transaction
Message<String> msg = MessageBuilder.withPayload("...").build();
// In sendMessageInTransaction(), the first parameter transaction name ("test")
// must be same with the @RocketMQTransactionListener's member field 'transName'
rocketMQTemplate.sendMessageInTransaction("test", msg, null);
}
// Define transaction listener with the annotation @RocketMQTransactionListener
@RocketMQTransactionListener
static class TransactionListenerImpl implements RocketMQLocalTransactionListener {
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// ... local transaction process, return bollback, commit or unknown
return RocketMQLocalTransactionState.UNKNOWN;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
// ... check transaction status and return bollback, commit or unknown
return RocketMQLocalTransactionState.COMMIT;
}
}
}
接收消息
接收普通消息
接收普通消息的示例:
@Component
public class ConsumerApplication{
@Slf4j
@Component
@RocketMQMessageListener(topic = "test-topic-1", consumerGroup = "my-consumer_test-topic-1")
public class MyConsumer1 implements RocketMQListener<String>{
public void onMessage(String message) {
log.info("received message: {}", message);
}
}
@Slf4j
@Component
@RocketMQMessageListener(topic = "test-topic-2", consumerGroup = "my-consumer_test-topic-2")
public class MyConsumer2 implements RocketMQListener<OrderPaidEvent>{
public void onMessage(OrderPaidEvent orderPaidEvent) {
log.info("received orderPaidEvent: {}", orderPaidEvent);
}
}
/**
* MessageModel:集群模式;广播模式
* ConsumeMode:顺序消费;无序消费
*/
@Component
@RocketMQMessageListener(topic = "springboot-topic", consumerGroup = "consumer-group",
//selectorExpression = "tag1",selectorType = SelectorType.TAG,
messageModel = MessageModel.CLUSTERING, consumeMode = ConsumeMode.CONCURRENTLY)
public class MessageConsumer implements RocketMQListener<String> {
@Override
public void onMessage(String message) {
System.out.println("----------接收到rocketmq消息:" + message);
// rocketmq会自动捕获异常回滚 (官方默认会重复消费16次)
int a = 1 / 0;
}
}
}
接收事务消息
接收事务的示例:
@Component
public class ProducerApplication implements CommandLineRunner{
@Resource
private RocketMQTemplate rocketMQTemplate;
public void run(String... args) throws Exception {
try {
// Build a SpringMessage for sending in transaction
Message msg = MessageBuilder.withPayload(..)...;
// In sendMessageInTransaction(), the first parameter transaction name ("test")
// must be same with the @RocketMQTransactionListener's member field 'transName'
rocketMQTemplate.sendMessageInTransaction("test", "test-topic", msg, null);
} catch (MQClientException e) {
e.printStackTrace(System.out);
}
}
// Define transaction listener with the annotation @RocketMQTransactionListener
@RocketMQTransactionListener
class TransactionListenerImpl implements RocketMQLocalTransactionListener {
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// ... local transaction process, return bollback, commit or unknown
return RocketMQLocalTransactionState.UNKNOWN;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
// ... check transaction status and return bollback, commit or unknown
return RocketMQLocalTransactionState.COMMIT;
}
}
}
RocketMQ原理分析
RocketMQ也遵循了模块化设计,其核心模块有:
- namesrv:命名发现服务,broker 服务的管理与路由
- broker:核心组件,接收 producer发送的消息和消息的存储与consumer`的消息消费
- client:客户端实现,producer和 consumer的实现模块
- store:存储层实现,消息持久化、索引服务、高可用 HA 服务实现
- remoting:通信层实现,基于 Netty 的底层封装,服务间的交互通讯都依赖此模块
- filter:消息过滤服务,相当于在broker和consumer中间加入了一个 filter 代理
- common:模块间通用的功能类、方法、配置文件、常量等
- tools:命令管理工具,提供了消息查询、topic 管理等功能
- example:官方提供的例子,对典型的功能比如 order message,push consumer,pull consumer 的用法进行了示范
消息发送过程
首先创建一条即将发送的消息:
Message msg = new Message("Test", "Hello World".getBytes());
然后定义好消息的发送者:
DefaultMQProducer producer = new DefaultMQProducer();
producer.start();
发送消息的整体流程如下:
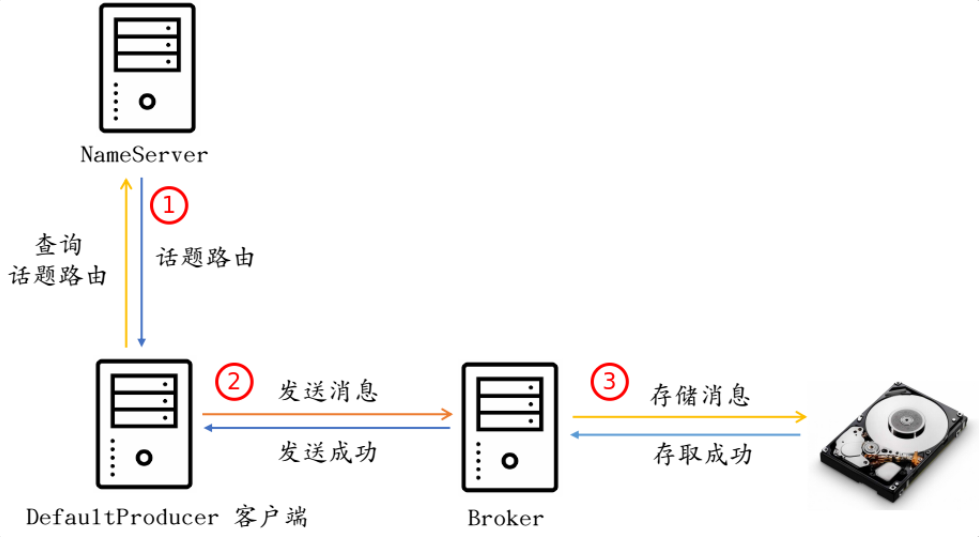
选择发送的路由
使用RocketMQ的时候通常我们都会使用集群部署:
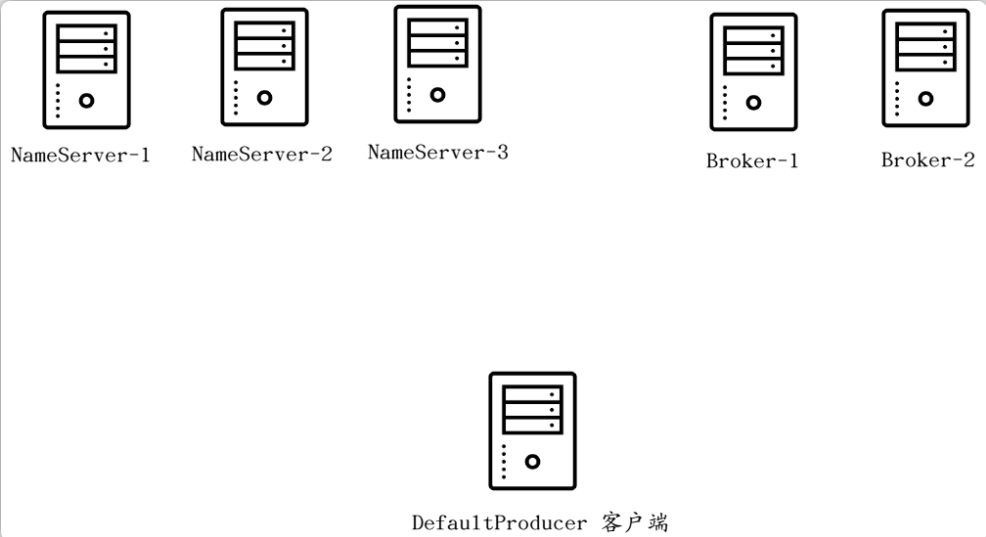
客户端在发送消息之前首先要询问NameServer才能确定一个合适的Broker以进行消息的发送:
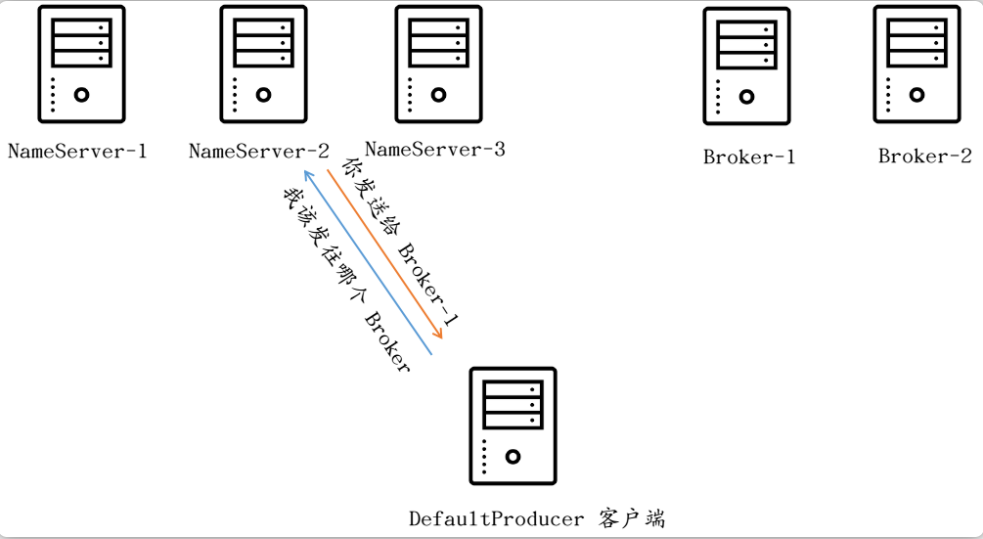
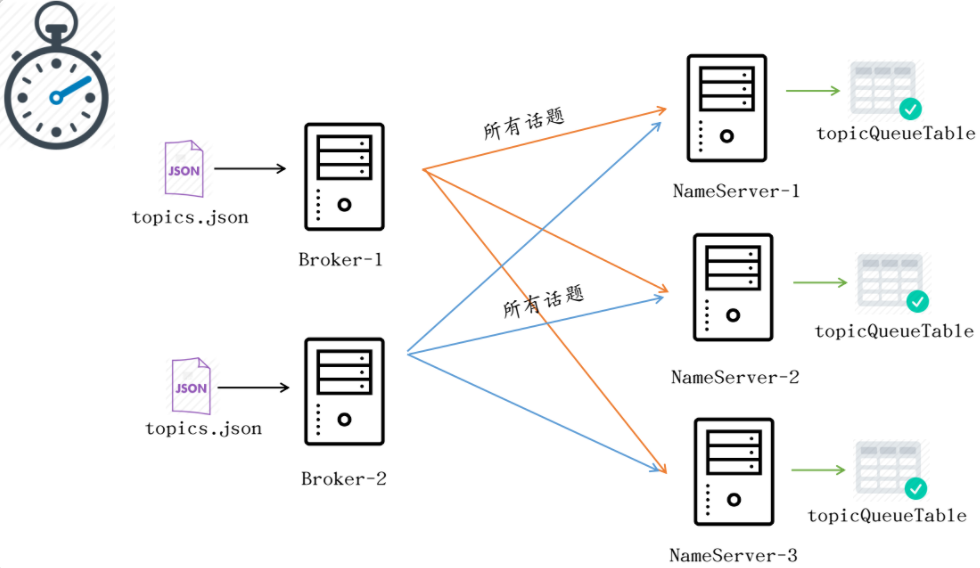
显然,所有的NameServer中的数据都是一致的,在Broker启动的时候,其会将自己在本地存储的Topic配置文件(默认位于$HOME/store/config/topics.json目录)中所有的Topic加载到内存中去,然后会将这些所有的Topic全部同步到所有的NameServer中,与此同时,Broker也会启动一个定时任务,默认每隔30s来执行一次Topic同步:
由于NameServer服务去中每台机器存储的数据都是一致的,因为客户端任意选择一台服务器进行发送即可。客户端选择NameServer的源码如下:
public class NettyRemotingClient extends NettyRemotingAbstract implements RemotingClient {
private final AtomicInteger namesrvIndex = new AtomicInteger(initValueIndex());
private static int initValueIndex() {
Random r = new Random();
return Math.abs(r.nextInt() % 999) % 999;
}
private Channel getAndCreateNameserverChannel() throws InterruptedException {
String addr = this.namesrvAddrChoosed.get();
if (addr != null) {
ChannelWrapper cw = this.channelTables.get(addr);
if (cw != null && cw.isOK()) {
return cw.getChannel();
}
}
// ...
for (int i = 0; i < addrList.size(); i++) {
int index = this.namesrvIndex.incrementAndGet();
index = Math.abs(index);
index = index % addrList.size();
String newAddr = addrList.get(index);
this.namesrvAddrChoosed.set(newAddr);
Channel channelNew = this.createChannel(newAddr);
if (channelNew != null)
return channelNew;
}
// ...
}
}
以后,如果NamenamesrvAddrChoosed选择的服务器如果一直处于连接状态,那么客户端就会一直与这台服务器进行沟通。否则的话,如上源代码所示,就会自动轮询下一台可用的服务器。
在客户端发送消息的时候,其首先会尝试寻找话题路由信息,即这条消息应该被发送到哪个地方去。客户端在内存中维护了一份和Topic相关的路由信息表topicPublishInfoTable,当发送消息的时候,会首先尝试从表中获取信息。如果此表中不存在这条话题的话,那么便会从NameServer获取路由信息。

源码如下:
public class DefaultMQProducerImpl implements MQProducerInner {
private TopicPublishInfo tryToFindTopicPublishInfo(final String topic) {
TopicPublishInfo topicPublishInfo = this.topicPublishInfoTable.get(topic);
if (null == topicPublishInfo || !topicPublishInfo.ok()) {
this.topicPublishInfoTable.putIfAbsent(topic, new TopicPublishInfo());
this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic);
topicPublishInfo = this.topicPublishInfoTable.get(topic);
}
// ...
}
}
当尝试从NameServer服务器获取路由的时候,其可能会返回两种情况:
- 新建Topic
- 已存Topic
当Topic是新建的,NameServer不存在和此Topic相关的信息:
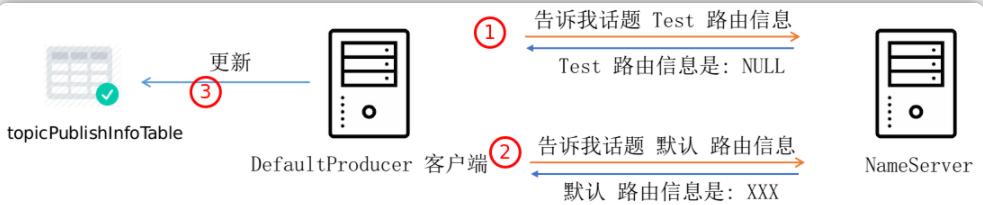
Topic之前已经创建过,NameServer存在此Topic的信息:

服务器返回的Topic路由信息包括以下内容:
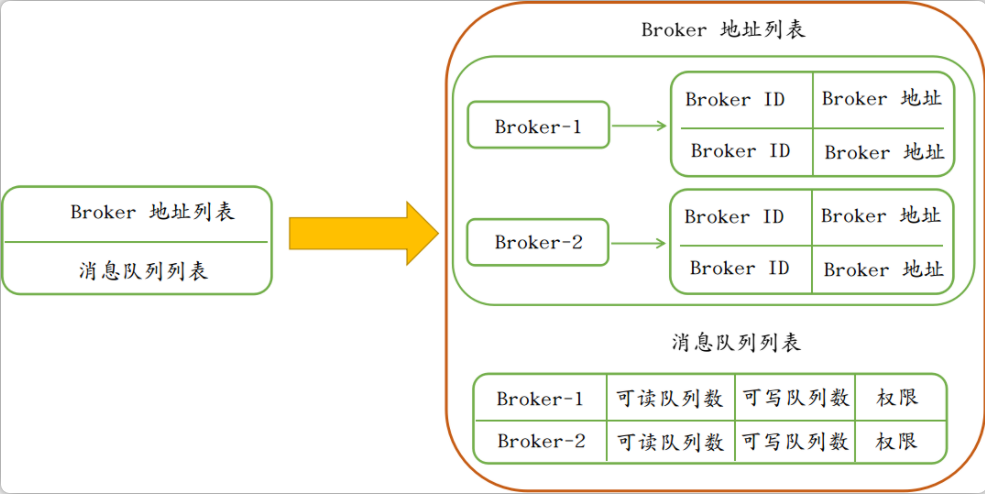
“Broker-1”、“Broker-2”分别为两个Broker服务器的名称,相同名称下可以有主从Broker,因此每个Broker又都有brokerId,默认情况下,BokerId如果为MixAll.Master_ID(值为0)的话,那么认为这个Broker为MASTER主机,其余位于相同名称下的Broker为这台MASTER主机的SLAVE从机。
public class MQClientInstance {
public String findBrokerAddressInPublish(final String brokerName) {
HashMap<Long/* brokerId */, String/* address */> map = this.brokerAddrTable.get(brokerName);
if (map != null && !map.isEmpty()) {
return map.get(MixAll.MASTER_ID);
}
return null;
}
}
每个Broker上面可以绑定多个可写消息队列和多个可读消息队列,客户端根据返回的所有Broker地址列表和每个Broker的可写消息队列列表会在内存中构建一份所有的消息队列列表。之后客户端每次发送消息,都会在消息队列列表上轮询选择队列(这里我们假设返回了两个Broker,每个Broker均又4个可写消息队列):
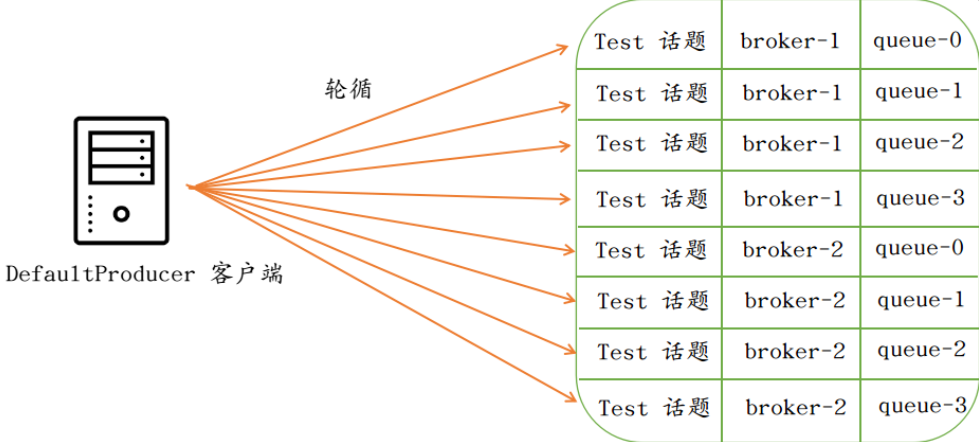
向Broker发送消息
在确定了Master Broker地址和这个Broker的消息队列之后,客户端才开始真正地发送消息给这个Broker,也是从这里客户端才开始与Broker进行交互:

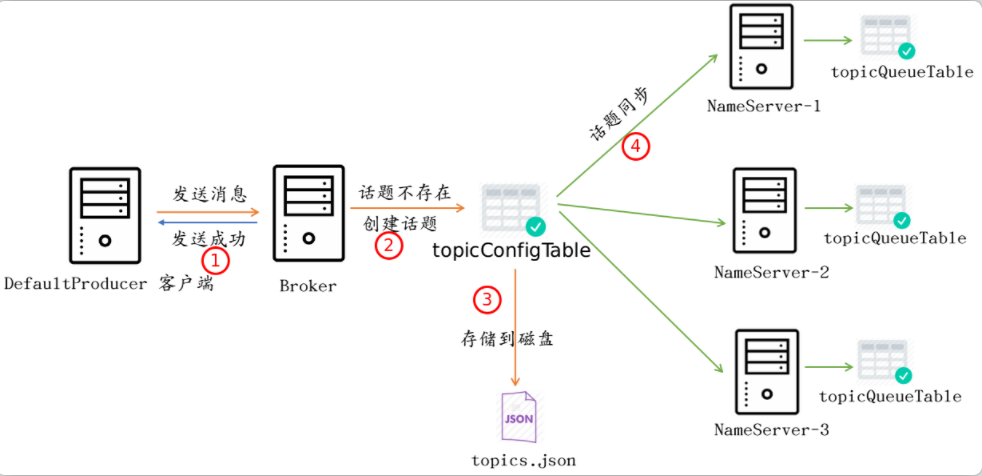
上节说到,如果Topic的信息在NameServer不存在的话,那么会使用默认的Topic信息进行消息的发送。然而一旦这条消息到来之后,Broker端还没有这个话题,所以Broker需要检查Topic的存在性:
public abstract class AbstractSendMessageProcessor implements NettyRequestProcessor {
protected RemotingCommand msgCheck(final ChannelHandlerContext ctx,
final SendMessageRequestHeader requestHeader, final RemotingCommand response) {
// ...
TopicConfig topicConfig =
this.brokerController
.getTopicConfigManager()
.selectTopicConfig(requestHeader.getTopic());
if (null == topicConfig) {
// ...
topicConfig = this.brokerController
.getTopicConfigManager()
.createTopicInSendMessageMethod( ... );
}
}
}
如果Topic不存在的话,那么便会创建一个Topic信息存储到本地,并将所有Topic同步给所有的NameServer:
public class TopicConfigManager extends ConfigManager {
public TopicConfig createTopicInSendMessageMethod(final String topic, /** params **/) {
// ...
topicConfig = new TopicConfig(topic);
this.topicConfigTable.put(topic, topicConfig);
this.persist();
// ...
this.brokerController.registerBrokerAll(false, true);
return topicConfig;
}
}
Topic检查的整体的流程如下图:
当Broker对消息的一些字段做过一番必要的检查之后,便会存储到磁盘中去:
消息存储过程
写入文件
当有一条消息过来之后,Broker首先需要做的就是确定这条消息应该存储在哪个文件里面。在RokcetMQ中,这个用来存储消息的文件被称为MappedFile。这个文件默认创建的大小为1GB。
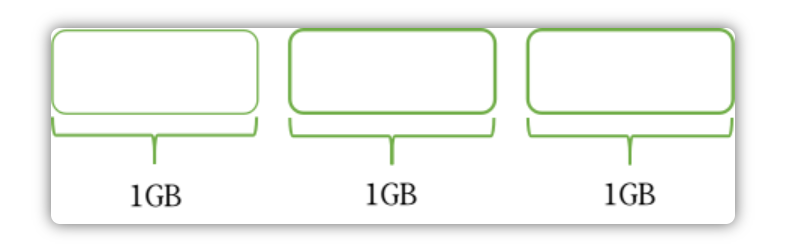
一个文件为1GB大小,也即1024*1024*1024 = 1073741824字节,每个文件的命名是按照总的字节偏移量来命名的。例如一个第一个文件偏移量为0,那么它的名字为00000000000000000000,当这个1G文件被存储满了之后,就会创建下以恶搞文件,下一个文件的偏移量为1GB,那么它的名字为00000000001073741824,一次类推。
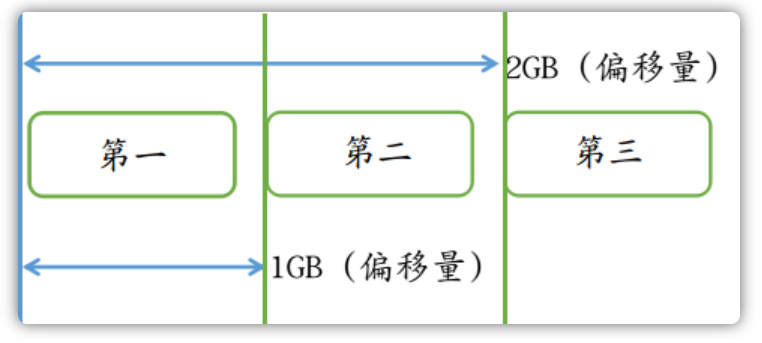
默认情况下这些消息文件位于 $HOME/store/commitlog 目录下,如下图所示:

当Broker启动的时候,其会将位于存储目录下的所有消息文件加载到一个列表中:
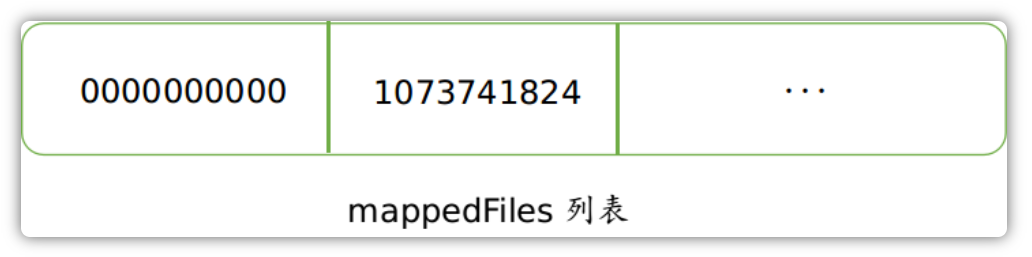
当有新的消息到来的时候,其会默认选择列表中的最后一个文件来进行消息的保存:
public class MappedFileQueue {
public MappedFile getLastMappedFile() {
MappedFile mappedFileLast = null;
while (!this.mappedFiles.isEmpty()) {
try {
mappedFileLast = this.mappedFiles.get(this.mappedFiles.size() - 1);
break;
} catch (IndexOutOfBoundsException e) {
//continue;
} catch (Exception e) {
log.error("getLastMappedFile has exception.", e);
break;
}
}
return mappedFileLast;
}
}
如果这个Broker之前从未接收过消息的话,当有新的消息需要存储的时候,就需要立即创建一个MappedFile文件来存储消息。
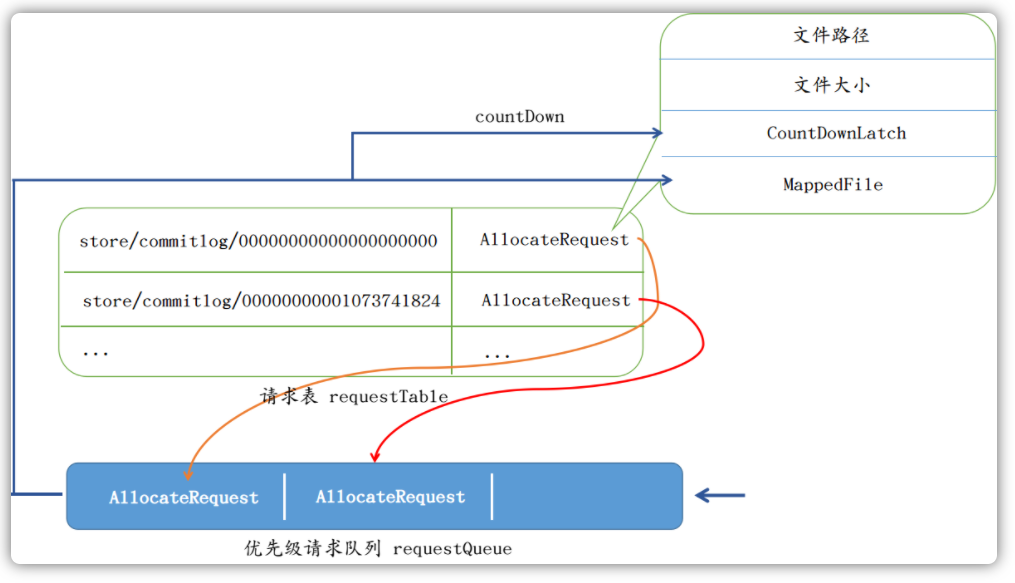
RocketMQ提供了一个专门用来实例化MappedFile文件的服务类AllocateMappedFileService。在内存中,也同时也维护了一张请求表requestTable和一个优先级请求队列requestQueue。当需要创建文件的时候,Broker会创建一个AllocateRequest对象,其包含了文件的路径、大小等信息,然后将其存入requestTable表中,再将其放入优先级请求队列requestQueue中:
public class AllocateMappedFileService extends ServiceThread {
public MappedFile putRequestAndReturnMappedFile(String nextFilePath,
String nextNextFilePath,
int fileSize) {
// ...
AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;
if (nextPutOK) {
// ...
boolean offerOK = this.requestQueue.offer(nextReq);
}
}
}
服务类会一直等待优先级队列是否有新的请求到来,如果有,便会从队列中取出请求,然后创建对应的MappedFile,并将请求表requestTable中AllocateRequest对象的字段mappedFile设置上值。最后将AllocateRequest对象上CountDownLatch的计数器减1,以表明此分配申请的MappedFile已经创建完毕了:
public class AllocateMappedFileService extends ServiceThread {
public void run() {
// 一直运行
while (!this.isStopped() && this.mmapOperation()) {
}
}
private boolean mmapOperation() {
req = this.requestQueue.take();
if (req.getMappedFile() == null) {
MappedFile mappedFile;
// ...
mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
// 设置上值
req.setMappedFile(mappedFile);
}
// ...
// 计数器减 1
req.getCountDownLatch().countDown();
// ...
return true;
}
}
整体流程如下:
等待MappedFIle创建完毕之后,其便会从请求表requestTable中取出并删除表中记录:
public class AllocateMappedFileService extends ServiceThread {
public MappedFile putRequestAndReturnMappedFile(String nextFilePath,
String nextNextFilePath,
int fileSize) {
// ...
AllocateRequest result = this.requestTable.get(nextFilePath);
if (result != null) {
// 等待 MappedFile 的创建完成
boolean waitOK = result.getCountDownLatch().await(waitTimeOut, TimeUnit.MILLISECONDS);
if (!waitOK) {
return null;
} else {
// 从请求表中删除
this.requestTable.remove(nextFilePath);
return result.getMappedFile();
}
}
}
}
然后再将其放到列表中去:
public class MappedFileQueue {
public MappedFile getLastMappedFile(final long startOffset, boolean needCreate) {
MappedFile mappedFile = null;
if (this.allocateMappedFileService != null) {
// 创建 MappedFile
mappedFile = this.allocateMappedFileService
.putRequestAndReturnMappedFile(nextFilePath,
nextNextFilePath,
this.mappedFileSize);
}
if (mappedFile != null) {
// ...
// 添加至列表中
this.mappedFiles.add(mappedFile);
}
return mappedFile;
}
}
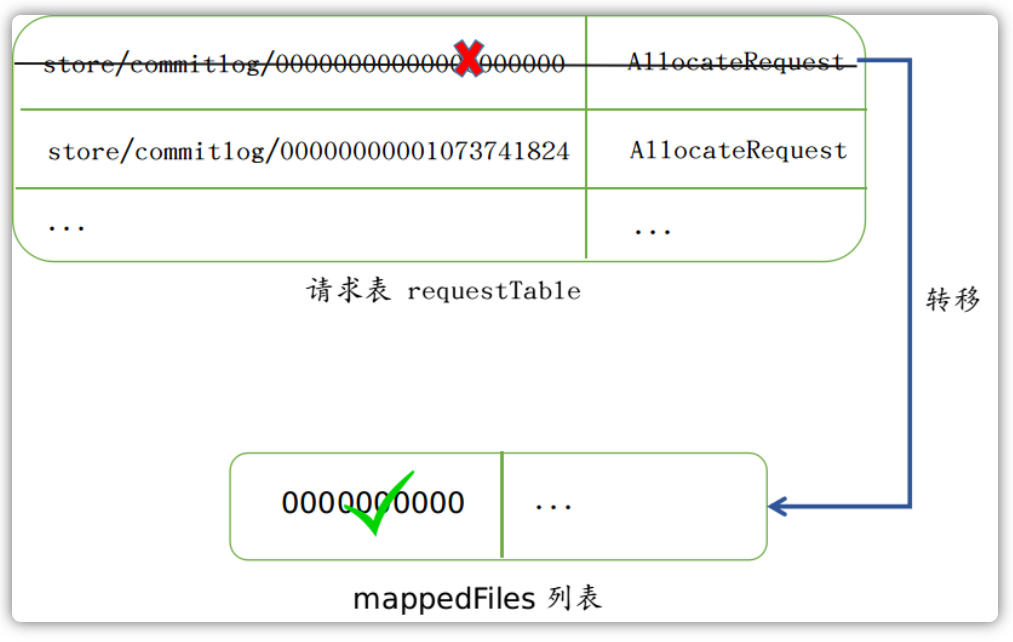
至此,MappedFile 已经创建完毕,也即可以进行下一步的操作了。
在MappedFile的构造函数中,其使用了FileChannel类提供的map函数来将磁盘上的这个文件映射到进程地址空间中。然后当通过MappedByteBuffer来读入或写入文件的时候,磁盘上也会有相应的改动。采用这种方式,通常比传统的基于文件IO流的方式读取效率高。
一旦我们获取到了MappedFile文件之后,便可以往这个文件里面写入消息了。写入消息可能会遇见如下两种情况,一种是这条消息可以完全追加到这个文件中,另一种是这条消息完全不能或者只有一小部分只能存放到这个文件中,其余的需要放到新的文件中,需要分为两种情况分别讨论。
文件可以完全存储消息
MappedFile类维护了一个用以标识当前写位置的指针wrotePosition,以及一个用来映射文件到进程地址空间的mappedByteBuffer:
public class MappedFile extends ReferenceResource {
protected final AtomicInteger wrotePosition = new AtomicInteger(0);
private MappedByteBuffer mappedByteBuffer;
}
由这两个数据结构我们可以看出来,单个文件的消息写入过程其实非常简单,首先获取到这个文件的写位置,然后将消息内容追加到byteBuffer中,然后再更新写入位置。
public class MappedFile extends ReferenceResource {
public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb) {
// ...
int currentPos = this.wrotePosition.get();
if (currentPos < this.fileSize) {
ByteBuffer byteBuffer =
writeBuffer != null ?
writeBuffer.slice() :
this.mappedByteBuffer.slice();
// 更新 byteBuffer 位置
byteBuffer.position(currentPos);
// 写入消息内容
// ...
// 更新 wrotePosition 指针的位置
this.wrotePosition.addAndGet(result.getWroteBytes());
return result;
}
}
}
整体的流程图如下:
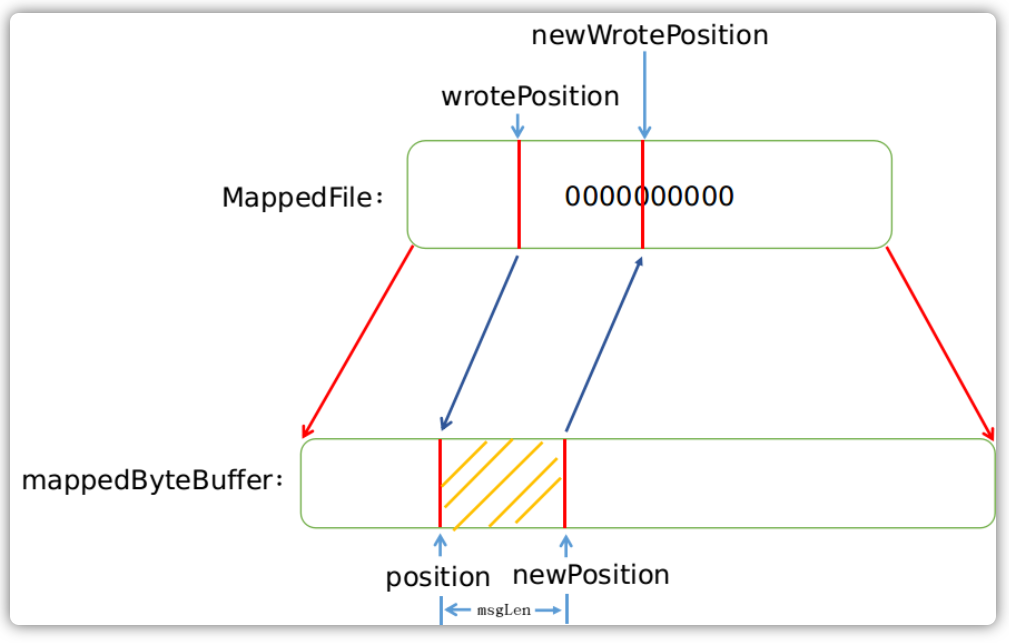
文件不可以完全存储消息
在写入消息之前,如果判断出文件已经满了的情况下,其会直接尝试创建一个新的MappedFile:
public class CommitLog {
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// 文件为空 || 文件已经满了
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = this.mappedFileQueue.getLastMappedFile(0);
}
// ...
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
}
}
如果文件未满,那么在写入之前会先计算出消息长度msgLen,然后判断这个文件剩下的空间是否有能容纳这条消息。在这个地方我们还需要介绍下每条消息的存储方式。
每条消息的存储是按照一个4字节的长度来做界限的,这个长度本身就是整个消息体的长度,当读完这整条消息体的长度之后,下一次再取出来的一个4字节的数字,便又是下一条消息的长度:

围绕一条消息,还会存储许多其它内容,我们这里只需要了解前两位是4字节的长度和4字节的MAGICCODE(魔数)即可:

MAGICCODE的值可能会是:
CommitLog.MESSAGE_MAGIC_CODECommitLog.BLANK_MAGIC_CODE
当这个文件有能力容纳这条消息体的情况下,其便会存储CommitLog.MESSAGE_MAGIC_CODE值;当这个没有能力容纳这条消息的情况下,其便会存储CommitLog.BLANK_MAGIC_CODE值,所以这个MAGICCODE是用来界定这是空消息还是一条正常的消息。
// CommitLog.java
class DefaultAppendMessageCallback implements AppendMessageCallback {
// File at the end of the minimum fixed length empty
private static final int END_FILE_MIN_BLANK_LENGTH = 4 + 4;
public AppendMessageResult doAppend(final long fileFromOffset,
final ByteBuffer byteBuffer,
final int maxBlank,
final MessageExtBrokerInner msgInner) {
// ...
if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) {
// ...
// 1 TOTALSIZE
this.msgStoreItemMemory.putInt(maxBlank);
// 2 MAGICCODE
this.msgStoreItemMemory.putInt(CommitLog.BLANK_MAGIC_CODE);
// 3 The remaining space may be any value
byteBuffer.put(this.msgStoreItemMemory.array(), 0, maxBlank);
return new AppendMessageResult(AppendMessageStatus.END_OF_FILE,
/** other params **/ );
}
}
}
由上述方法我们看出在这种情况下返回的结果是END_OF_FILE。当检测到这种返回结果的时候,CommitLog接着又会申请创建新的MappedFile并尝试写入消息:
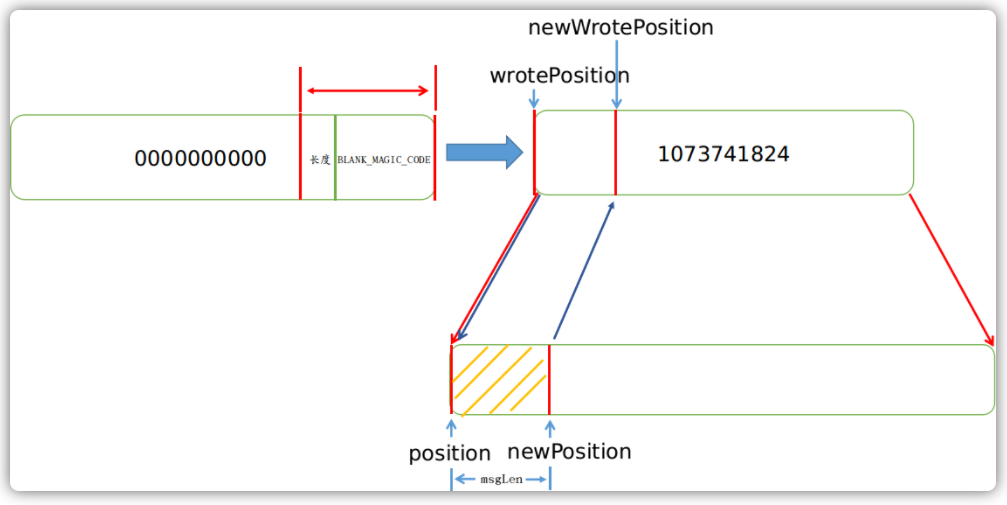
在消息文件加载的过程中,其也是通过判断MAGICCODE的类型,来判断是否继续读取下一个MappedFile来计算整体消息偏移量的。
消息刷盘
当消息体追加到MappedFile以后,这条消息实际上还只是存储在内存中,因此还需要将内存中的内存刷到磁盘上才算真正的存储下来,才能确保消息不丢失。一般而言,刷盘有两种策略:异步刷盘和同步刷盘。
当配置为异步刷盘的时候,Broker会运行一个服务FlushRealTimeService用来刷新缓冲区的消息内容到磁盘,这个服务使用一个独立的线程来做刷盘这件事情,默认情况下每隔500ms来检查一次是否需要刷盘:
class FlushRealTimeService extends FlushCommitLogService {
public void run() {
// 不停运行
while (!this.isStopped()) {
// interval 默认值是 500ms
if (flushCommitLogTimed) {
Thread.sleep(interval);
} else {
this.waitForRunning(interval);
}
// 刷盘
CommitLog.this.mappedFileQueue.flush(flushPhysicQueueLeastPages);
}
}
}
在追加消息完毕之后,通过唤醒这个服务立即检查以下是否需要刷盘:
public class CommitLog {
public void handleDiskFlush(AppendMessageResult result,
PutMessageResult putMessageResult,
MessageExt messageExt) {
// Synchronization flush
if (FlushDiskType.SYNC_FLUSH == this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
// ...
}
// Asynchronous flush
else {
if (!this.defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
// 消息追加成功后,立即唤醒服务
flushCommitLogService.wakeup();
} else {
// ...
}
}
}
}
当配置为同步刷盘策略的时候,Broker运行一个叫做GroupCommitService服务。在这个服务内部维护了写请求队列和一个读请求队列,其中这两个队列每隔10ms就交换一下“身份”,这么做的目的就是为了读写分离:

在这个服务内部,每隔10ms就会检查读请求队列是否不为空,如果不为空,则会将读队列中的所有请求执行刷盘,并清空读请求队列:
class GroupCommitService extends FlushCommitLogService {
private void doCommit() {
// 检查所有读队列中的请求
for (GroupCommitRequest req : this.requestsRead) {
// 每个请求执行刷盘
CommitLog.this.mappedFileQueue.flush(0);
req.wakeupCustomer(flushOK);
}
this.requestsRead.clear();
}
}
在追加消息完毕之后,通常创建一个请求刷盘的对象,然后通过putRequest()方法放入写请求队列中,这个时候会立即唤醒这个服务,写队列和读队列的角色会进行交换,交换角色之后,读请求队列就不为空,继而可以执行所有刷盘请求了。而在这期间,Broker会一直阻塞等待最多5秒钟,在这期间如果完不成刷盘请求的话,那么视作刷盘超时:
public class CommitLog {
public void handleDiskFlush(AppendMessageResult result,
PutMessageResult putMessageResult,
MessageExt messageExt) {
// Synchronization flush
if (FlushDiskType.SYNC_FLUSH == this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
// ...
if (messageExt.isWaitStoreMsgOK()) {
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
service.putRequest(request);
// 等待刷盘成功
boolean flushOK = request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
if (!flushOK) {
// 刷盘超时
putMessageResult.setPutMessageStatus(PutMessageStatus.FLUSH_DISK_TIMEOUT);
}
} else {
// ...
}
}
// Asynchronous flush
else {
// ...
}
}
}
通过方法 putRequest 放入请求后的服务执行流程:
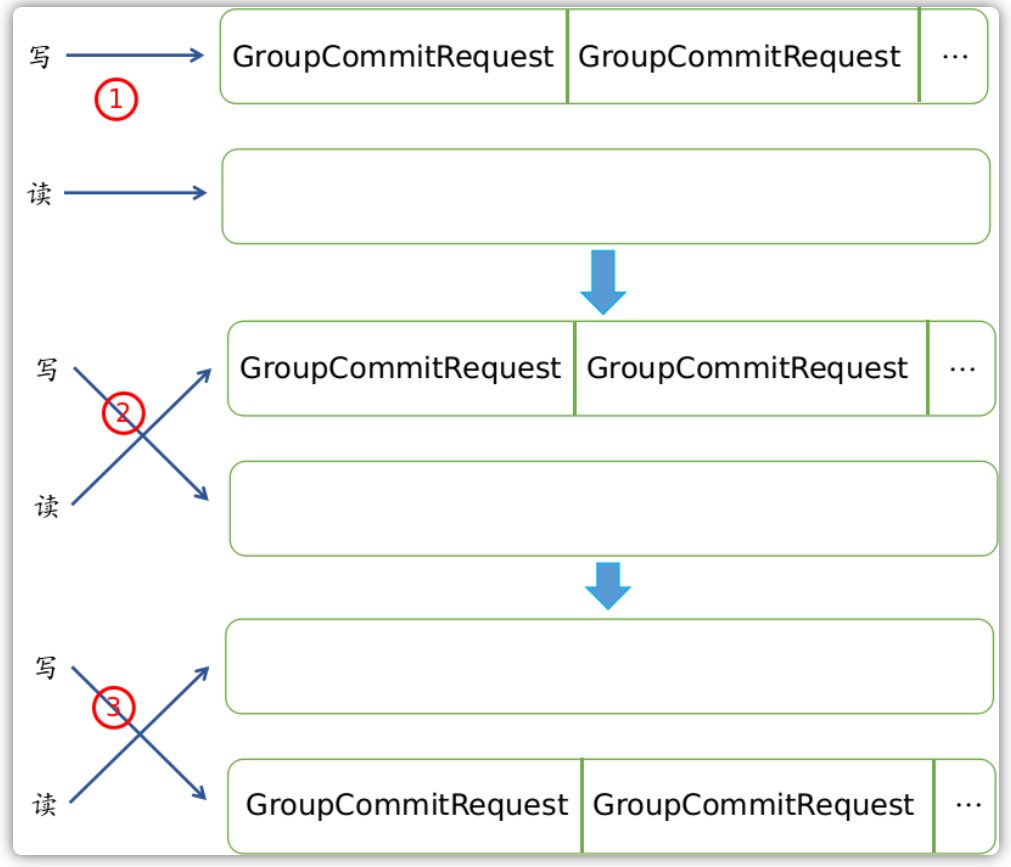
这里我们已经知道消息刷盘有同步刷盘和异步刷盘策略,对应的是GroupCommitService和FlushRealTimeService这两种不同的服务。这两种服务都有定时请求刷盘的机制,但是机制背后最终调用的方式都是flush方法:
public class MappedFileQueue {
public boolean flush(final int flushLeastPages) {
// ...
}
}
再继续向下分析这个方法之前,我们先对照这这张图说明一下使用MappedByteBuffer来简要阐述读和写文件的简单过程:
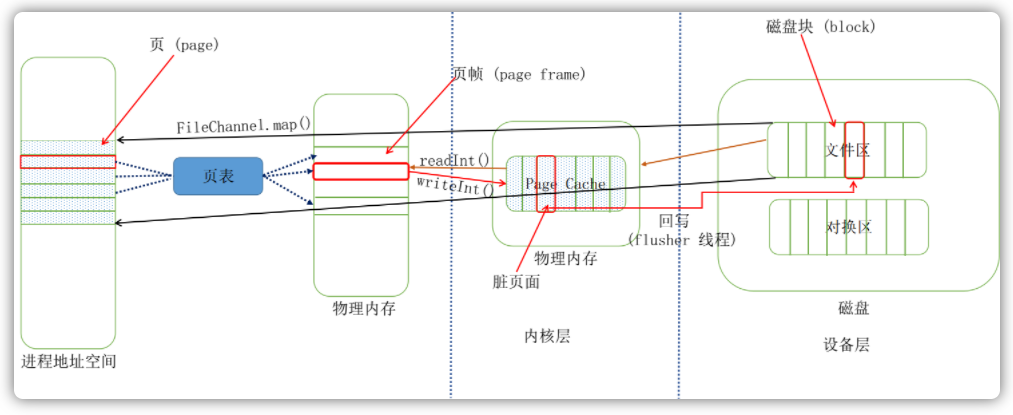
操作系统为了能够使多个进程同时使用内存,又保证各个进程访问内存互相独立,于是为每个进程引入了地址空间的概念,地址空间上的地址叫做虚拟地址,而程序想要运行必须放到物理地址上运行才可以。地址空间为进程营造了一种假象:“整台计算机只有我一个程序在运行,这台计算机内存很大”。一个地址空间内包含这个进程所需要的全部状态信息。通常一个进程的地址空间会按照逻辑分为好多段,比如代码段、堆段、栈段等。为了进一步有效利用内存,每一段又细分成了不同的页(Page)。与此相对对应,计算机的物理内存被切成了页帧(page frame),文件被分成了不同的页(Page)。与此相对应,计算机的物理内存被切成了页帧(Page frame),文件被分成了块(block)。既然程序实际运行的时候还是得依赖物理内存的地址,那么就需要将虚拟地址转换为物理地址,这个映射关系是由**页表(Page table)**来完成的。
另外在操作系统中,还有一层磁盘缓存(disk cache)的概念,它主要是用来减少对磁盘的I/O操作。磁盘缓存是以页为单位的,内容就是磁盘上的物理块,所以又称为页缓存(Page chae)。当进程发起一个读操作(比如,进行发起了一个read()系统调用),它首先会检查需要的数据是否在页缓存中。如果在,则放弃访问磁盘,而直接从页缓存中读取。如果数据没有在缓存中,那么内核必须调度块I/O操作从磁盘去读取数据,然后将读来的数据放入页缓冲中。系统并不一定要将整个文件都缓存,它可以只存储一个文件的一页或者几页。
如图所示,当调用FileChannel.map()方法的时候,会将这个文件映射进用户空间的地址空间中,注意,建立映射不会拷贝任何数据。我们前面提到过Broker启动的时候会有一个消息文件加载的过程,当第一次开始读取数据的时候:
// 首次读取数据
int totalSize = byteBuffer.getInt();
这个时候,操作系统通过查询页表,会发现文件的这部分数据还不在内存中。于是就会触发一个缺页异常(page faults),这个时候操作系统会开始从磁盘读取这一页数据,然后放入到页缓存中,然后再放入内存中。在第一次读取文件的时候,操作系统会读入所请求的页面,并读入紧随其后的少数几个页面(不少于一个页面,通常是三个页面),这时的预读称为同步预读(如下图所示,红色部分是需要读取的页面,蓝色的那三个框是操作系统预先读取的):
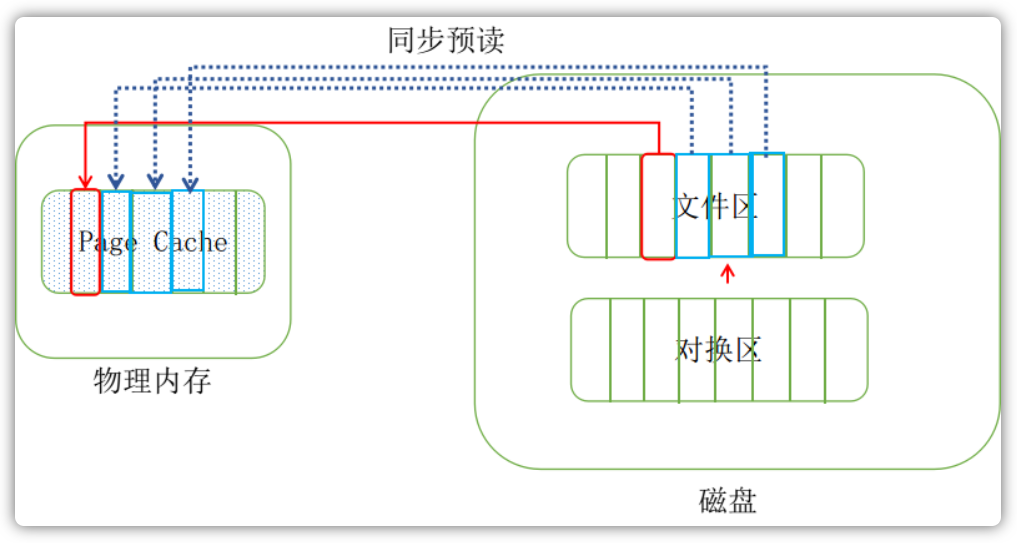
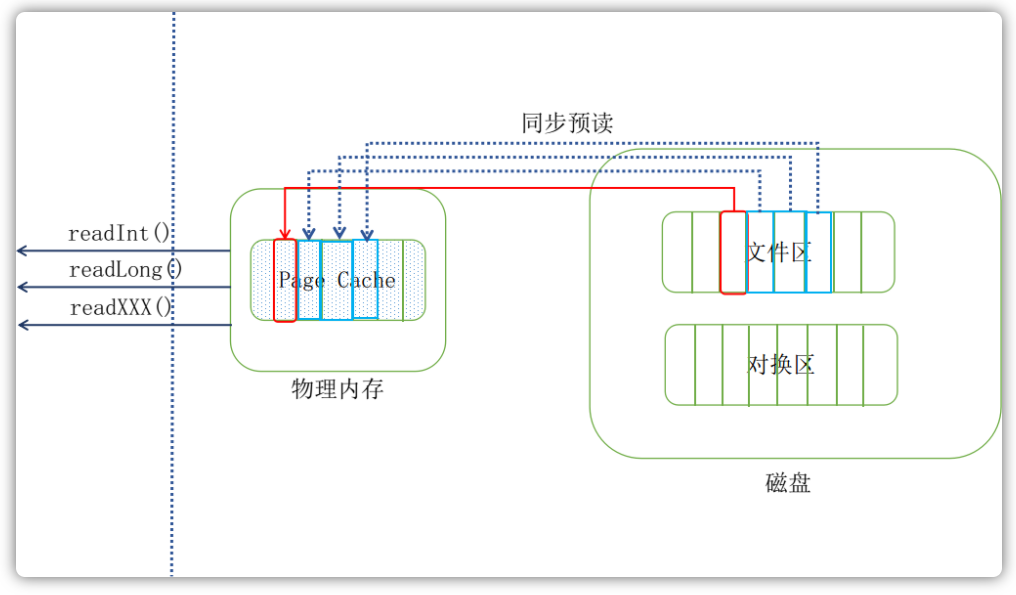
当随着时间推移,预读命中的话,那么相应的预读页面数量也会增加,但是能够确认的是,一个文件至少有4个页面处于页缓存中。当文件一直处于顺序读取的情况下,那么基本上可以保证每次预读命中:
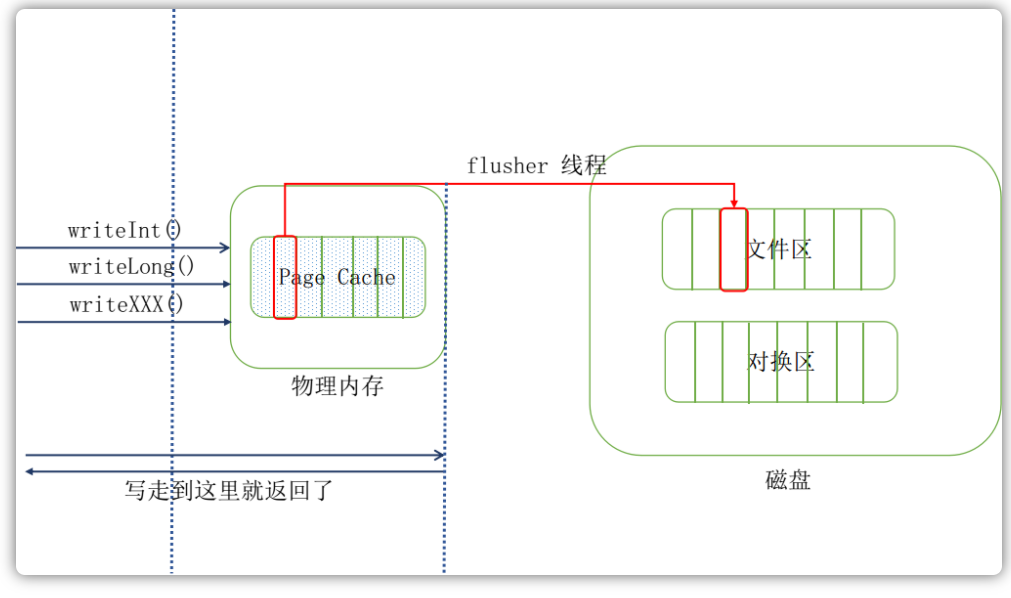
下面我们来说文件写,正常情况下,当尝试调用writeInt()写数据到文件里面的话,其写到页缓存层,这个方法就会返回了,这个时候数据还没有真正的保存到文件中去,Linux仅仅将页缓存中的这一页数据标记为“脏”,并且被加入到脏页链表中,然后由一群进程(flusher回写进程)周期性将脏页链表中的页写到磁盘,从而让磁盘中的数据和内存中保持一致,最后清理“脏”标识。在以下三种情况下,脏页会被写回磁盘:
- 空闲内存低于一个特定阈值
- 脏页在内存中驻留超过一个特定的阈值时
- 当用户进程调用sync()和fsync系统调用时
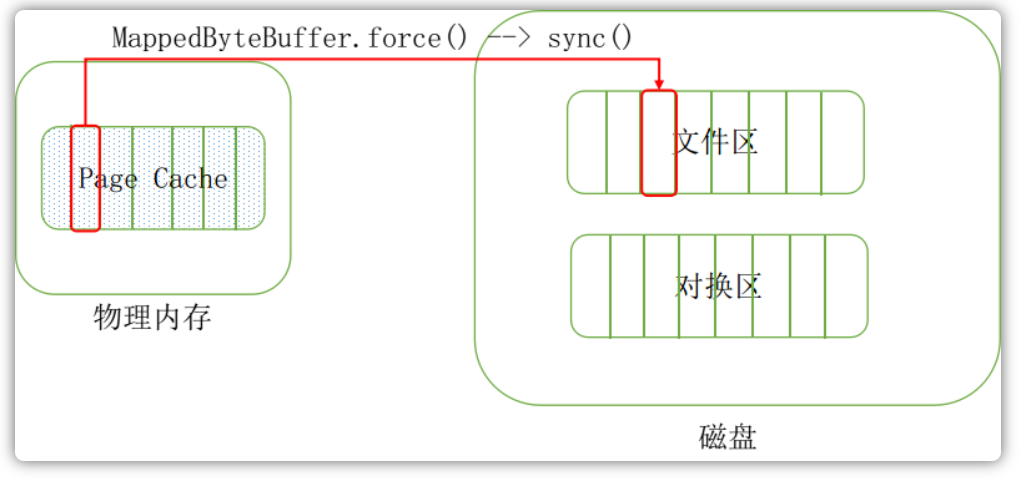
可见,在正常情况下,即使不采用刷盘策略,数据最终也是会被同步到磁盘中去的:
但是,即便由flusher线程来定时同步数据,如果此时机器断电的话,消息依然有可能丢失。RocketMQ为了保证消息尽可能的不丢失,为了最大的高可靠性,做了同步和异步刷盘策略,来手动进行同步:
在理解了消息刷盘背后的一些机制和理念后,我们再来分析刷盘的整个过程。首先,无论同步刷盘还是异步刷盘,其线程都在一直周期性的尝试执行刷盘,在真正执行刷盘函数的调用之前,Broker会检查文件的写位置是否大于flush位置,避免执行无意义的刷盘:
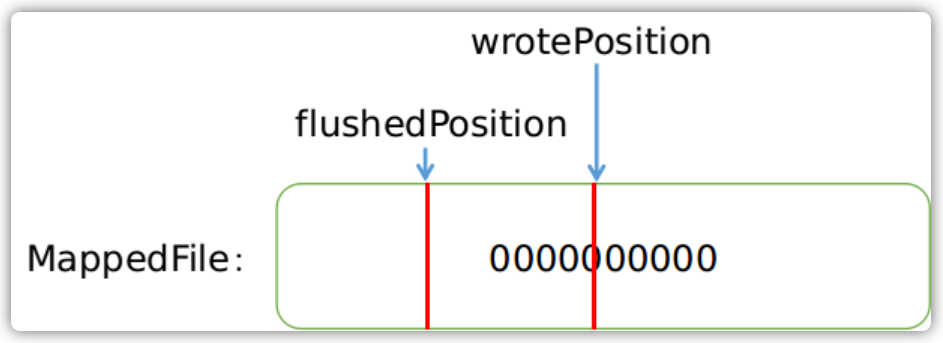
其次,对于异步刷盘来讲,Broker执行了更为严格的刷盘限制策略,当在某个时间点尝试执行刷盘之后,在接下来10秒内,如果想要继刷盘,那么脏页面数量必须不小于4页,如下图所示:
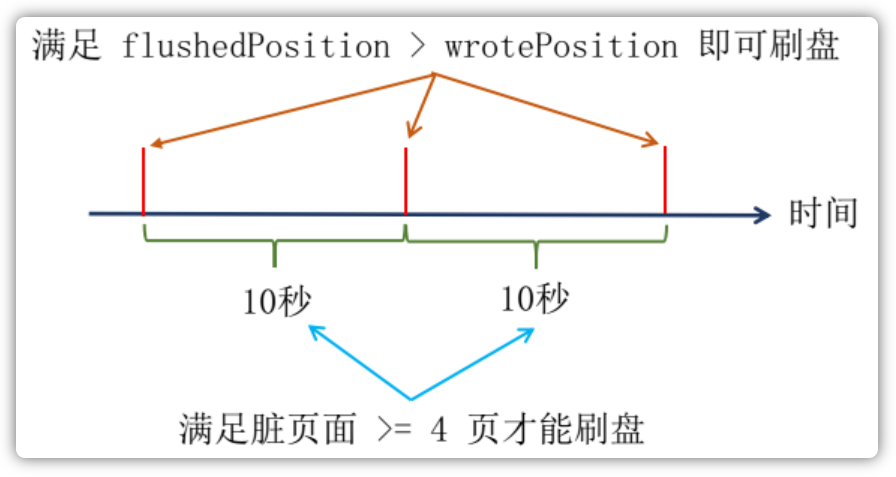
下面时执行刷盘前最后检查的刷盘条件:
public class MappedFile extends ReferenceResource {
private boolean isAbleToFlush(final int flushLeastPages) {
int flush = this.flushedPosition.get();
int write = getReadPosition();
if (this.isFull()) {
return true;
}
if (flushLeastPages > 0) {
// 计算当前脏页面算法
return ((write / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE)) >= flushLeastPages;
}
// wrotePosition > flushedPosition
return write > flush;
}
}
当刷盘完毕之后,首先会更新这个文件的flush位置,然后再更新MappedFileQueue的整体的flush位置:
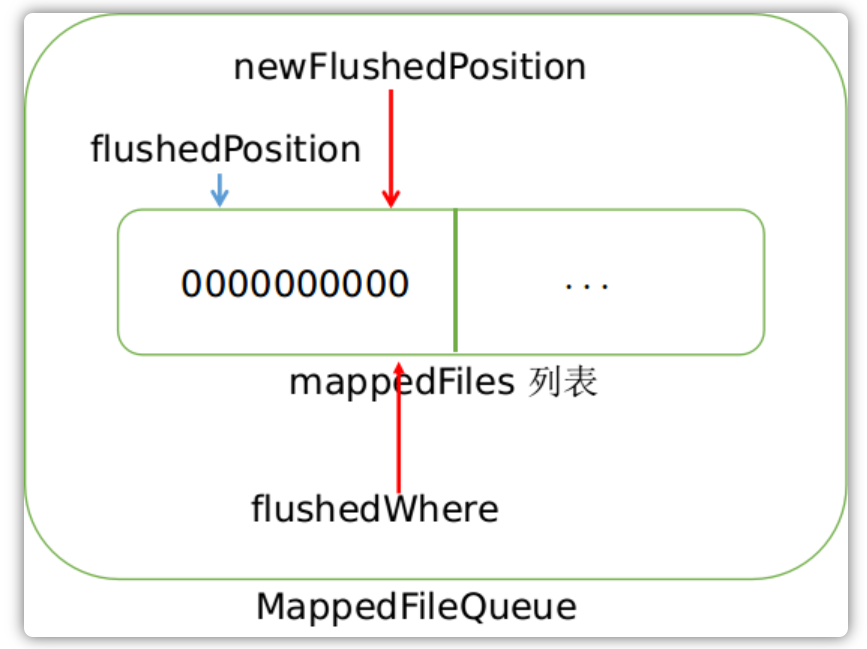
当刷盘完毕之后,便会将结果通知给客户端,告知发送消息成功,至此,整个存储过程完毕。
消息接收过程
消费者注册
生产者负责往服务器Broker发送消息,消费者则从Broker获取消息。消费者获取消息采用的订阅者模式,即消费者客户端可以订阅一个或者多个Topic来消费消息:
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
/*
* 订阅一个或者多个Topic
*/
consumer.subscribe("TopicTest", "*");
}
}
当消费者客户端启动以后,其会每隔30s从命名服务器查询一次用户订阅的所有topic路由信息:
public class MQClientInstance {
private void startScheduledTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 从命名服务器拉取话题信息
MQClientInstance.this.updateTopicRouteInfoFromNameServer();
}
}, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);
}
}
前面我们提到过,RocketMQ在发送消息的时候,每条消息会以轮询的方式均衡地分发到不同Broker的不同队列去。因此,消费者客户端从服务器获取下来的便是Topic的所有消息队列:

在获取话题路由信息的时候,客户端还会将Topic的路由信息中所有Broker地址保存到本地:
public class MQClientInstance {
public boolean updateTopicRouteInfoFromNameServer(final String topic,
boolean isDefault,
DefaultMQProducer defaultMQProducer) {
// ...
if (changed) {
TopicRouteData cloneTopicRouteData = topicRouteData.cloneTopicRouteData();
// 更新 Broker 地址列表
for (BrokerData bd : topicRouteData.getBrokerDatas()) {
this.brokerAddrTable.put(bd.getBrokerName(), bd.getBrokerAddrs());
}
return true;
}
// ...
}
}
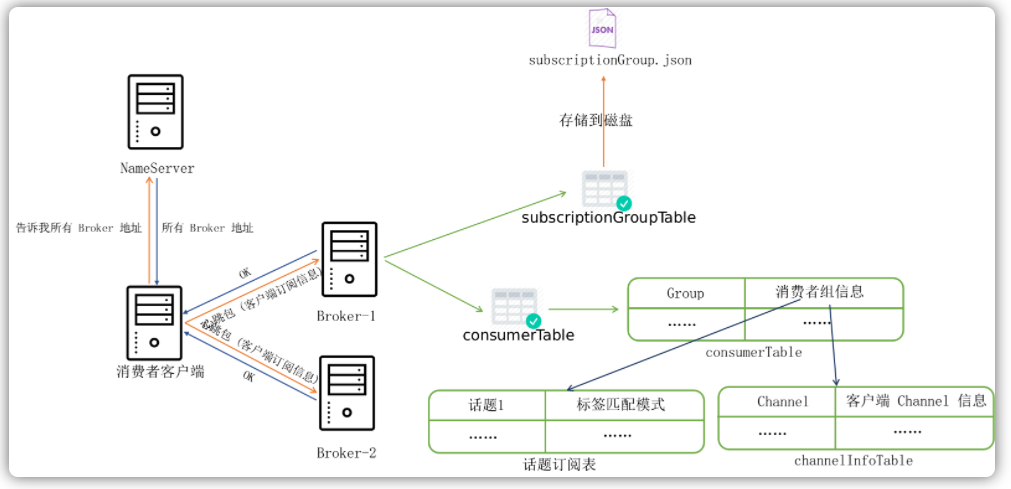
当消费者客户端获取到了Broker地址列表之后,其便会每隔30s给服务器发送一条心跳数据包,告知所有Broker服务器这台消费者客户端的存在。在每次发送心跳包的同时,其数据包内还会捎带这个客户端消息订阅的一些组信息,比如用户订阅了哪些topic等,与此相对应,每台Broker服务器会在内存中维护一份当前所有的消费者客户端列表信息:
public class ConsumerManager {
private final ConcurrentMap<String/* Group */, ConsumerGroupInfo> consumerTable =
new ConcurrentHashMap<String, ConsumerGroupInfo>(1024);
}
消费者客户端与 Broker 服务器进行沟通的整体流程如下图所示:
消息队列
我们知道无论发送消息还是接收消息都需要指定消息的topic,然后实际上消息在Broker服务器上并不是以topic为单位进行存储的,而是采用了比topic更细粒度的队列来进行存储的。当发送了10条相同topic的消息,这10条topic可能存储在了不同的Broker服务器的不同的队列中,因此,RokcetMQ管理消息的单位不是topic,而是队列。
当我们讨论消息队列负载均衡的时候,就是在讨论服务器端的所有队列如何给所有消费者消费的问题。在RocketMQ中,客户端有两种消费模式,一种是广播模式,另一种是集群模式。
我们现在假设总共有两台Broker服务器,假设用户使用Producer已经发送了8条消息,这8条消息现在均衡的分布在两台Broker服务器的8个队列中,每个队列中有一个消息。现在有3台都订阅了Test topic的消费者实例,我们来看在不同消费模式下,不同的消费者会收到那几条消息。
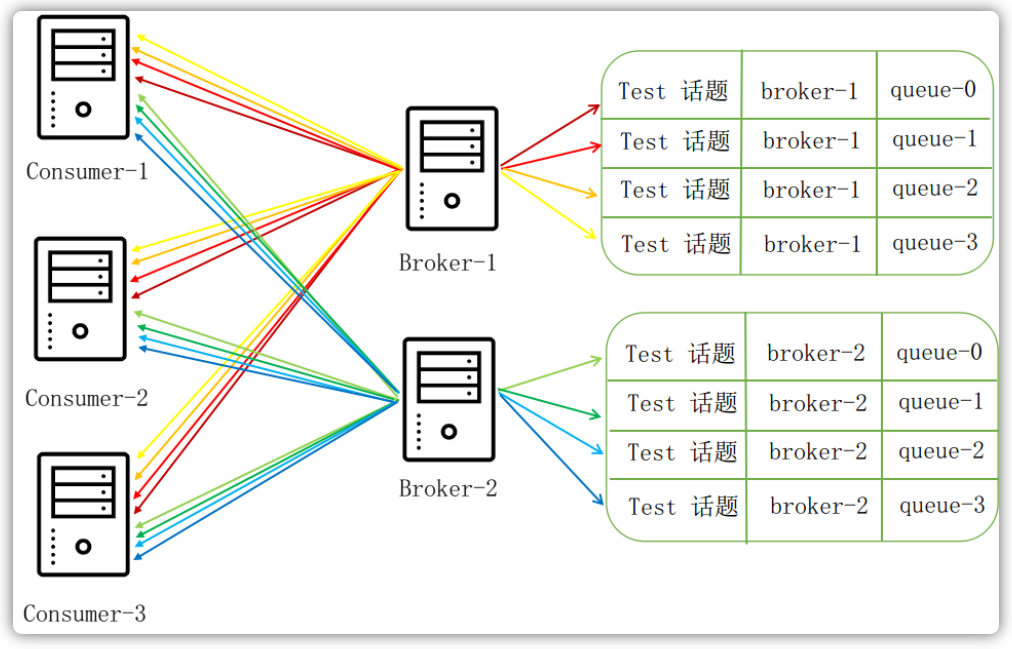
广播模式
广播模式是指所有消息队列中的消息都会广播给所有的消费者客户端,如下图所示,每一个消费者都能收到这8条消息:
集群模式
集群模式是指所有的消息队列会按照某种分配策略来分配给不同的消费者客户端,比如消费者A消费前3个队列中的消息,消费者B消费中间3个队列中的消息等等。RocketMQ为我们提供了三个比较重要的消息队列分配策略:
- 平均分配策略
- 平均分配轮询策略
- 一致性哈希策略
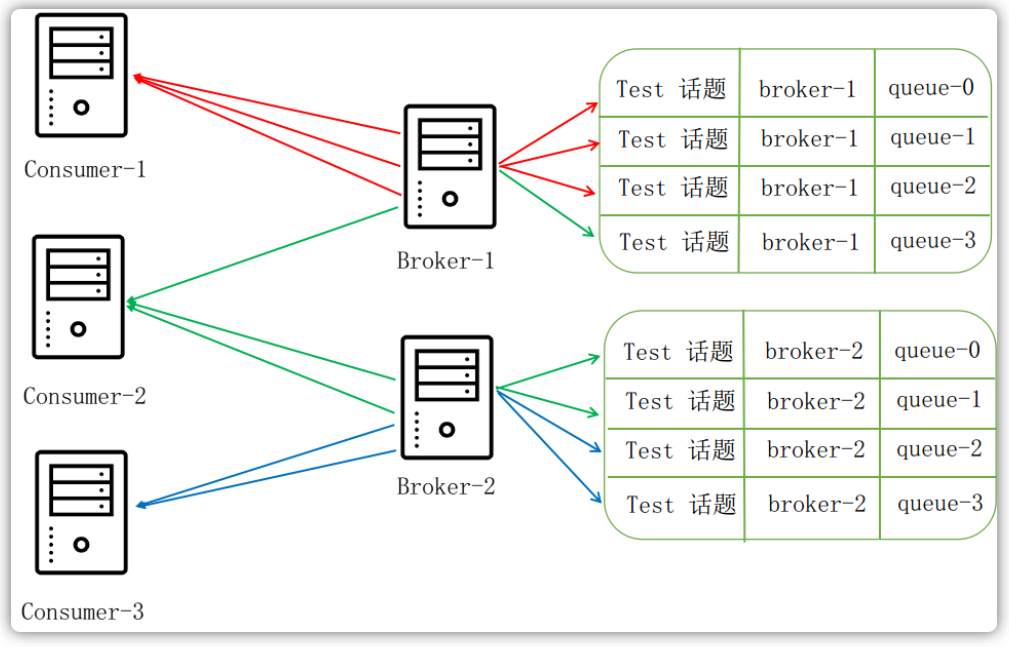
平均分配策略
在平均分配策略下,三个消费者的消费情况如下所示:
- Consumer-1消费前3个消息队列中的消息
- Consumer-2消费中间3个消息队列中的消息
- Consumer-3消费最后2个消息队列中的消息
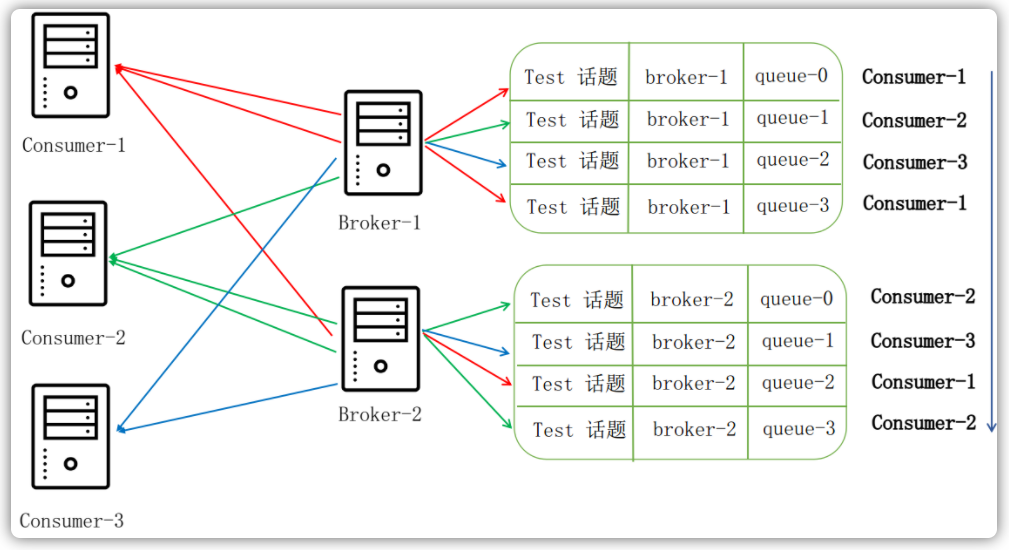
平均分配轮询策略
平均分配轮询策略下,三个消费者的消费情况如下所示:
- Consumer-1消费1、4、7消息队列中的消息
- Consumer-2消费2、5、8消息队列中的消息
- Consumer-3消费3、6消息队列中的消息
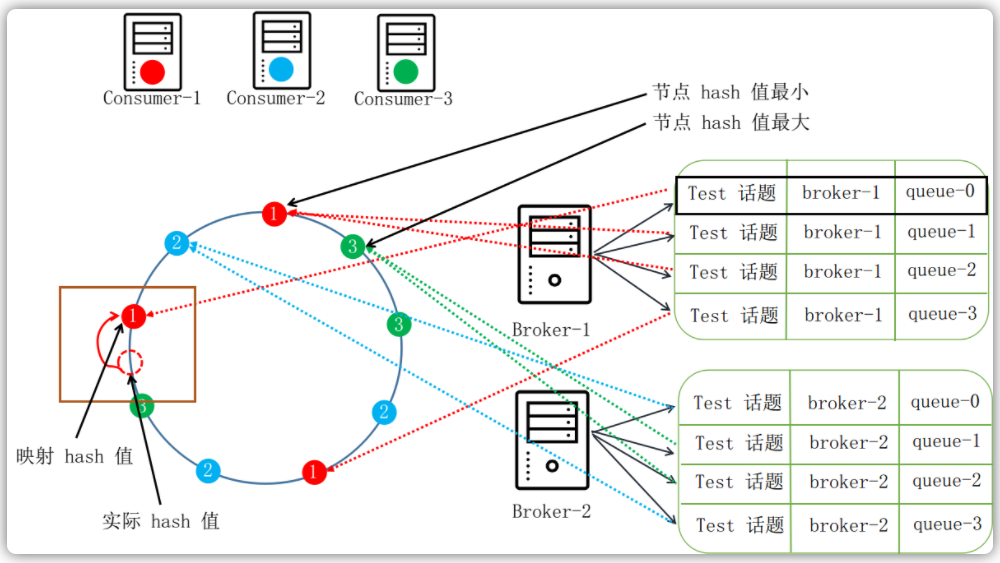
一致性哈希策略
一致性哈希算法是根据这三台消费者各自的某个有代表性的属性(我们假设就是客户端ID)来计算出Hash值,此处为了减少由于哈希函数选取不理想的情况,RocketMQ算法对于每个消费者通过在客户端ID后面添加1、2、3索引来使每一个消费者多生成几个哈希值。那么现在我们需要哈希的就是九个字符串:
- Consumer-1-1
- Consumer-1-2
- Consumer-1-3
- Consumer-2-1
- Consumer-2-2
- Consumer-2-3
- Consumer-3-1
- Consumer-3-2
- Consumer-3-3
计算完这9个哈希值以后,我们按照从到大的顺序来排列成一个环(如图所示)。这个时候我们需要对这个8个消息队列也计算一下哈希值,当哈希值落在两个圈之间的时候,我们就选取沿着环的方向的那个结点作为这个消息队列的消费者。如下图所示(注意:图只是示例,并非真正的消费情况):
消息队列的负载均衡是由一个不停运行的均衡服务来定时执行的:
public class RebalanceService extends ServiceThread {
// 默认 20 秒一次
private static long waitInterval =
Long.parseLong(System.getProperty("rocketmq.client.rebalance.waitInterval", "20000"));
@Override
public void run() {
while (!this.isStopped()) {
this.waitForRunning(waitInterval);
// 重新执行消息队列的负载均衡
this.mqClientFactory.doRebalance();
}
}
}
在广播模式下,当前这台消费者消费和Topic相关的所有消息队列,而集群模式会先按照某种分配策略来进行消息队列的分配,得到的结果就是当前这台消费者需要消费的消息队列:
public abstract class RebalanceImpl {
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
// 广播模式
case BROADCASTING: {
// 消费这个话题的所有消息队列
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
if (mqSet != null) {
// ...
}
break;
}
// 集群模式
case CLUSTERING: {
// ...
// 按照某种负载均衡策略进行消息队列和消费客户端之间的分配
// allocateResult 就是当前这台消费者被分配到的消息队列
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
// ...
}
break;
}
}
}
Broker消费队列
我们再来看Broker服务器端,首先我们应该知道,消息往Broker存储就是在向CommitLog消息文件中写入数据的一个过程。在Broker启动过程中,其会启动一个叫做ReputMessageService的服务,这个服务每隔1秒就会检查一下这个CommitLog是否有新的数据写入。ReputMessageService自身维护了一个偏移量reputFromOffset,用以对比和CommitLog文件中的消息总偏移量的差距。当这两个偏移量不同的时候,就代表有新的消息到来了:
class ReputMessageService extends ServiceThread {
private volatile long reputFromOffset = 0;
private boolean isCommitLogAvailable() {
// 看当前有没有新的消息到来
return this.reputFromOffset < DefaultMessageStore.this.commitLog.getMaxOffset();
}
@Override
public void run() {
while (!this.isStopped()) {
try {
Thread.sleep(1);
this.doReput();
} catch (Exception e) {
DefaultMessageStore.log.warn(this.getServiceName() + " service has exception. ", e);
}
}
}
}
在有新的消息到来之后,doReput函数会取出新到来的所有消息,每一条消息都会封装为一个DispatchRequest请求,进行将这条请求分发给不同的请求消费者,这里我们只关注利用消息创建消息队列的服务CommitLogDispatcherBuildConsumeQueue:
class ReputMessageService extends ServiceThread {
// ... 部分代码有删减
private void doReput() {
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
if (result != null) {
this.reputFromOffset = result.getStartOffset();
for (int readSize = 0; readSize < result.getSize() && doNext; ) {
// 读取一条消息,然后封装为 DispatchRequest
DispatchRequest dispatchRequest =
DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
int size = dispatchRequest.getMsgSize();
if (dispatchRequest.isSuccess()) {
// 分发这个 DispatchRequest 请求
DefaultMessageStore.this.doDispatch(dispatchRequest);
this.reputFromOffset += size;
readSize += size;
}
// ...
}
}
}
}
CommitLogDispatcherBuildConsumeQueue服务会根据这条请求按照不同的队列ID创建不同的消费队列文件,并在内存中维护一份消费队列列表。然后将DispatchRequest请求中这条消息的消息偏移量、消息大小以及消息在发送的时候附带的标签的哈希值写入到相应的消费队列文件中去。
寻找消费队列的代码如下:
public class DefaultMessageStore implements MessageStore {
private final ConcurrentMap<String/* topic */, ConcurrentMap<Integer/* queueId */, ConsumeQueue>> consumeQueueTable;
public void putMessagePositionInfo(DispatchRequest dispatchRequest) {
ConsumeQueue cq = this.findConsumeQueue(dispatchRequest.getTopic(), dispatchRequest.getQueueId());
cq.putMessagePositionInfoWrapper(dispatchRequest);
}
}
向消费队列文件中存储数据的代码如下:
public class ConsumeQueue {
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
final long cqOffset) {
// 存储偏移量、大小、标签码
this.byteBufferIndex.flip();
this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
this.byteBufferIndex.putLong(offset);
this.byteBufferIndex.putInt(size);
this.byteBufferIndex.putLong(tagsCode);
// 获取消费队列文件
final long expectLogicOffset = cqOffset * CQ_STORE_UNIT_SIZE;
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(expectLogicOffset);
if (mappedFile != null) {
// ...
return mappedFile.appendMessage(this.byteBufferIndex.array());
}
return false;
}
}
以上阐述了消费队列创建并存储消息的一个过程,但是消费队列中的消息是需要持久化到磁盘中去的。持久化的过程是通过后台服务FlushConsumeQueueService来定时持久化的:
class FlushConsumeQueueService extends ServiceThread {
private void doFlush(int retryTimes) {
// ...
ConcurrentMap<String, ConcurrentMap<Integer, ConsumeQueue>> tables = DefaultMessageStore.this.consumeQueueTable;
for (ConcurrentMap<Integer, ConsumeQueue> maps : tables.values()) {
for (ConsumeQueue cq : maps.values()) {
boolean result = false;
for (int i = 0; i < retryTimes && !result; i++) {
// 刷新到磁盘
result = cq.flush(flushConsumeQueueLeastPages);
}
}
}
// ...
}
}
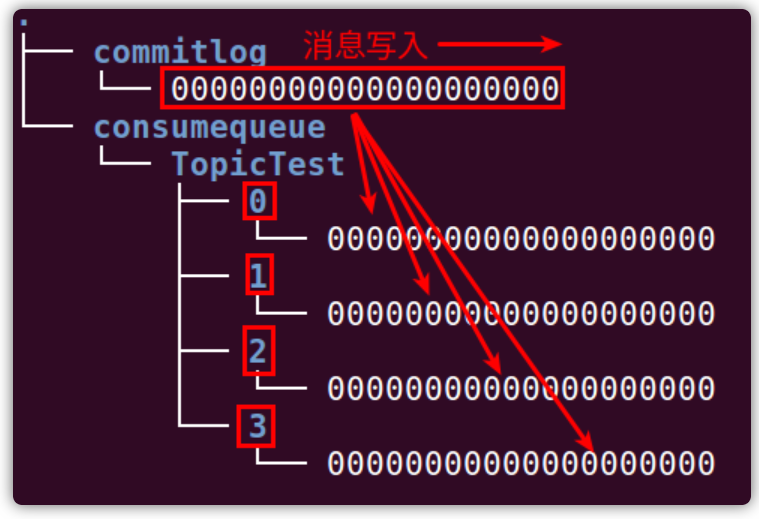
上述过程体现在磁盘文件的变化如下图所示,commitLog文件夹下面存放的是完整的消息,来一条消息,向文件中追加一条消息。同时,根据这一条消息属于TopicTest Topic下的哪一个队列,又会往相应的consumequeue文件下的相应消费队列文件中追加消息的偏移量、消息大小和标签码:
总流程图如下所示:
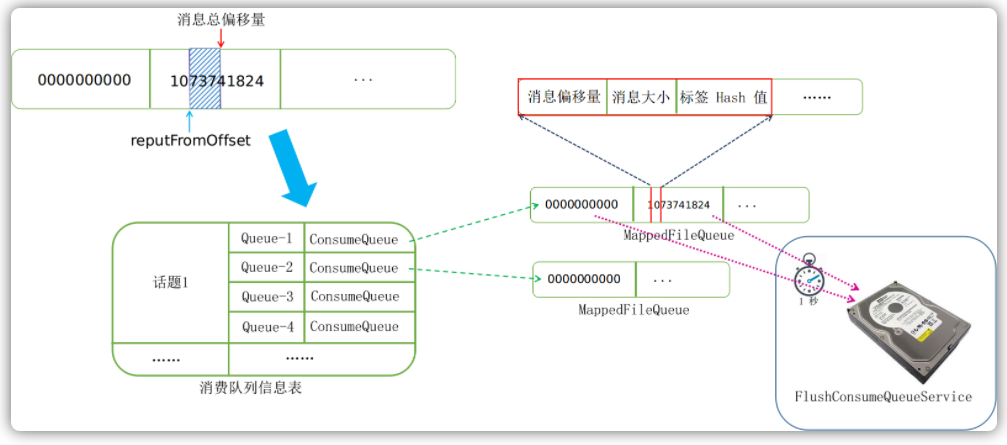
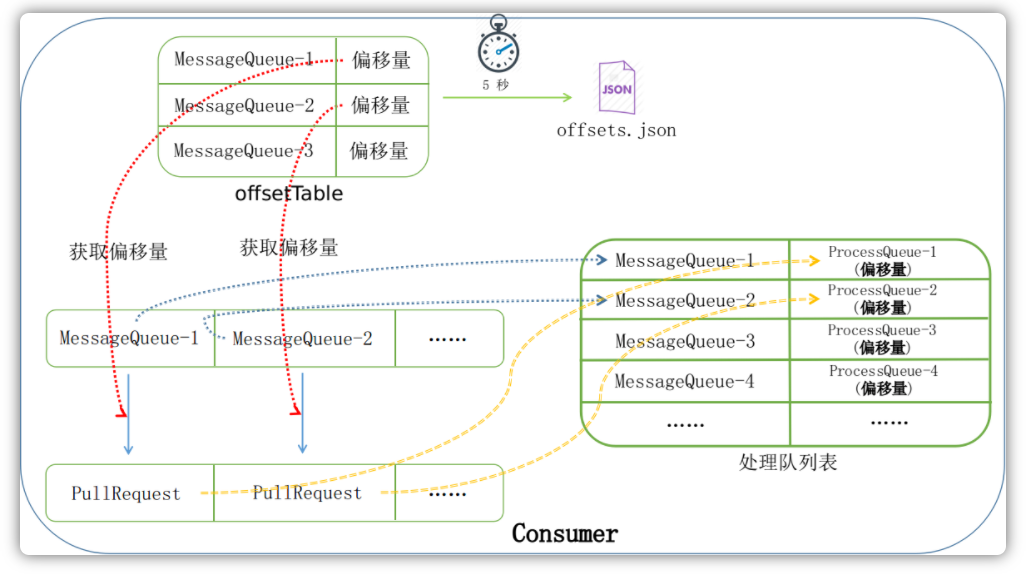
Broker服务器存储了各个消息队列,客户端需要消费每隔消费队列中的消息。消费模式的不同,每个客户端所消费的消息队列也不同,那么客户端如何记录自己所消费得队列消费到哪里了呢?答案就是消费队列偏移量。
针对同一个Topic,在集群模式下,由于每个客户端所消费的消息队列不同,所以每个消息队列已经消费到哪里的消费偏移量是记录在Broker服务器端的。而在广播模式下,由于每个客户端分配消费这个Topic的所有消息队列,所以每个消息队列已经消费到哪里的消费偏移量是记录在客户端本地的。
下面分别讲述两种模式下偏移量是如何获取和更新的。
集群模式
在集群模式下,消费者客户端在内存中维护了一个offsetTable表:
public class RemoteBrokerOffsetStore implements OffsetStore {
private ConcurrentMap<MessageQueue, AtomicLong> offsetTable =
new ConcurrentHashMap<MessageQueue, AtomicLong>();
}
同样在Broker服务器端也维护了一个偏移量表:
public class ConsumerOffsetManager extends ConfigManager {
private ConcurrentMap<String/* topic@group */, ConcurrentMap<Integer, Long>> offsetTable =
new ConcurrentHashMap<String, ConcurrentMap<Integer, Long>>(512);
}
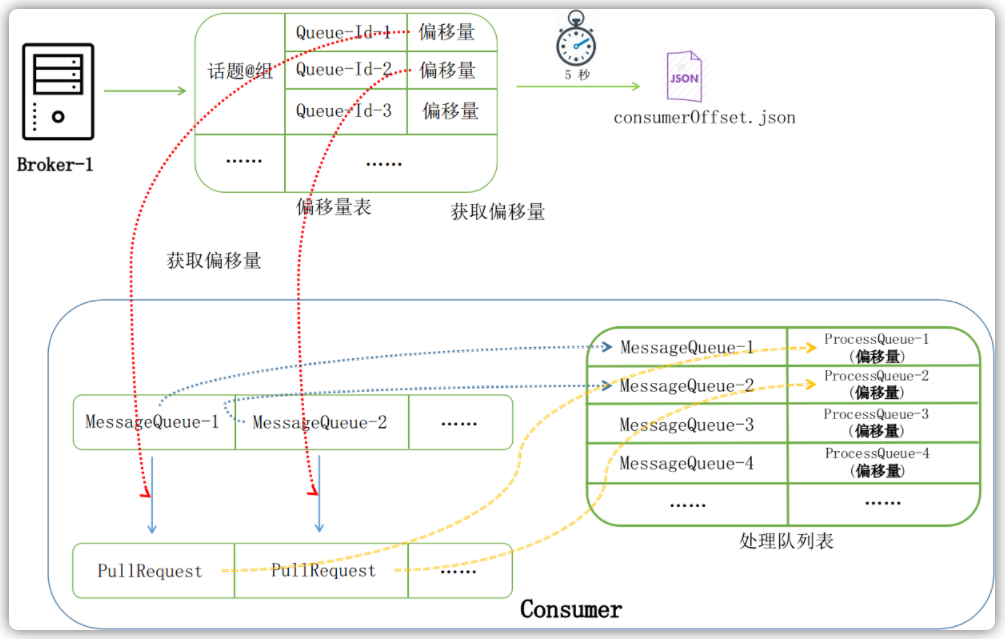
在消费者客户端,RebalanceService服务会定时地(默认20秒)从Broker服务器获取当前客户端所需要消费的消息队列,并于当前消费客户端的消费队列进行对比,看是否有变化。对于每个消费队列,会从Broker服务器查询这个队列当前的消费偏移量。然后根据这几个消费队列,创建对应的拉取请求PullRequest准备从Broker服务器拉取消息,如下图所示:
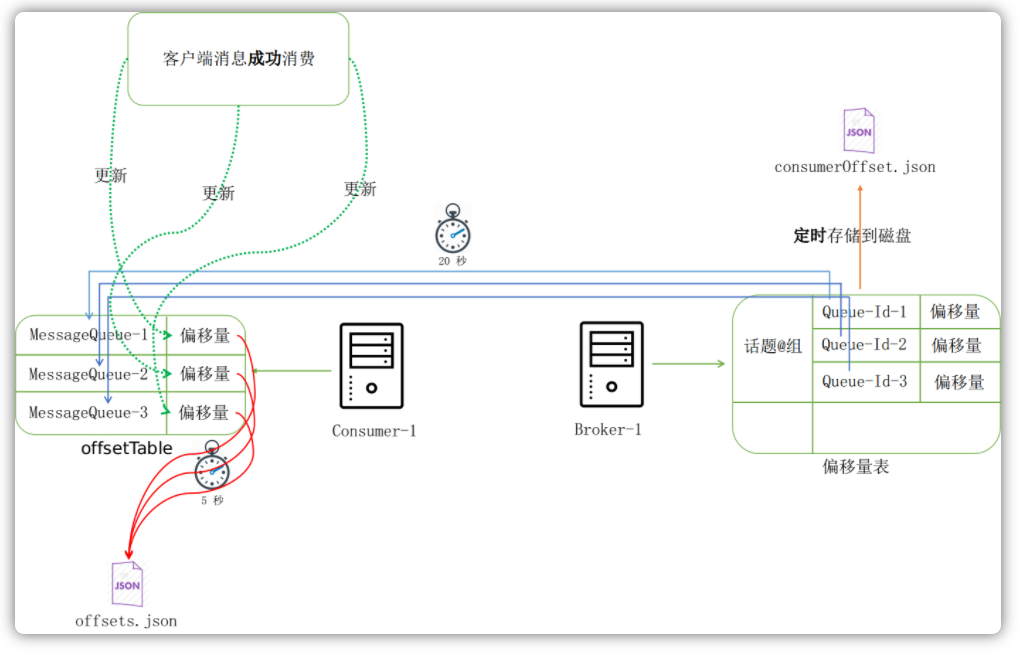
当从Broker服务器拉取下来消息以后,只有当用户成功消费的时候,才会更新本地的偏移量表。本地的偏移量表再通过定时服务每隔5s同步到Broker服务器端:
public class MQClientInstance {
private void startScheduledTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
MQClientInstance.this.persistAllConsumerOffset();
}
}, 1000 * 10, this.clientConfig.getPersistConsumerOffsetInterval(), TimeUnit.MILLISECONDS);
}
}
而维护在 Broker 服务器端的偏移量表也会每隔 5 秒钟序列化到磁盘中:
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
BrokerController.this.consumerOffsetManager.persist();
}
}, 1000 * 10, this.brokerConfig.getFlushConsumerOffsetInterval(), TimeUnit.MILLISECONDS);
}
}
保存的格式如下:

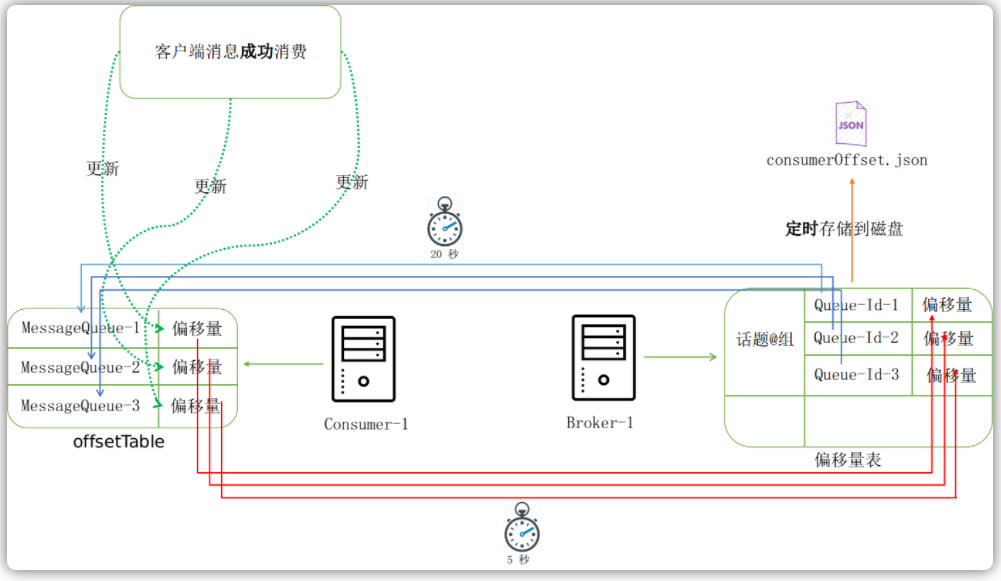
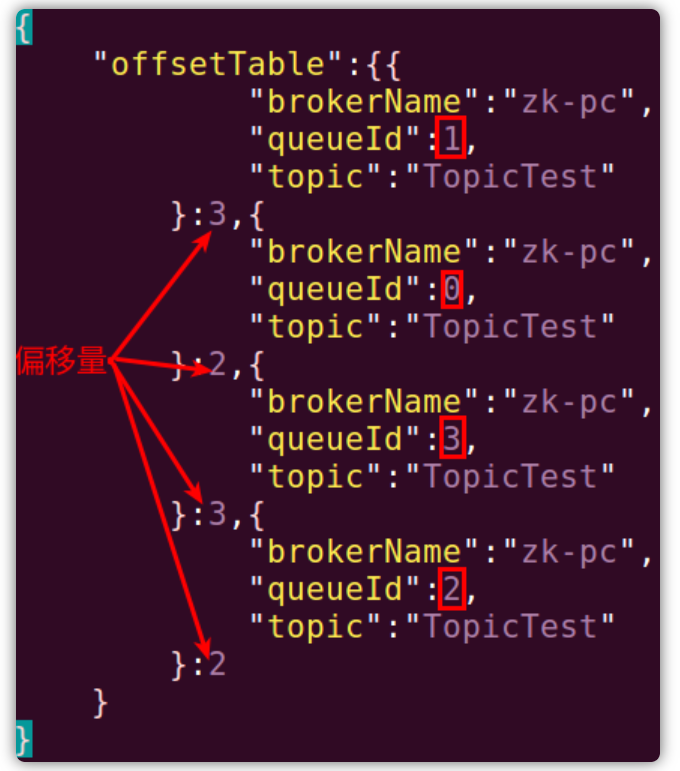
上述整体流程如下所示,红框框住的是这个Topic下面的队列的id,箭头指向的分别是每个队列的消费偏移量:
广播模式
对于广播模式而言,每个消费队列的偏移量肯定不能存储在Broker服务器端,因为多个消费者对于同一个队列的消费可能是不一致的,偏移量会互相覆盖掉。因此,在广播模式下,每个客户端的消费偏移量是存储在本地的,然后每隔5将内存中的offsetTable持久化到磁盘中。当首次从服务器获取可消费队列的时候,偏移量不像集群模式下是从Broker服务器读取的,而是直接从本地文件读取的:
public class LocalFileOffsetStore implements OffsetStore {
@Override
public long readOffset(final MessageQueue mq, final ReadOffsetType type) {
if (mq != null) {
switch (type) {
case READ_FROM_STORE: {
// 本地读取
offsetSerializeWrapper = this.readLocalOffset();
// ...
}
}
}
// ...
}
}
当消息消费成功后,偏移量的更新也是持久化到本地,而非更新到Broker服务器中。在广播模式下,消息队列的偏移量默认是放在用户目录下的.rocketmq_offsets目录下:
public class LocalFileOffsetStore implements OffsetStore {
@Override
public void persistAll(Set<MessageQueue> mqs) {
// ...
String jsonString = offsetSerializeWrapper.toJson(true);
MixAll.string2File(jsonString, this.storePath);
// ...
}
}
存储格式如下:
简要流程如下:
消费消息
RocketMQ在客户端运行着一个专门用来拉取消息的后台服务PullMessageService,其接受每个队列创建PullRequest拉取消息请求,然后拉取消息:
public class PullMessageService extends ServiceThread {
@Override
public void run() {
while (!this.isStopped()) {
PullRequest pullRequest = this.pullRequestQueue.take();
if (pullRequest != null) {
this.pullMessage(pullRequest);
}
}
}
}
每一个PullRequest都关联着一个MessageQueue和一个ProcessQueue,在ProcessQueue的内部还维护了一个用来等待用户消费的消息树,如下代码所示:
public class PullRequest {
private MessageQueue messageQueue;
private ProcessQueue processQueue;
}
public class ProcessQueue {
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();
}
当真正尝试拉取消息之前,其会检查当前请求的内部缓存的消息数量、消息大小、消息阈值跨度是否超过了某个阈值,如果超过某个阈值,则推迟50毫秒重新执行这个请求:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public void pullMessage(final PullRequest pullRequest) {
// ...
final ProcessQueue processQueue = pullRequest.getProcessQueue();
long cachedMessageCount = processQueue.getMsgCount().get();
long cachedMessageSizeInMiB = processQueue.getMsgSize().get() / (1024 * 1024);
// 缓存消息数量阈值,默认为 1000
if (cachedMessageCount > this.defaultMQPushConsumer.getPullThresholdForQueue()) {
this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
return;
}
// 缓存消息大小阈值,默认为 100 MB
if (cachedMessageSizeInMiB > this.defaultMQPushConsumer.getPullThresholdSizeForQueue()) {
this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
return;
}
if (!this.consumeOrderly) {
// 最小偏移量和最大偏移量的阈值跨度,默认为 2000 偏移量,消费速度不能太慢
if (processQueue.getMaxSpan() > this.defaultMQPushConsumer.getConsumeConcurrentlyMaxSpan()) {
this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
return;
}
}
// ...
}
}
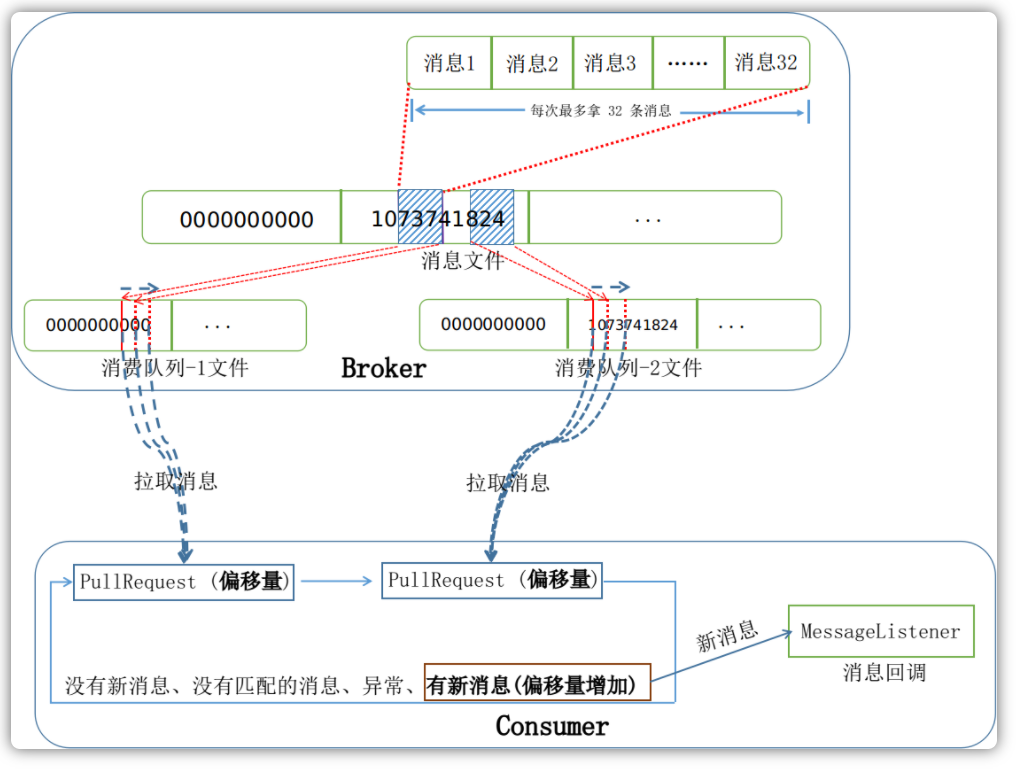
当执行完一些必要的检查之后,客户端会将用户指定的过滤信息以及一些其它必要消费字段封装到请求信息体中,然后才开始从Broker服务器拉取这个请求从当前偏移量开始的消息,默认一次性最多拉取32条,服务器返回的响应会告诉客户端这个队列下次开始拉取时的偏移量。客户端每次都会注册一个PullCallback回调,用以接收服务器返回的响应信息,根据响应信息的不同状态信息,然后修正这个请求的偏移量,并进行下次请求:
public void pullMessage(final PullRequest pullRequest) {
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
// ...
switch (pullResult.getPullStatus()) {
case FOUND:
// ...
break;
case NO_NEW_MSG:
// ...
break;
case NO_MATCHED_MSG:
// ...
break;
case OFFSET_ILLEGAL:
// ...
break;
default:
break;
}
}
}
@Override
public void onException(Throwable e) {
// ...
}
};
}
上述是客户端拉取消息时的一些机制,现在再说一下Broker服务器端于此相对应的逻辑。
服务器在收到客户端的请求之后,会根据Topic和队列ID定位到对应的消费队列。然后根据这条请求传入的offset消费队列偏移量,定位到对应的消费队列文件。偏移量指定的是消费队列文件的消费下限,而最大上限是由如下算法来进行约束的:
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
有了上限和下限,客户端便会开始从消费队列文件中取出每个消息的偏移量和消息大小,然后再根据这两个值去CommitLog文件中寻找相应的完整的消息,并添加到最后的消息队列中,精简过的代码如下所示:
public class DefaultMessageStore implements MessageStore {
public GetMessageResult getMessage(final String group, final String topic, final int queueId, final long offset,
final int maxMsgNums,
final MessageFilter messageFilter) {
// ...
ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId);
if (consumeQueue != null) {
// 首先根据消费队列的偏移量定位消费队列
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
if (bufferConsumeQueue != null) {
try {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
// 最大消息长度
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
// 取消息
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
// 根据消息的偏移量和消息的大小从 CommitLog 文件中取出一条消息
SelectMappedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy);
getResult.addMessage(selectResult);
status = GetMessageStatus.FOUND;
}
// 增加下次开始的偏移量
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
} finally {
bufferConsumeQueue.release();
}
}
}
// ...
}
}
客户端和 Broker 服务器端完整拉取消息的流程图如下所示:
根据用户指定的消息回调函数的不同,消息的消费方式可以分为两种:并发消费和有序消费。
并发消费没有考虑消息发送的顺序,客户端从服务器获取消息就会直接回调给用户。而有序消费会考虑每个队列消息发送的顺序,注意此处并不是每个Topic消息发送的顺序,一定要记住RocketMQ控制消息的最细粒度是消息队列。当我们讲有序消费的时候,就是在说对于某个Topic的某个队列,发往这个队列的消息,客户端接收消息的顺序与发送的顺序完全一致。
并发消费
当用户注册消息回调类的时候,如果注册的是MessageListenerConcurrently回调类,那么就认为用户不关心消息的顺序问题。上文提到,每个PullRequest都关联了一个处理队列ProcessQueue,而每个处理队列又都关联了一颗消息树msgTreeMap。当客户端拉取到新的消息以后,其先将消息放入到这个请求所关联的处理队列的消息树中,然后提交一个消息消费请求,用以回调用户端的代码消费消息:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public void pullMessage(final PullRequest pullRequest) {
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
switch (pullResult.getPullStatus()) {
case FOUND:
// 消息放入处理队列的消息树中
boolean dispathToConsume = processQueue
.putMessage(pullResult.getMsgFoundList());
// 提交一个消息消费请求
DefaultMQPushConsumerImpl.this
.consumeMessageService
.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispathToConsume);
break;
}
}
}
};
}
}
当提交一个消息消费请求后,对于并发消费,其实现如下:
public class ConsumeMessageConcurrentlyService implements ConsumeMessageService {
class ConsumeRequest implements Runnable {
@Override
public void run() {
// ...
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
// ...
}
}
}
我们可以看到msgs是直接从服务器端拿到的最新消息,直接喂给了客户端进行消费,并未做任何有序处理。当消费成功后,会从消息树中将这些消息再给删除掉:
public class ConsumeMessageConcurrentlyService implements ConsumeMessageService {
public void processConsumeResult(final ConsumeConcurrentlyStatus status, /** 其它参数 **/) {
// 从消息树中删除消息
long offset = consumeRequest.getProcessQueue().removeMessage(consumeRequest.getMsgs());
if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {
this.defaultMQPushConsumerImpl.getOffsetStore()
.updateOffset(consumeRequest.getMessageQueue(), offset, true);
}
}
}
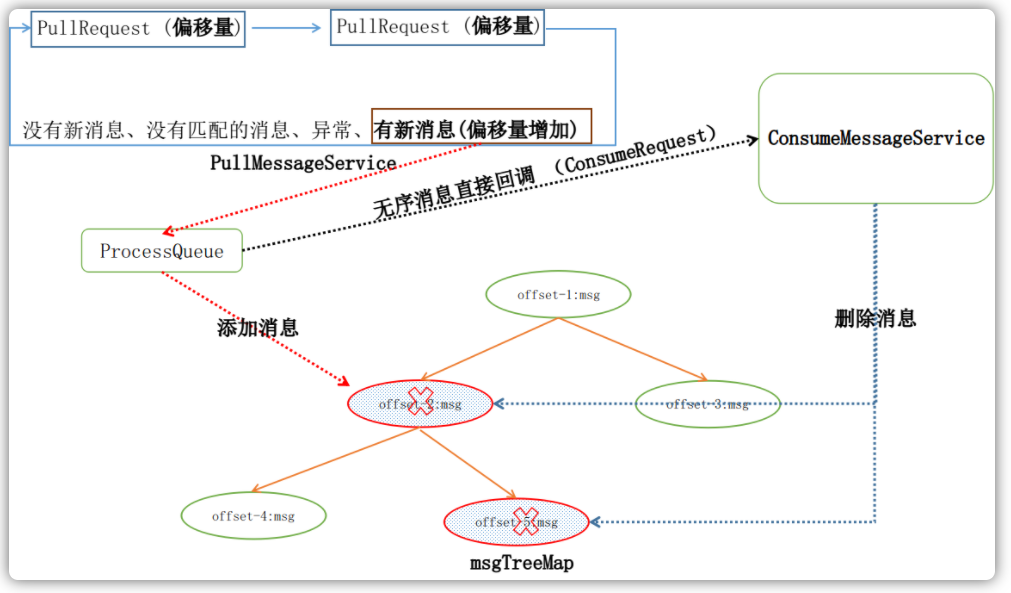
有序消费
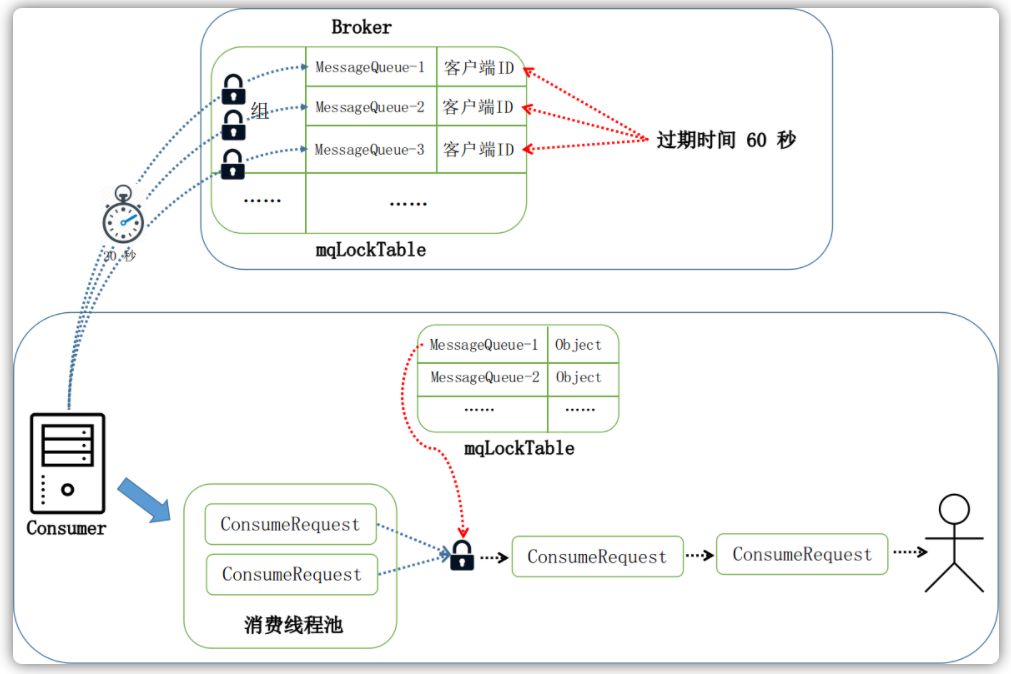
RocketMQ的有序消费主要依靠两把锁,一把是维护在Broker端,一把维护在消费者客户端。Broker端有一个RebalanceLockManager服务,其内部维护了一个mqLockTable消息队列锁表:
public class RebalanceLockManager {
private final ConcurrentMap<String/* group */, ConcurrentHashMap<MessageQueue, LockEntry>> mqLockTable =
new ConcurrentHashMap<String, ConcurrentHashMap<MessageQueue, LockEntry>>(1024);
}
在有序消费的时候,Broekr需要确保任何一个队列在任何时候都只有一个客户端在消费它,都在被一个客户端所锁定。当客户端在本地根据消息队列构建PullRequest之前,会与Broker沟通尝试锁定这个队列,另外当进行有序消费的时候,客户端也会周期性地(默认是20s)锁定当前需要消费的消息队列:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
public void start() {
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())) {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
ConsumeMessageOrderlyService.this.lockMQPeriodically();
}
}, 1000 * 1, ProcessQueue.REBALANCE_LOCK_INTERVAL, TimeUnit.MILLISECONDS);
}
}
}
只有在集群模式下才会周期性地锁定Broker端的消息队列,因此在广播模式下是不支持进行有序消费的。
在Broker这端,每个客户端所锁定的消息队列对应的锁项LogEntry有一个上次锁定是的时间戳,当超过锁定的超时时间(默认是60s)后,也会判定这个客户端已经不再持有这把锁,以让其它客户端能够有序消费这个队列。
前面我们说到RebalanceService均衡服务会定时地依据不同消费者数量分配消费队列。我们假设Consumer-1消费者客户端一开始需要3个消费队列,这个时候又加入了Consumer-2消费者客户端,并且分配到了MessageQueue-2消费队列。当Consumer-1内部的均衡服务检测到当前队列需要移除MessageQueue-2队列,这个时候,会首先解除Broker端的锁,确保新加入的Consumer-2消费者客户端能够成功锁住这个队列,以进行有序消费。
public abstract class RebalanceImpl {
private boolean updateProcessQueueTableInRebalance(final String topic,
final Set<MessageQueue> mqSet,
final boolean isOrder) {
while (it.hasNext()) {
// ...
if (mq.getTopic().equals(topic)) {
// 当前客户端不需要处理这个消息队列了
if (!mqSet.contains(mq)) {
pq.setDropped(true);
// 解锁
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
// ...
}
}
// ...
}
}
}
}
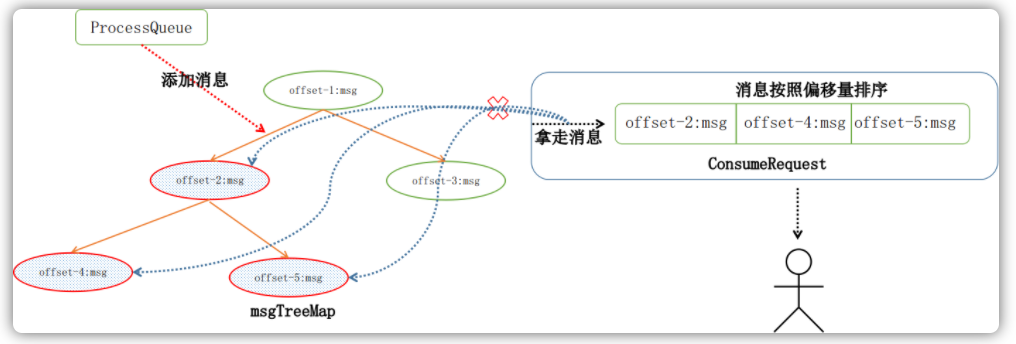
RocketMQ的消息树是用TreeMap实现的,其内部基于消息偏移量维护了消息的有序性。每次消费请求都会从消息树中拿去偏移量最小的几条消息(默认为1条)给用户,以此来达到有序消费的目的:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
class ConsumeRequest implements Runnable {
@Override
public void run() {
// ...
final int consumeBatchSize =
ConsumeMessageOrderlyService.this
.defaultMQPushConsumer
.getConsumeMessageBatchMaxSize();
List<MessageExt> msgs = this.processQueue.takeMessags(consumeBatchSize);
}
}
}
消息过滤过程
消息过滤类型
Producer在发送消息的时候可以指定消息的标签类型,还可以为每一个消息添加一个或者多个额外的属性:
// 指定标签
Message msg = new Message("TopicTest", "TagA", ("Hello RocketMQ").getBytes(RemotingHelper.DEFAULT_CHARSET));
// 添加属性 a
msg.putUserProperty("a", 5);
根据标签和属性的不同,RocketMQ客户端在消费消息的时候有三种消息过滤的类型:
Tag过滤
consumer.subscribe("TopicTest", "TagA | TagB | TagC");SQL匹配
consumer.subscribe("TopicTest", MessageSelector.bySql( "(TAGS is not null and TAGS in ('TagA', 'TagB'))" + "and (a is not null and a between 0 3)"));自定义匹配
客户端实现
MessageFilter类,自定义过滤逻辑:ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); File classFile = new File(classLoader.getResource("MessageFilterImpl.java").getFile()); String filterCode = MixAll.file2String(classFile); consumer.subscribe("TopicTest", "org.apache.rocketmq.example.filter.MessageFilterImpl",filterCode);对于
MessageFilter类实现match方法即可:public class MessageFilterImpl implements MessageFilter { @Override public boolean match(MessageExt msg, FilterContext context) { String property = msg.getProperty("SequenceId"); if (property != null) { int id = Integer.parseInt(property); if (((id % 10) == 0) && (id > 100)) { return true; } } return false; } }
标签匹配
当为消息指定消息标签类型的时候,实际上所指定的标签例如TagA是作为一个属性放入到了这条消息中的:
public class Message implements Serializable {
public void setTags(String tags) {
this.putProperty(MessageConst.PROPERTY_TAGS, tags);
}
}
当这条消息到达Broker服务器端后,用户设置的标签会计算为标签码,默认的计算方式采用的标签字符串的hashCode()作为计算结果的:
public class CommitLog {
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer,
final boolean checkCRC,
final boolean readBody) {
// ...
String tags = propertiesMap.get(MessageConst.PROPERTY_TAGS);
if (tags != null && tags.length() > 0) {
tagsCode = MessageExtBrokerInner
.tagsString2tagsCode(MessageExt.parseTopicFilterType(sysFlag), tags);
}
// ...
}
}
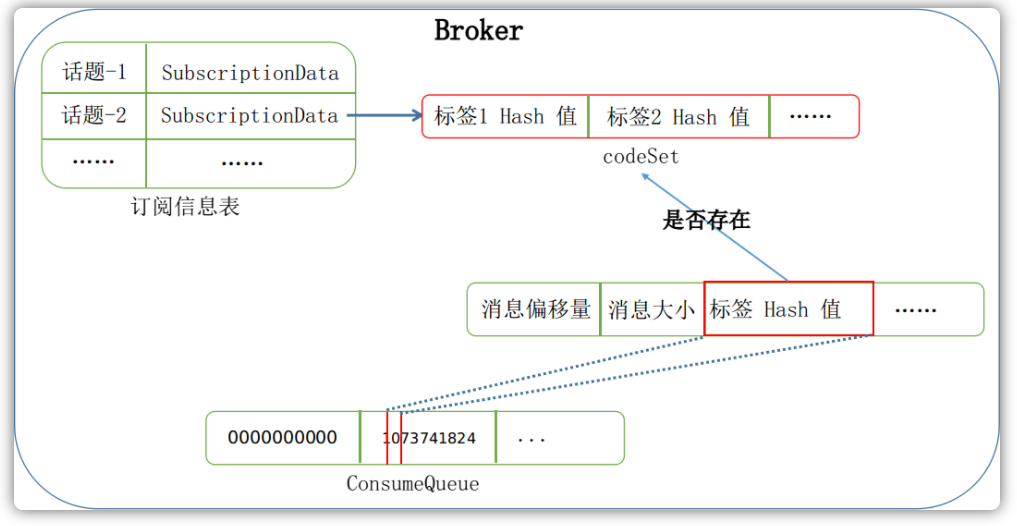
当计算出来标签码之后,这条消息的标签码会被存放到消息队列文件中,用来与消费者客户端消费队列的标签码进行匹配。消费者客户端订阅消费Topic的时候,会指定想要匹配的标签类型:
consumer.subscribe("TopicTest", "TagA | TagB | TagC");
这段代码在内部实现中利用FilterAPI构建了一个SubscriptionData对象:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public void subscribe(String topic, String subExpression) throws MQClientException {
SubscriptionData subscriptionData = FilterAPI
.buildSubscriptionData(this.defaultMQPushConsumer.getConsumerGroup(),
topic,
subExpression);
// ...
}
}
当用户未指定标签或者指定为星号标签的时候,则代表用户接收所有标签的消息。如果用户指定了一个或者多个标签,那么会将每一个标签取其hashCode()放入到codeSet中。SubscriptionData还有一个expressionType字段,在使用标签匹配的时候,其不会设置这个字段的值,因此其保留为null。在这些信息设置好以后,当客户端发送心跳包的时候,会将这些Topic的注册信息一并上传至Broker服务器端,方便在Broker端进行匹配。
public class SubscriptionData implements Comparable<SubscriptionData> {
public final static String SUB_ALL = "*";
private Set<String> tagsSet = new HashSet<String>();
private Set<Integer> codeSet = new HashSet<Integer>();
private String expressionType;
}
当 Broker 端服务器在取消息的时候,每取出来一条消息,都会执行两道过滤机制:
- ConsumeQueue文件匹配
- CommitLog文件匹配
任一检查没有通过后,绝不会放行这条消息给客户端:
public class DefaultMessageStore implements MessageStore {
public GetMessageResult getMessage(final String group, /** 其他参数 **/) {
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
// ConsumeQueue 文件匹配
if (messageFilter != null
&& !messageFilter.isMatchedByConsumeQueue(isTagsCodeLegal ? tagsCode : null, extRet ? cqExtUnit : null)) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
continue;
}
// CommitLog 文件匹配
if (messageFilter != null
&& !messageFilter.isMatchedByCommitLog(selectResult.getByteBuffer().slice(), null)) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
// release...
selectResult.release();
continue;
}
}
}
}
消息过滤器的默认实现是ExpressionMessageFilter,消息过滤的默认实现策略就是看这个Topic的标签码集合中是否包含当前这条消息的标签码:
public class ExpressionMessageFilter implements MessageFilter {
@Override
public boolean isMatchedByConsumeQueue(Long tagsCode, ConsumeQueueExt.CqExtUnit cqExtUnit) {
// ...
if (ExpressionType.isTagType(subscriptionData.getExpressionType())) {
if (tagsCode == null) {
return true;
}
if (subscriptionData.getSubString().equals(SubscriptionData.SUB_ALL)) {
return true;
}
return subscriptionData.getCodeSet().contains(tagsCode.intValue());
}
// ...
return true;
}
@Override
public boolean isMatchedByCommitLog(ByteBuffer msgBuffer, Map<String, String> properties) {
if (ExpressionType.isTagType(subscriptionData.getExpressionType())) {
return true;
}
// ...
}
}
下图是一幅标签匹配的简要流程图:
SQL匹配
在发送消息的时候,可以为每一条消息附带一个或者多个属性值,SQL匹配指的就是依据这些属性值和TAG标签是否满足一定的SQL语句条件,来过滤消息。用户如果想要开启SQL匹配,那么需要在Broker启动的时候,启用如下几个配置信息:
brokerConfig.setEnablePropertyFilter(true);
brokerConfig.setEnableCalcFilterBitMap(true);
messageStoreConfig.setEnableConsumeQueueExt(true);
注册过滤信息
我们在消费者如何接收消息一文中提到过,消费者启动之后,会通过心跳包定时给Broker服务器汇报自己的信息。而Broker服务器在收到消费者的心跳包之后,会产生一个注册事件,如下所示:
public class ConsumerManager {
public boolean registerConsumer(final String group,
/** 其他参数 **/) {
// ...
this.consumerIdsChangeListener.handle(ConsumerGroupEvent.REGISTER, group, subList);
// ...
}
}
DefaultConsumerIdsChangeListener是默认的消费者列表注册事件通知器的实现类,其在收到注册事件以后,会将用户在消费者端订阅的Topic信息注册到ConsumerFilterManager中:
public class DefaultConsumerIdsChangeListener implements ConsumerIdsChangeListener {
@Override
public void handle(ConsumerGroupEvent event, String group, Object... args) {
switch (event) {
case REGISTER:
Collection<SubscriptionData> subscriptionDataList = (Collection<SubscriptionData>) args[0];
this.brokerController.getConsumerFilterManager().register(group, subscriptionDataList);
break;
// ...
}
}
}
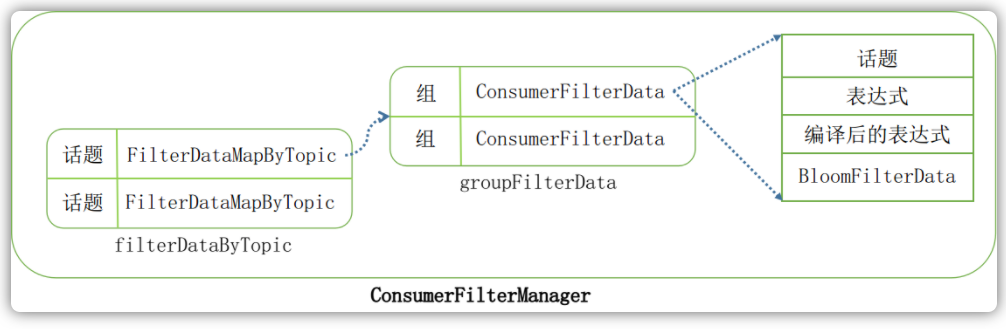
ConsumerFilterData中包含了消费者客户端注册的SQL表达式,由上图可以看到对于每一个Topic所对应的FilterDataMapByTopic,可以注册多个SQL表达式。但是这里需要注意的是,这多个SQL表达式是按照组来做区分的,也就是说一个组只能有一个SQL表达式,那么后注册的会覆盖掉之前注册的。因此,如果想要对同一个组使用不同的SQL语句来过滤自己想要的信息,这些不同的SQL语句必须划分到不同的组里面才可行。
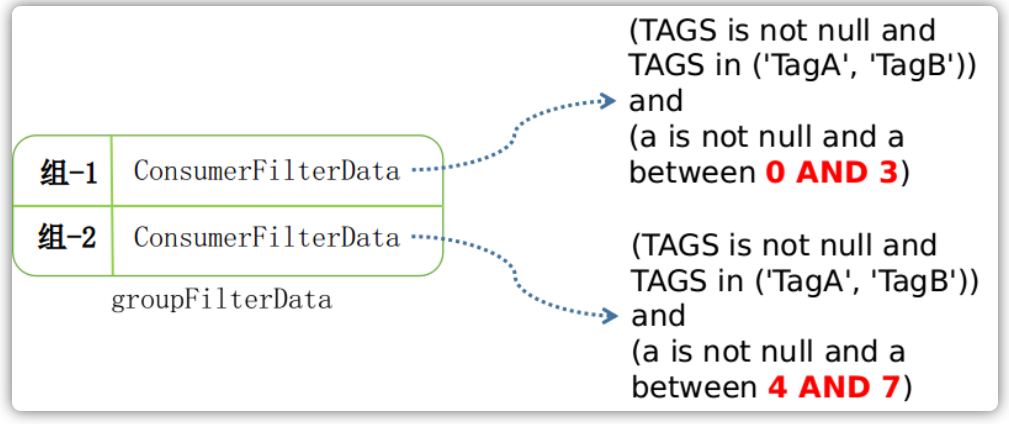
生成BloomFilterData
在RocketMQ中实现的布隆过滤器,其有四个最关键的值:
public class BloomFilter {
// 最大错误率
private int f;
// 可能插入 n 个元素
private int n;
// k 个哈希函数
private int k;
// 数组总共 m 位
private int m;
}
RocketMQ实现的布隆过滤器是根据错误率f和可能插入的元素数量n计算出来的k和m,在默认配置情况下,即如下n=32和f=20,计算出来需要k=3个哈希函数和m=112位的数组。
public class BrokerConfig {
// Expect num of consumers will use filter.
private int expectConsumerNumUseFilter = 32;
// Error rate of bloom filter, 1~100.
private int maxErrorRateOfBloomFilter = 20;
}
当客户端注册过滤新的时候,其会根据"Group#Topic"这个字符串计算出相应的位映射数据,也即这个字符串经过布隆过滤器中的若干个哈希函数得到的几个不同的哈希值:
public class ConsumerFilterManager extends ConfigManager {
public boolean register(final String topic, /** 其它参数 **/) {
// ...
BloomFilterData bloomFilterData =
bloomFilter.generate(consumerGroup + "#" + topic);
// ...
}
}
ConsumerFilterManager中的Topic过滤信息数据,每隔10秒进行一次磁盘持久化:
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
BrokerController.this.consumerFilterManager.persist();
}
}, 1000 * 10, 1000 * 10, TimeUnit.MILLISECONDS);
}
}
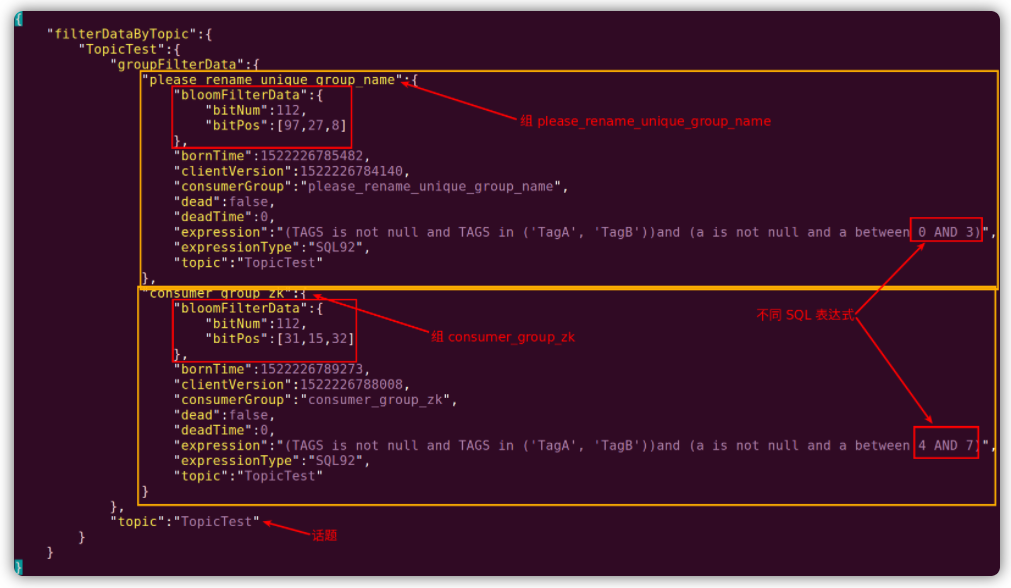
磁盘文件 consumerFilter.json 中保存的数据信息如下示例:
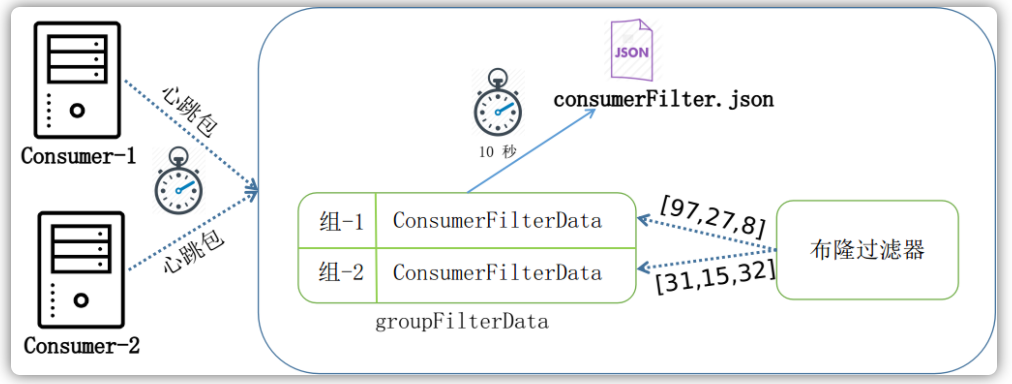
上述流程图如下所示:
编译SQL语句
JavaCC(Java Complier Complier)是一个能生成语法和词法分析的生成程序,它通过阅读一个自定义的语法标准文件(通常以jj为后缀名),然后就能生成能够解析该语法的扫描器和解析器的代码。
通过执行 javacc SelectorParser.jj 命令以后,其会生成如下七个 Java 文件,用以解析 SQL 语法:
过滤器工厂FilterFactory在初次使用的时候,会注册一个SqlFilter类,这个类能够将消费者端指定的SQL语句编译解析为Expression表达式对象,方便后续消息的快速匹配于过滤。
public class SqlFilter implements FilterSpi {
@Override
public Expression compile(final String expr) throws MQFilterException {
return SelectorParser.parse(expr);
}
}
计算位映射
当Broker服务器接收到新的消息到来之后,一直在后台运行的ReputMessageService会负责将这条消息封装位一个DispatchRequest分发请求,这个请求会传递给提前构建好的分发请求链。在DefaultMessageStore的构造函数中,我们看到依次添加了构建消费队列和构建索引的分发请求服务:
public class DefaultMessageStore implements MessageStore {
public DefaultMessageStore(final MessageStoreConfig messageStoreConfig, /** 其它参数 **/) throws IOException {
this.dispatcherList = new LinkedList<>();
this.dispatcherList.addLast(new CommitLogDispatcherBuildConsumeQueue());
this.dispatcherList.addLast(new CommitLogDispatcherBuildIndex());
}
}
而在Broker初始化的时候,我们看到其又添加了计算位映射的分发请求服务,并且将此分发服务放在链表的第一个位置:
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
this.messageStore.getDispatcherList()
.addFirst(new CommitLogDispatcherCalcBitMap(this.brokerConfig, this.consumerFilterManager));
}
}
因此,在每次接收到新的消息之后,分发请求的需要经过如下三个分发请求服务进行处理:

我们在这部分只介绍计算位映射的服务类实现。如下,dispatch方法用来分发请求里面的消息,对于这每一条消息,首先根据Topic取得所有的消费过滤数据。这每一条数据代表的就是一条SQL过滤语句信息。我们在这个地方,需要一一遍历这些过滤信息,从而完成计算位服务的需求:
public class CommitLogDispatcherCalcBitMap implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
Collection<ConsumerFilterData> filterDatas = consumerFilterManager.get(request.getTopic());
Iterator<ConsumerFilterData> iterator = filterDatas.iterator();
while (iterator.hasNext()) {
ConsumerFilterData filterData = iterator.next();
// ...
}
}
}
在拿到ConsumerFilterData信息之后,其会根据这条信息内的SQL语句编译后的表达式来对这条消息进行检查匹配(evaluate),看到这条消息是否满足SQL语句所设置的条件,如果满足,那么会将先前在客户端注册阶段计算好的BloomFilterData中的映射位信息设置到filterBitMap中,即将相应的位数组BitsArray中的相应位设置为1。在验证完所有的SQL语句之后,会将这些所有的字节数组放置到request请求之后,以便交由下一个请求分发服务进行使用:
public class CommitLogDispatcherCalcBitMap implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
Collection<ConsumerFilterData> filterDatas = consumerFilterManager.get(request.getTopic());
Iterator<ConsumerFilterData> iterator = filterDatas.iterator();
while (iterator.hasNext()) {
ConsumerFilterData filterData = iterator.next();
// ...
}
}
}
存储位映射
MessageStore在开启扩展消息队列的配置之后,每一个消费队列在创建的时候,都会额外创建一个扩展消费队列。每一个扩展队列文件的大小默认为48MB:
public class ConsumeQueue {
public ConsumeQueue(final String topic, /** 其它参数 **/) {
// ...
if (defaultMessageStore.getMessageStoreConfig().isEnableConsumeQueueExt()) {
this.consumeQueueExt = new ConsumeQueueExt(topic, /** 其它参数 **/);
}
}
}
在计算位映射一节中,计算好位字节数组之后,我们这里需要通过第二个分发请求服务CommitLogDispatcherBuildConsumeQueue来存储这些字节信息。通过如下代码,我们知道它将请求中的位映射信息、消息存储事件、标签码这三条信息封装为ConsumeQueueExt.CqExtUnit,然后放入扩展消费队列文件中。
public class ConsumeQueue {
public void putMessagePositionInfoWrapper(DispatchRequest request) {
long tagsCode = request.getTagsCode();
if (isExtWriteEnable()) {
ConsumeQueueExt.CqExtUnit cqExtUnit = new ConsumeQueueExt.CqExtUnit();
cqExtUnit.setFilterBitMap(request.getBitMap());
cqExtUnit.setMsgStoreTime(request.getStoreTimestamp());
cqExtUnit.setTagsCode(request.getTagsCode());
long extAddr = this.consumeQueueExt.put(cqExtUnit);
if (isExtAddr(extAddr)) {
tagsCode = extAddr;
}
}
}
}
上述代码中,put方法返回的是一个long类型的扩展地址,当这个数值满足isExtAddr要求后,其会将当前的标签码设置为刚才返回的扩展地址,这是为什么呢?
我们首先来看ConsumeQueueExt文件在存放数据成功后是如何返回信息的:
public class ConsumeQueueExt {
public static final long MAX_ADDR = Integer.MIN_VALUE - 1L;
public long put(final CqExtUnit cqExtUnit) {
if (mappedFile.appendMessage(cqExtUnit.write(this.tempContainer), 0, size)) {
return decorate(wrotePosition + mappedFile.getFileFromOffset());
}
return 1;
}
public long decorate(final long offset) {
if (!isExtAddr(offset)) {
return offset + Long.MIN_VALUE;
}
return offset;
}
public static boolean isExtAddr(final long address) {
return address <= MAX_ADDR;
}
}
MAX_ADDR是一个很小很小的值,为-2147483649,即写入位置如果不小于这个值,那么我们就人顶它不是扩展地址,需要将修正后的写入偏移量+Long.MIN_VALUE确定为扩展地址。当读取信息的时候,其先读取ConsumeQueue文件中的最后的Hash标签码值,如果其通过isExtAddr()函数返回的是true,那么我们就可以使用这个地址,再通过一个unDecorate()函数将其修正为正确的ConsumerQueueExt文件的写入地址,从而接着读取想要的信息:
public long unDecorate(final long address) {
if (isExtAddr(address)) {
return address - Long.MIN_VALUE;
}
return address;
}
这个地方,我们发现ConsumeQueue中的最后一个long型数值,可能存储的是标签Hash码,也可能存储的是扩展消费队列的写入地址,所以需要通过isExtAddr()来分情况判断。
下图为ConsumeQueue文件和ConsumeQueueExt文件中存取信息的不同:
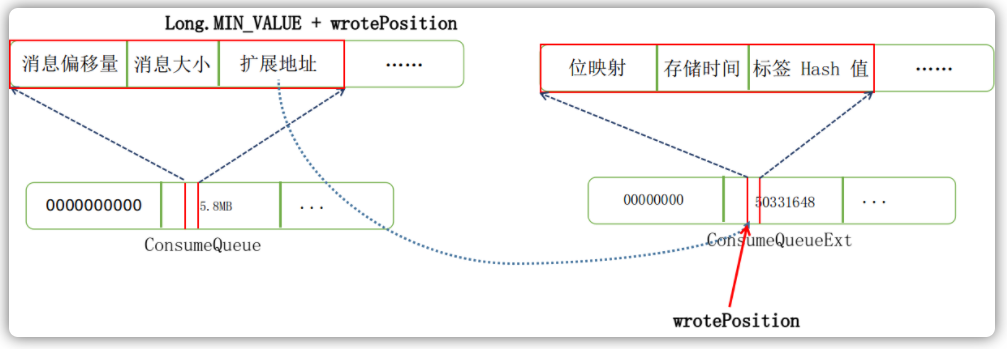
消息过滤
在上小节我们提到了有关扩展消息队列地址和标签Hash码存储的不同,所以在获取消息的时候,先得从消费队列文件中取出tagsCode,然后检查是否是扩展消费队列地址,如果是,那么就需要从扩展消费队列文件中读取正确的标签Hash码,如下所示:
public class DefaultMessageStore implements MessageStore {
public GetMessageResult getMessage(final String group, /** 其它参数 **/) {
ConsumeQueueExt.CqExtUnit cqExtUnit = new ConsumeQueueExt.CqExtUnit();
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {
long tagsCode = bufferConsumeQueue.getByteBuffer().getLong();
boolean extRet = false, isTagsCodeLegal = true;
if (consumeQueue.isExtAddr(tagsCode)) {
extRet = consumeQueue.getExt(tagsCode, cqExtUnit);
if (extRet) {
tagsCode = cqExtUnit.getTagsCode();
} else {
isTagsCodeLegal = false;
}
}
}
}
}
当获取到这条消息在扩展消费队列文件中存取的信息后,就会和标签匹配一节所讲述的一致,会进行两道过滤机制,我们先来看第一道ConsumeQueue文件匹配:
public class ExpressionMessageFilter implements MessageFilter {
@Override
public boolean isMatchedByConsumeQueue(Long tagsCode, ConsumeQueueExt.CqExtUnit cqExtUnit) {
byte[] filterBitMap = cqExtUnit.getFilterBitMap();
BloomFilter bloomFilter = this.consumerFilterManager.getBloomFilter();
BitsArray bitsArray = BitsArray.create(filterBitMap);
return bloomFilter.isHit(consumerFilterData.getBloomFilterData(), bitsArray);
}
}
ExpressionMessageFilter依据CqExtUnit中存储的位数组重新创建了比特数组bitsArray,这个数组信息中已经存储了不同SQL表达式是否匹配这条消息的结果。isHit()函数会一一检查BloomFilterData中存储的位信息是否映射在BitsArray中。只要有任何一位没有映射,那么就可以立刻判断出这条消息肯定不符合SQL语句的条件。
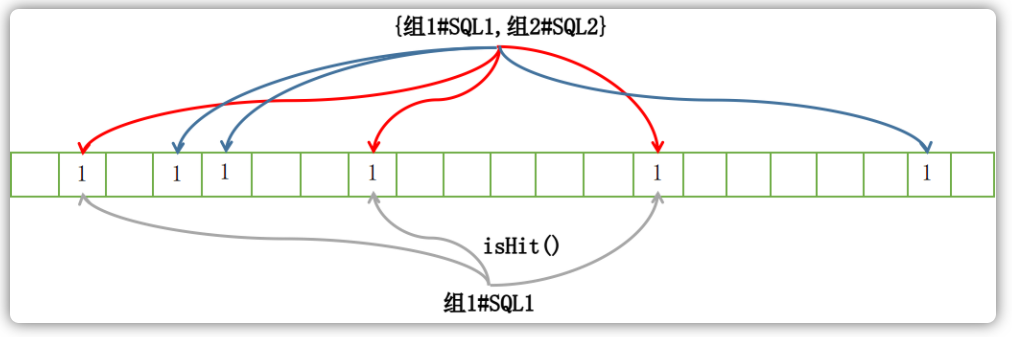
因为布隆过滤器有一定的错误率,其只能精确的判断消息是否一定不在集合中,返回成功的只能确定为消息可能在集合中。因此通过布隆过滤器检查后还需要经过第二道过滤机制,即SQL编译后的表达式亲自验证是否匹配:
public class ExpressionMessageFilter implements MessageFilter {
@Override
public boolean isMatchedByCommitLog(ByteBuffer msgBuffer, Map<String, String> properties) {
MessageEvaluationContext context = new MessageEvaluationContext(tempProperties);
Object ret = realFilterData.getCompiledExpression().evaluate(context);
if (ret == null || !(ret instanceof Boolean)) {
return false;
}
return (Boolean) ret;
}
}
通过在验证SQL表达式是否满足之前,提前验证是否命中布隆过滤器,可以有效的避免许多不必要的验证:
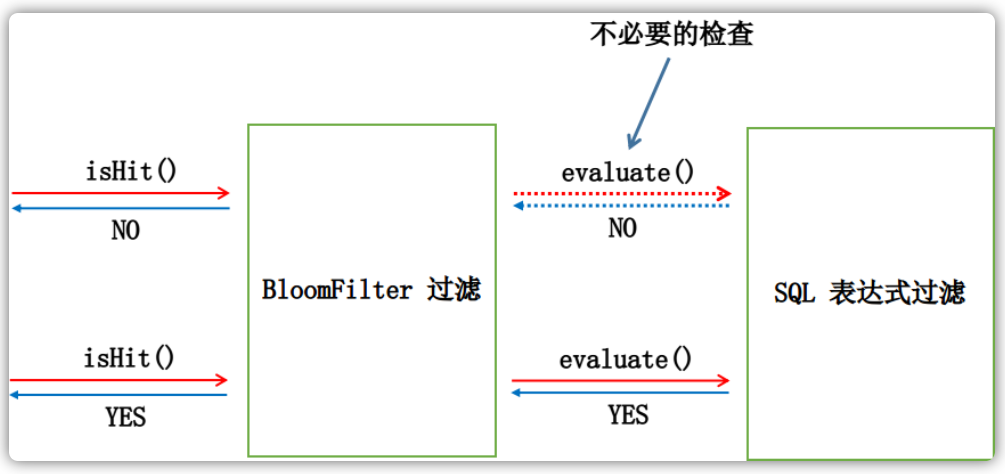
自定义匹配
消息的自定义匹配需要开启过滤服务器、上传过来类、过滤服务器委托过滤消息等步骤,下面我们一一进行说明。
过滤服务器
在启动Broker服务器的时候,如果指定了下面一行设置:
brokerConfig.setFilterServerNums(int filterServerNums);
即将过滤的服务器的数量设定为大于0,那么Broker服务器在启动的时候,将会启动filterServerNums个过滤服务器。过滤服务器是通过调用shell命令的方式,启用独立进程进行启动的。
public class FilterServerManager {
public void createFilterServer() {
int more =
this.brokerController.getBrokerConfig().getFilterServerNums() -
this.filterServerTable.size();
String cmd = this.buildStartCommand();
for (int i = 0; i < more; i++) {
FilterServerUtil.callShell(cmd, log);
}
}
}
过滤服务器在初始化的时候,会启动定时器每个10秒注册一次到Broker服务器:
public class FiltersrvController {
public boolean initialize() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
FiltersrvController.this.registerFilterServerToBroker();
}
}, 3, 10, TimeUnit.SECONDS);
}
}
Broker服务器在收到来自过滤服务器的注册之后,会把过滤服务器的地址信息、注册事件等放到过滤服务器表中:
public class FilterServerManager {
private final ConcurrentMap<Channel, FilterServerInfo> filterServerTable =
new ConcurrentHashMap<Channel, FilterServerInfo>(16);
}
同样,Broker服务器也需要定时地将过滤服务器地址信息同步给所有Namesrv命名服务器,上述整个流程如下图所示:
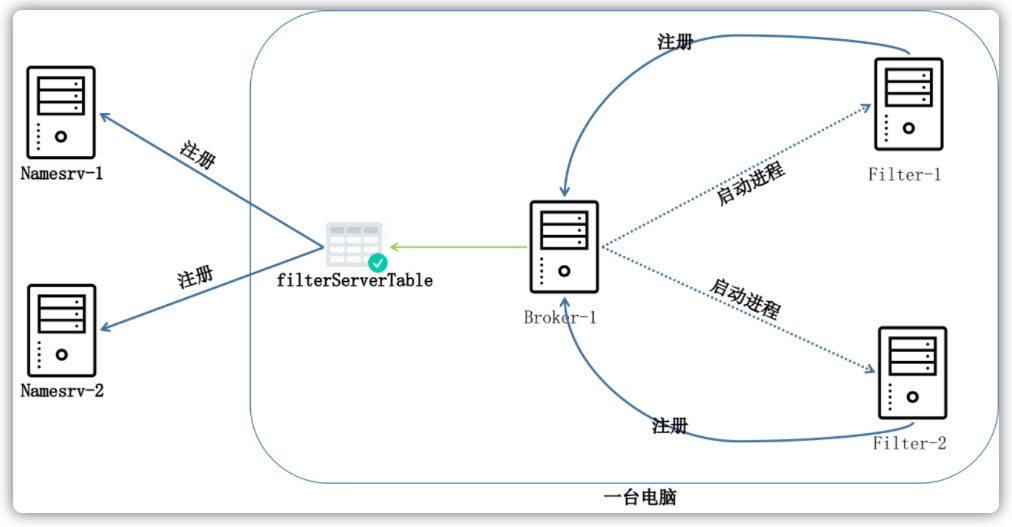
过滤类
当消费者通过使用自定义匹配过滤消息的时候,会将存储订阅信息的SubscriptionData中的filterClassSource设置为true,用以表示这个客户端需要过滤类来进行消息的匹配和过滤。
消费者客户端在启动的过程中,会定时地上传本地的过滤类源码到过滤服务器:
public class MQClientInstance {
private void startScheduledTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
MQClientInstance.this.sendHeartbeatToAllBrokerWithLock();
}
}, 1000, this.clientConfig.getHeartbeatBrokerInterval(), TimeUnit.MILLISECONDS);
}
public void sendHeartbeatToAllBrokerWithLock() {
// ...
this.uploadFilterClassSource();
}
}
其中过滤服务器的地址列表是在从Namesrv服务器获取Topic路由信息的时候取得的,Topic路由信息不光存储了消息队列数据,还存储了各个Broker所关联的服务器列表:
public class TopicRouteData extends RemotingSerializable {
// ...
private HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
}
当过滤服务器接收到来自消费者客户端的源码之后,其会首先生成一个键为Topic@Group的字符串来查阅过滤信息是否已经存在于内存里面的filterClassTable表中且文件通过CRC校验。如果没有存在或校验失败,那么就需要先编译并加载这个类:
public class DynaCode {
public void compileAndLoadClass() throws Exception {
String[] sourceFiles = this.uploadSrcFile();
this.compile(sourceFiles);
this.loadClass(this.loadClass.keySet());
}
}
默认情况下,编译后的类存放于目录下,类的源文件和类的字节码文件名也会相应的加上当前时间戳来确定:

上述流程图如下:
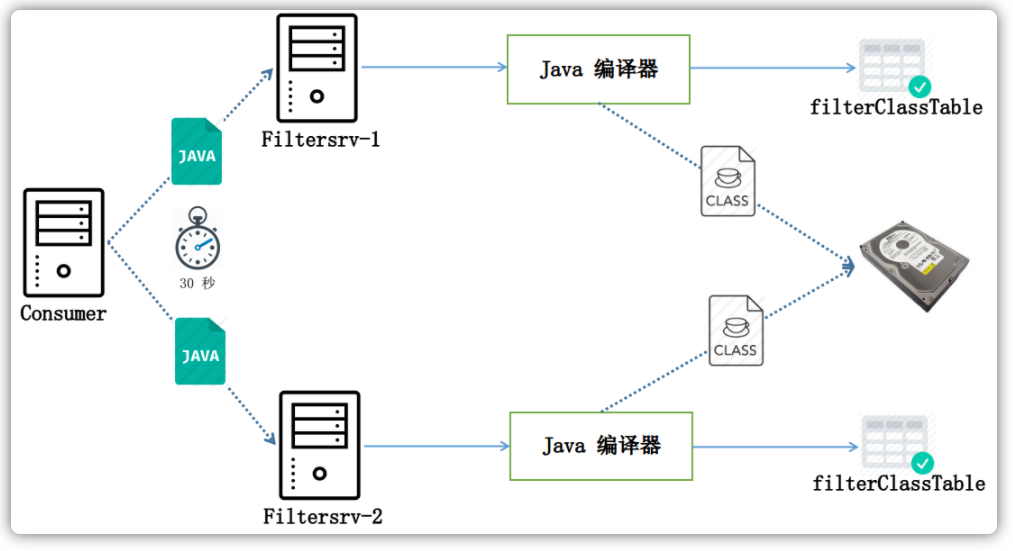
过滤消息
当消费者客户端自定义匹配过滤消息后,发往服务器的数据中也包含了过滤标志位,这样每次拉取消息的服务器也由原来的Broker服务器变更为Filtersrv过滤服务器,其中过滤服务器地址的选择是随机确定的:
public class PullAPIWrapper {
public PullResult pullKernelImpl(final MessageQueue mq, /** 其它参数 **/) throws Exception {
// ...
if (findBrokerResult != null) {
if (PullSysFlag.hasClassFilterFlag(sysFlagInner)) {
// 从过滤服务器拉取消息
brokerAddr = computPullFromWhichFilterServer(mq.getTopic(), brokerAddr);
}
// ...
}
}
}
过滤服务器在启动的时候,内部还启动了一个PullConsumer客户端,用以从Broker服务器拉取消息:
public class FiltersrvController {
private final DefaultMQPullConsumer defaultMQPullConsumer =
new DefaultMQPullConsumer(MixAll.FILTERSRV_CONSUMER_GROUP);
public void start() throws Exception {
this.defaultMQPullConsumer.start();
// ...
}
}
当过滤服务器收到真正的消费者发来的消息的请求之后,其会委托内部的PullConsumer使用包含在请求体内的偏移量去Broker服务器拉取所有消息,此时这些消息是完全没有过滤的:
public class DefaultRequestProcessor implements NettyRequestProcessor {
private RemotingCommand pullMessageForward(final ChannelHandlerContext ctx,
final RemotingCommand request) throws Exception {
MessageQueue mq = new MessageQueue();
mq.setTopic(requestHeader.getTopic());
mq.setQueueId(requestHeader.getQueueId());
mq.setBrokerName(this.filtersrvController.getBrokerName());
// 设置偏移量和最大数量
long offset = requestHeader.getQueueOffset();
int maxNums = requestHeader.getMaxMsgNums();
// 委托内部消费者从 Broker 服务器拉取消息
pullConsumer.pullBlockIfNotFound(mq, null, offset, maxNums, pullCallback);
}
}
过滤服务器从Broker服务器获取到完整的消息列表之后,会遍历消息列表,然后使用过滤类一一进行匹配,最终将匹配的消息列表返回给客户端:
public class DefaultRequestProcessor implements NettyRequestProcessor {
private RemotingCommand pullMessageForward(final ChannelHandlerContext ctx,
final RemotingCommand request) throws Exception {
final PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
switch (pullResult.getPullStatus()) {
case FOUND:
List<MessageExt> msgListOK = new ArrayList<MessageExt>();
for (MessageExt msg : pullResult.getMsgFoundList()) {
// 使用过滤类过滤消息
boolean match = findFilterClass.getMessageFilter().match(msg, filterContext);
if (match) {
msgListOK.add(msg);
}
}
break;
// ...
}
}
};
// ...
}
}
上述流程如下图所示:
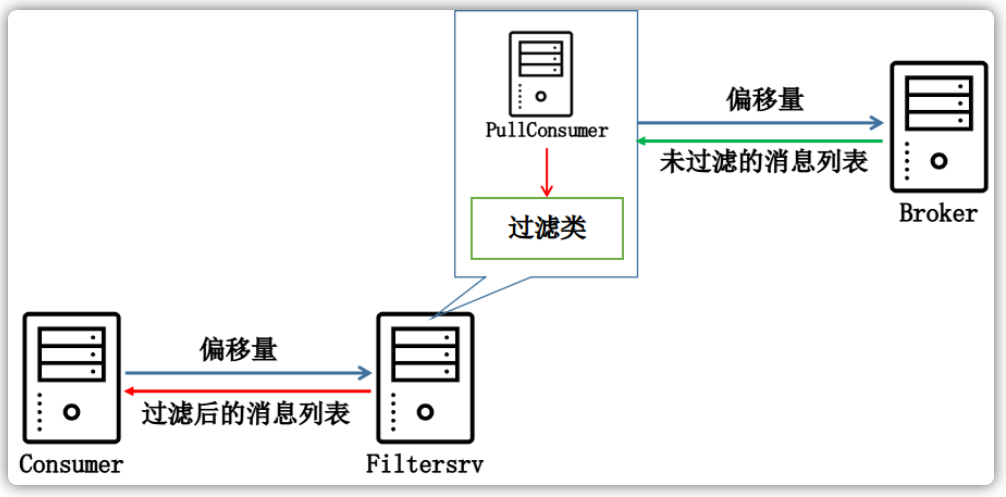
消息索引流程
消息查询
对于Producer发送到Broker服务器的消息,RocketMQ支持多种方式来方便地查询消息:
- 根据键查询消息
- 根据ID(偏移量)查询消息
- 根据唯一键查询消息
- 根据消息队列偏移量查询消息
在构建消息的时候,指定了这条消息的键位“OrderID001”:
Message msg =
new Message("TopicTest",
"TagA",
"OrderID001", // Keys
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET))
那么,当这条消息发送成功后,我们可以使用queryMsgByKey命令查询这条消息的详细信息:
MQAdminStartup.main(new String[] {
"queryMsgByKey",
"-n",
"localhost:9876",
"-t",
"TopicTest",
"-k",
"OrderID001"
});
根据ID(偏移量)查询消息是指消息在发送成功后,其返回的SendResult类中包含了这条消息的唯一偏移量ID(注意此处指的是offsetMsgId):

用户可以使用queryMsgById命令查询这条消息的详细信息:
MQAdminStartup.main(new String[] {
"queryMsgById",
"-n",
"localhost:9876",
"-i",
"0A6C73D900002A9F0000000000004010"
});
根据唯一键查询消息指的是消息在发送成功之后,其返回的SendResult类包含了这条消息的唯一ID:

用户可以使用queryMsgByUniqueKey命令查询这条消息的详细信息:
MQAdminStartup.main(new String[] {
"queryMsgByUniqueKey",
"-n",
"localhost:9876",
"-i",
"0A6C73D939B318B4AAC20CBA5D920000",
"-t",
"TopicTest"
});
根据消息队列偏移量查询消息指的是消息发送成功之后的SendResult中还包含了消息队列的其它信息,如消息队列ID、消息队列偏移量等信息:
SendResult [sendStatus=SEND_OK,
msgId=0A6C73D93EC518B4AAC20CC4ACD90000,
offsetMsgId=0A6C73D900002A9F000000000000484E,
messageQueue=MessageQueue [topic=TopicTest,
brokerName=zk-pc,
queueId=3],
queueOffset=24]
根据这些信息,使用queryMsgByOffset命令也可以查询到这条消息的详细信息:
MQAdminStartup.main(new String[] {
"queryMsgByOffset",
"-n",
"localhost:9876",
"-t",
"TopicTest",
"-b",
"zk-pc",
"-i",
"3",
"-o",
"24"
});
ID (偏移量) 查询
ID(偏移量)是在消息发送到Broker服务器存储的时候生成的,其包含如下几个字段:
- Broker服务器的IP地址
- Broker服务器端口号
- 消息文件CommitLog写偏移量

public class CommitLog {
class DefaultAppendMessageCallback implements AppendMessageCallback {
public AppendMessageResult doAppend(final long fileFromOffset, /** 其它参数 **/) {
String msgId = MessageDecoder
.createMessageId(this.msgIdMemory,
msgInner.getStoreHostBytes(hostHolder),
wroteOffset);
// ...
}
}
}
Admin端查询的时候,首先对msgId进行解析,取出Broker服务器的IP、端口号和消息偏移量:
public class MessageDecoder {
public static MessageId decodeMessageId(final String msgId)
throws UnknownHostException {
byte[] ip = UtilAll.string2bytes(msgId.substring(0, 8));
byte[] port = UtilAll.string2bytes(msgId.substring(8, 16));
// offset
byte[] data = UtilAll.string2bytes(msgId.substring(16, 32));
// ...
}
}
获取到偏移量之后,Admin会对Broker服务器发送一个VIEW_MESSAGE_BY_ID的请求命令,Broker服务器在收到请求之后,会根据偏移量定位到CommitLog文件的相应位置然后取出位置,返回给Admin端:
public class DefaultMessageStore implements MessageStore {
@Override
public SelectMappedBufferResult selectOneMessageByOffset(long commitLogOffset) {
SelectMappedBufferResult sbr = this.commitLog
.getMessage(commitLogOffset, 4);
// 1 TOTALSIZE
int size = sbr.getByteBuffer().getInt();
return this.commitLog.getMessage(commitLogOffset, size);
}
}
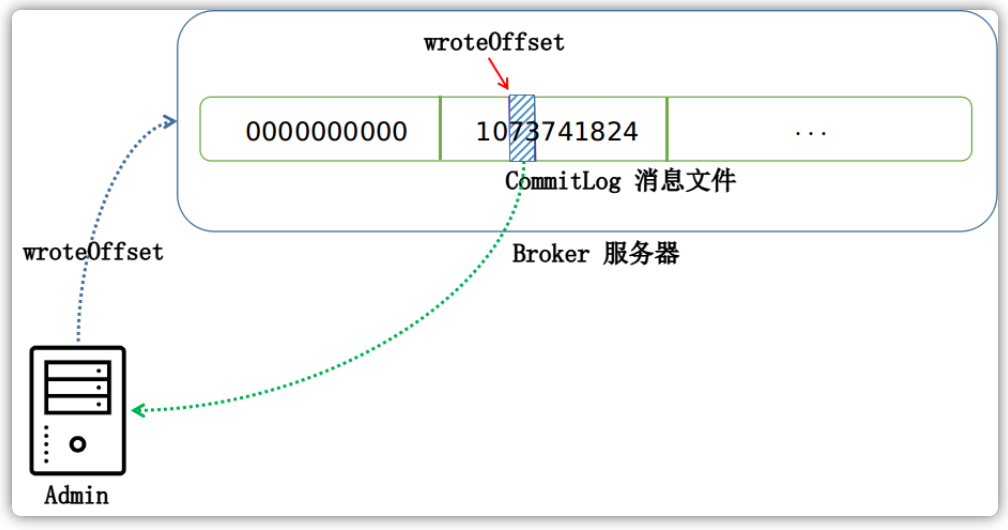
根据队列偏移量查询是最简单的一种查询方式,Admin会启动一个PullConsumer,然后利用用户传递给Admin的队列ID、队列偏移量等信息,从服务器拉取一条消息过来:
public class QueryMsgByOffsetSubCommand implements SubCommand {
@Override
public void execute(CommandLine commandLine, Options options, RPCHook rpcHook) throws SubCommandException {
// 根据参数构建 MessageQueue
MessageQueue mq = new MessageQueue();
mq.setTopic(topic);
mq.setBrokerName(brokerName);
mq.setQueueId(Integer.parseInt(queueId));
// 从 Broker 服务器拉取消息
PullResult pullResult = defaultMQPullConsumer.pull(mq, "*", Long.parseLong(offset), 1);
}
}
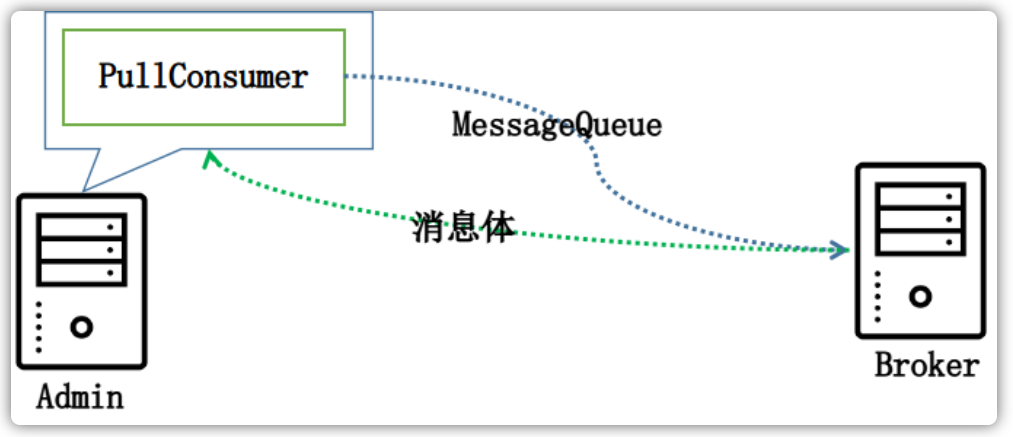
消息索引服务
在继续讲解剩下两种查询方式之前,我们必须先介绍一下Broker端的消息索引服务。在之前提到过,每当一条消息发送过来之后,其会封装为一个DispatchRequest来下发给各个转发服务,而CommitLogDispatcherBuildIndex构建索引服务便是其中之一:
class CommitLogDispatcherBuildIndex implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
if (DefaultMessageStore.this.messageStoreConfig.isMessageIndexEnable()) {
DefaultMessageStore.this.indexService.buildIndex(request);
}
}
}
索引文件结构
消息的索引信息是存放到磁盘上的,文件以时间戳命名的,默认存在$HOME/store/index目录下。由下图来看,一个索引文件的结构被分成了三部分:
- 前40个字节存放固定的索引头信息,包含了存放在这个索引文件中的消息的最小/大存储时间、最小/大偏移量等状况
- 中间一段存储了500万个哈希槽位,每个槽内部存储的是索引文件的地址(索引槽)
- 最后一段存储了2000万个索引内容信息,是实际的索引信息存储的地方。每一个槽位存储了这条消息的键哈希值、存储偏移量、存储时间戳与下一个索引槽地址
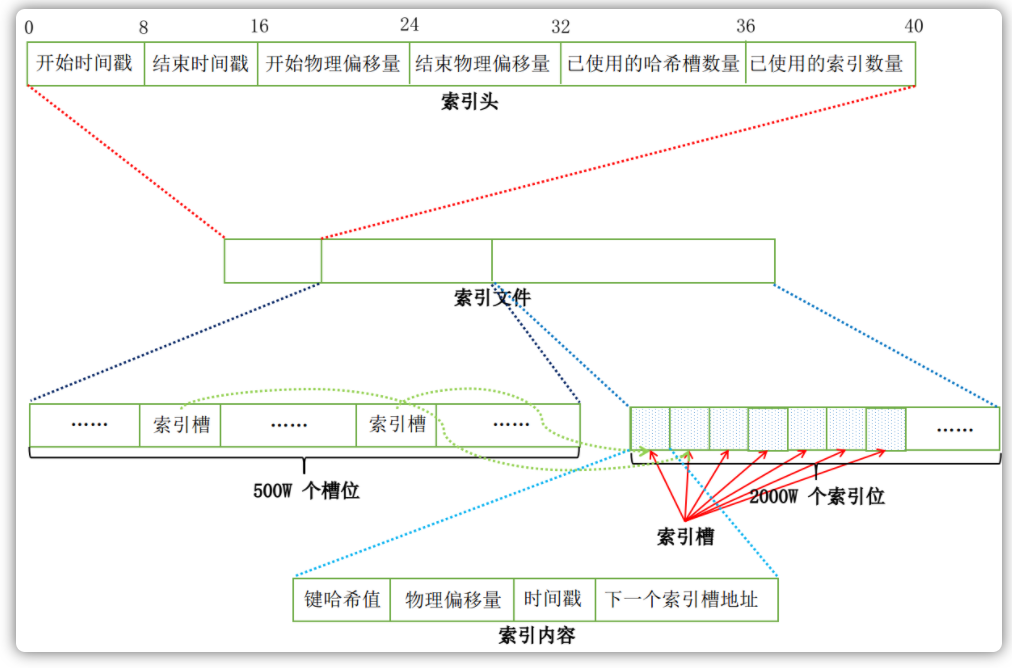
RocketMQ在内存中还维护一个索引文件列表,对于每一个索引文件,前一个文件的最大存储时间是下一个文件的最小存储时间,前一个文件的最大偏移量是下一个文件的最大偏移量。每一个索引文件都索引了某个时间段内、某个偏移量段内的所有消息,当文件满了,就会用前一个文件的最大偏移量和最大存储时间作为起始值,创建下一个索引文件:
添加消息
当有新的消息过来后,构建索引服务会取出这条消息的键,然后对字符串“Topic#键”构建索引,构建索引的步骤如下:
- 找出哈希值:生成字符串的哈希码,取余落到500W个槽位之一,并取出其中的值,默认为0
- 找出索引槽:IndexHeader维护了indexCount,实际存储的索引槽就是直接依次顺延添加的
- 存储索引内容:找到索引槽后,放入键哈希值、存储偏移量、存储时间戳与下一个索引槽地址,下一个索引槽地址就是第一步哈希槽中取出的值,0代表这个槽位是第一次被索引,而不为0代表这个操作之前的索引槽地址。因此,通过索引槽地址可以将相同哈希槽的消息串联起来,就像单链表那样
- 更新哈希槽:更新原有哈希槽中存储的值
我们以实际例子来说明。假设我们需要依次为键的哈希值为“{16,29,29,8,16,16}”这几条消息构建索引,我们在这个地方忽略了索引信息中存储的存储时间和便宜量字段,只是存储键哈希和下一索引槽信息,那么:
- 放入 16: 将 “16|0” 存储在第 1 个索引槽中,并更新哈希槽为 16 的值为 1,即哈希槽为 16 的第一个索引块的地址为 1
- 放入 29: 将 “29|0” 存储在第 2 个索引槽中,并更新哈希槽为 29 的值为 2,即哈希槽为 29 的第一个索引块的地址为 2
- 放入 29: 取出哈希槽为 29 中的值 2,然后将 “29|2” 存储在第 3 个索引槽中,并更新哈希槽为 29 的值为 3,即哈希槽为 29 的第一个索引块的地址为 3。而在找到索引块为 3 的索引信息后,又能取出上一个索引块的地址 2,构成链表为: “[29]->3->2”
- 放入 8: 将 “8|0” 存储在第 4 个索引槽中,并更新哈希槽为 8 的值为 4,即哈希槽为 8 的第一个索引块的地址为 4
- 放入 16: 取出哈希槽为 16 中的值 1,然后将 “16|1” 存储在第 5 个索引槽中,并更新哈希槽为 16 的值为 5。构成链表为: “[16]->5->1”
- 放入 16: 取出哈希槽为 16 中的值 5,然后将 “16|5” 存储在第 6 个索引槽中,并更新哈希槽为 16 的值为 6。构成链表为: “[16]->6->5->1”
整个过程如下图所示:
查询消息
当需要根据键来查询消息的时候,其会按照倒序回溯整个索引文件列表,对于每一个在时间上能够匹配用户传入的begin和end时间戳参数的索引文件,会一一进行消息查询:
public class IndexService {
public QueryOffsetResult queryOffset(String topic, String key, int maxNum, long begin, long end) {
// 倒序
for (int i = this.indexFileList.size(); i > 0; i--) {
// 位于时间段内
if (f.isTimeMatched(begin, end)) {
// 消息查询
}
}
}
}
而具体到每一个索引文件,其查询匹配消息的过程如下所示:
- 确定哈希槽:根据键生成哈希值,定位到哈希槽
- 定位索引槽:沿着索引槽地址,依次取出下一个索引槽地址,即沿着链表遍历,直至遇见下一个索引槽地址位非法地址0停止
- 收集偏移量:在遇到匹配的消息之后,会将相应的物理偏移量放到列表中,最后根据物理偏移量,从CommitLog文件中取出消息
public class DefaultMessageStore implements MessageStore {
@Override
public QueryMessageResult queryMessage(String topic, String key, int maxNum, long begin, long end) {
for (int m = 0; m < queryOffsetResult.getPhyOffsets().size(); m++) {
long offset = queryOffsetResult.getPhyOffsets().get(m);
// 根据偏移量从 CommitLog 文件中取出消息
}
}
}
以查询哈希值 16 的消息为例,图示如下:

唯一键查询
消息的唯一键是在客户端发送消息前构建的:
public class DefaultMQProducerImpl implements MQProducerInner {
private SendResult sendKernelImpl(final Message msg, /** 其它参数 **/) throws XXXException {
// ...
if (!(msg instanceof MessageBatch)) {
MessageClientIDSetter.setUniqID(msg);
}
}
}
创建唯一ID的算法:
public class MessageClientIDSetter {
public static String createUniqID() {
StringBuilder sb = new StringBuilder(LEN * 2);
sb.append(FIX_STRING);
sb.append(UtilAll.bytes2string(createUniqIDBuffer()));
return sb.toString();
}
}
唯一键是根据客户端的进程ID、IP地址、ClassLoader哈希码、时间戳、计数器这几个值来生成的一个唯一的键,然后作为这条消息的附属属性发送到Broker服务器的:
public class MessageClientIDSetter {
public static void setUniqID(final Message msg) {
if (msg.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX) == null) {
msg.putProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX, createUniqID());
}
}
}
当服务器收到客户端发送过来的消息之后,索引服务便会取出客户端生成的uniqKey并为之建立索引,放入到索引文件中:
public class IndexService {
public void buildIndex(DispatchRequest req) {
// ...
if (req.getUniqKey() != null) {
indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()));
}
// ...
}
}
客户端在生成消息唯一键的时候,在ByteBuffer的第11位到第14位放置的是当前的时间与当月第一天的时间的毫秒差:
public class MessageClientIDSetter {
private static byte[] createUniqIDBuffer() {
long current = System.currentTimeMillis();
if (current >= nextStartTime) {
setStartTime(current);
}
// 时间差 [当前时间 - 这个月 1 号的时间]
// putInt 占据的是第 11 位到第 14 位
buffer.putInt((int) (System.currentTimeMillis() - startTime));
}
private synchronized static void setStartTime(long millis) {
Calendar cal = Calendar.getInstance();
cal.setTimeInMillis(millis);
cal.set(Calendar.DAY_OF_MONTH, 1);
cal.set(Calendar.HOUR_OF_DAY, 0);
cal.set(Calendar.MINUTE, 0);
cal.set(Calendar.SECOND, 0);
cal.set(Calendar.MILLISECOND, 0);
// 开始时间设置为这个月的 1 号
startTime = cal.getTimeInMillis();
// ...
}
}
我们知道消息索引服务的查询需要用户传入begin和end者两个时间值,以进行这段时间内的匹配。所以RocketMQ为了加速消息的查询,于是在Admin端对特定ID进行查询的时候,首先取出了这段时间差值,然后与当月时间进行相加得到的begin时间值:
public class MessageClientIDSetter {
public static Date getNearlyTimeFromID(String msgID) {
ByteBuffer buf = ByteBuffer.allocate(8);
byte[] bytes = UtilAll.string2bytes(msgID);
buf.put((byte) 0);
buf.put((byte) 0);
buf.put((byte) 0);
buf.put((byte) 0);
// 取出第 11 位到 14 位
buf.put(bytes, 10, 4);
buf.position(0);
// 得到时间差值
long spanMS = buf.getLong();
Calendar cal = Calendar.getInstance();
long now = cal.getTimeInMillis();
cal.set(Calendar.DAY_OF_MONTH, 1);
cal.set(Calendar.HOUR_OF_DAY, 0);
cal.set(Calendar.MINUTE, 0);
cal.set(Calendar.SECOND, 0);
cal.set(Calendar.MILLISECOND, 0);
long monStartTime = cal.getTimeInMillis();
if (monStartTime + spanMS >= now) {
cal.add(Calendar.MONTH, -1);
monStartTime = cal.getTimeInMillis();
}
// 设置为这个月(或者上个月) + 时间差值
cal.setTimeInMillis(monStartTime + spanMS);
return cal.getTime();
}
}
由于发送消息的客户端和查询消息的Admin端可能不在一台服务器上,而且从函数的命名getNearlyTimeFromID与上述实现来看,Admin端的时间戳得到的是一个近似起始值,它尽可能地加速用户的查询。而且太旧的消息(超过一个月的消息)是查询不到的。
当begin时间戳确定以后,Admin便会将其它必要的信息,如Topic、key等信息封装答QUERY_MESSAGE的包中,然后向Broker服务器传递这个请求,来进行消息的查询。Broker服务器在获取到这个查询消息的请求后,便会根据key从索引文件中查询符合的消息,最终返回的Admin端。
键查询消息
上文提到过,在发送消息的时候,可以填充一个keys的值,这个值将会作为消息的一个属性被发送到Broker服务器上:
public class Message implements Serializable {
public void setKeys(String keys) {
this.putProperty(MessageConst.PROPERTY_KEYS, keys);
}
}
当服务器收到客户端发送过来的消息之后,索引服务便会取出这条消息的keys并将其用空格进行分割,分割后的每一个字符串都会作为一个单独的键,创建索引,放入到索引文件中:
public class IndexService {
public void buildIndex(DispatchRequest req) {
// ...
if (keys != null && keys.length() > 0) {
// 使用空格进行分割
String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
for (int i = 0; i < keyset.length; i++) {
String key = keyset[i];
if (key.length() > 0) {
indexFile = putKey(indexFile, msg, buildKey(topic, key));
}
}
}
}
}
由此我们也可以得知,keys键的设置通过使用空格分割字符串,一条消息可以指定多个键。
keys键查询的方式也是通过将参数封装为QUERY_MESSAGE请求包中去请求服务器返回相应的信息。由于键本身不能和时间戳相关联,因此begin值设置的是0,这是和第五节的不同之处:
public class QueryMsgByKeySubCommand implements SubCommand {
private void queryByKey(final DefaultMQAdminExt admin, final String topic, final String key)
throws MQClientException, InterruptedException {
// begin: 0
// end: Long.MAX_VALUE
QueryResult queryResult = admin.queryMessage(topic, key, 64, 0, Long.MAX_VALUE);
}
}
定时消息和重试消息
定时消息
RocketMQ支持Producer端发送定时消息,即该消息被发送之后,到一段时间之后才能被Consumer消费者端消费,不过,当前开源版本的RocketMQ所支持的定时时间是有限的、不同级别的精度的时间,并不是任意无限制的定时时间。因此在每条消息上设置定时时间的API叫做setDelayTimeLevel,而非setDelayTime这样的命名:
Message msg =
new Message("TopicTest" /* Topic */,
"TagA" /* Tag */,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */);
msg.setDelayTimeLevel(i + 1);
默认Broekr服务器有18个定时级别:
public class MessageStoreConfig {
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
}
这18个定时级别在服务器端启动的时候,会被解析并放置列表delayLevelTable中。解析的过程就是上述字符串按照空格拆开后分开,然后根据时间单位的不同再进一步进行计算,得到最终的毫秒时间。级别就是根据这些毫秒时间的顺序而确定的,例如上述1s延迟就是级别1,5s延迟就是级别2,以此类推:
public class ScheduleMessageService extends ConfigManager {
public boolean parseDelayLevel() {
for (int i = 0; i < levelArray.length; i++) {
// ...
int level = i + 1;
long delayTimeMillis = tu * num;
// 级别:延迟时间
this.delayLevelTable.put(level, delayTimeMillis);
}
}
}
定时消息存储
客户端在为某条消息设置上定时级别的时候,实际上级别这个字段会被作为附属属性放到消息中:
public class Message implements Serializable {
public void setDelayTimeLevel(int level) {
this.putProperty(MessageConst.PROPERTY_DELAY_TIME_LEVEL, String.valueOf(level));
}
}
与普通的消息一样,定时消息也会被存储到CommitLog消息文件中,将定时消息存储下来是为了保证消息最大程度地不丢失。不过毕竟定时消息和普通消息还是有所不同,在遇到定时消息后,CommitLog会将这条消息地Topic和队列ID替换成专门用于定时的Topic和相应级别对应的队列ID,真实的Topic的队列ID会作为属性值放置到这条消息中。
public class CommitLog {
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// Delay Delivery
if (msg.getDelayTimeLevel() > 0) {
topic = ScheduleMessageService.SCHEDULE_TOPIC;
queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
// Backup real topic, queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
// 替换 Topic 和 QueueID
msg.setTopic(topic);
msg.setQueueId(queueId);
}
}
}
随后,这条消息会被存储在CommitLog消息文件中。我们知道后台重放消息服务RequestMessageService会一直监督CommitLog文件是否添加了新的消息。当有了新的消息后,重放消息服务会取出消息并封装为DispatchRequest请求,然后将其分发给不同的三个分发服务,建立消费队列文件服务就是这其中之一。而此处当取消息封装为DispatchRequest的时候,当遇到定时消息时,又多做了一些额外的事情。
当遇见定时消息时,CommitLOg计算tagsCode标签码与普通消息不同。对于定时消息,tagsCode值设置的是这条消息的投递时间,即建立消费队列文件的时候,文件中tagesCode存储的是这条消息未来在什么时候被投递:
public class CommitLog {
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer,
final boolean checkCRC,
final boolean readBody) {
// Timing message processing
{
String t = propertiesMap.get(MessageConst.PROPERTY_DELAY_TIME_LEVEL);
if (ScheduleMessageService.SCHEDULE_TOPIC.equals(topic) && t != null) {
int delayLevel = Integer.parseInt(t);
if (delayLevel > 0) {
tagsCode = this.defaultMessageStore.getScheduleMessageService()
.computeDeliverTimestamp(delayLevel,storeTimestamp);
}
}
}
}
}
如下是,发送了10条定时级别分别为1-10的消息以后,$HOME/store/consumequeue文件下消费队列文件的分布情况:

不同的定时级别对应于不同的队列ID,定时级别减1得到的就是队列ID的值,因此级别1-10对应的是0-9的队列ID:
public class ScheduleMessageService extends ConfigManager {
public static int delayLevel2QueueId(final int delayLevel) {
return delayLevel - 1;
}
}
消息重试
消息重试分为消息发送重试和消息接收重试,消息发送重试是指消息从Producer端发送到Broker服务器的失败以后的重试情况,消息接收重试是指Consumer在消费消息的时候出现异常或者失败的重试情况。
Producer端通过配置如下两个API可以分别配置在同步发送和异步发送消息失败的时候的重试次数:
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setRetryTimesWhenSendAsyncFailed(3);
producer.setRetryTimesWhenSendFailed(3);
Consumer端在消费的时候,如果接收消息的回调函数出现了如下几种情况:
- 抛出异常
- 返回NULL状态
- 返回RECONSUME_LATER状态
- 超过15分钟没有响应
那么Consumer便会将消费失败的消息重新调度直到成功消费:
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
// 抛出异常
// 返回 NULL 或者 RECONSUME_LATER 状态
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
});
Producer消息发送重试
发送失败的重试方式,主要表现在发送消息的时候,会最多尝试getRetryTimesWhenSendFailed()次发送,当成功发送以后,会直接返回发送结果给调用者。当发送失败以后,会继续进行下一次发送尝试,核心代码如下所示:
public class DefaultMQProducerImpl implements MQProducerInner {
private SendResult sendDefaultImpl(Message msg, /** 其他参数 **/) throws MQClientException,
RemotingException,
MQBrokerException,
InterruptedException {
int timesTotal = communicationMode ==
CommunicationMode.SYNC ?
1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() :
1;
int times = 0;
for (; times < timesTotal; times++) {
// 尝试发送消息,发送成功 return,发送失败 continue
}
}
}
Consumer消息接收重试
Consumer在启动的时候,会指定一个copySubscription(),当用户注册的消息模型为集群模式的时候,会根据用户指定的Group创建重试Group Topic并放入到注册信息中:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public synchronized void start() throws MQClientException {
switch (this.serviceState) {
case CREATE_JUST:
// ...
this.copySubscription();
// ...
this.serviceState = ServiceState.RUNNING;
break;
}
}
private void copySubscription() throws MQClientException {
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
break;
case CLUSTERING:
// 重试话题组
final String retryTopic = MixAll.getRetryTopic(this.defaultMQPushConsumer.getConsumerGroup());
SubscriptionData subscriptionData = FilterAPI.buildSubscriptionData(this.defaultMQPushConsumer.getConsumerGroup(),
retryTopic, SubscriptionData.SUB_ALL);
this.rebalanceImpl.getSubscriptionInner().put(retryTopic, subscriptionData);
break;
default:
break;
}
}
}
假设用户指定的组为“ORDER”,那么重试的Topic则为“%RETRY%ORDER”,即前面加上了“%RETRY”这个字符串。
Consumer在一开始启动的时候,就为用户自动注册了订阅组的重试Topic,即用户不单单只接收这个Group的Topic的消息,也接收这个Group的重试Topic的消息,这样以来,就为用户如何接收重试消息奠定了基础。
当Consumer客户端在消费消息的时候,抛出了异常、返回了非正确消费的状态等错误的时候,这时,ConsumeMessageConcurrentlyService会收集所有失败的消息,然后将每一条消息封装进CONSUMER_SEND_MSG_BACK的请求中,并将其发送到Broker服务器:
public class ConsumeMessageConcurrentlyService implements ConsumeMessageService {
public void processConsumeResult(final ConsumeConcurrentlyStatus status,
/** 其他参数 **/) {
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
// ...
break;
case CLUSTERING:
for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) {
MessageExt msg = consumeRequest.getMsgs().get(i);
// 重新将消息发往 Broker 服务器
boolean result = this.sendMessageBack(msg, context);
}
// ...
break;
default:
break;
}
}
}
当消费失败的消息重新发送到服务器后,Broker会为其指定新的Topic重试Topic,并根据当前这条消息的已有的重试次数来选择定时级别,即将这条消息变成定时消息投放到重试Topic消息队列中。可见消息消费失败后并不是立即进行新的投递,而是有一定的延迟时间的。延迟时间随着重试次数的增加而增加,也即投递的时间的间隔也越来越长:
public class SendMessageProcessor
extends AbstractSendMessageProcessor
implements NettyRequestProcessor {
private RemotingCommand consumerSendMsgBack(final ChannelHandlerContext ctx,
final RemotingCommand request)
throws RemotingCommandException {
// 指定为重试话题
String newTopic = MixAll.getRetryTopic(requestHeader.getGroup());
int queueIdInt = Math.abs(this.random.nextInt() % 99999999) % subscriptionGroupConfig.getRetryQueueNums();
// 指定为延时信息,设定延时级别
if (0 == delayLevel) {
delayLevel = 3 + msgExt.getReconsumeTimes();
}
msgExt.setDelayTimeLevel(delayLevel);
// 重试次数增加
msgInner.setReconsumeTimes(msgExt.getReconsumeTimes() + 1);
// 重新存储
PutMessageResult putMessageResult = this.brokerController.getMessageStore().putMessage(msgInner);
// ...
}
}
当然,消息如果一直消费不成功,那也不会一直无限次的尝试重新投递,当重试次数大于最大重试次数(默认为16次)的时候,该消息将会被送往死信队列,认定这条消息投递无门:
public class SendMessageProcessor
extends AbstractSendMessageProcessor
implements NettyRequestProcessor {
private RemotingCommand consumerSendMsgBack(final ChannelHandlerContext ctx,
final RemotingCommand request)
throws RemotingCommandException {
// 重试次数大于最大重试次数
if (msgExt.getReconsumeTimes() >= maxReconsumeTimes
|| delayLevel < 0) {
// 死信队列话题
newTopic = MixAll.getDLQTopic(requestHeader.getGroup());
queueIdInt = Math.abs(this.random.nextInt() % 99999999) % DLQ_NUMS_PER_GROUP;
}
// ...
}
}
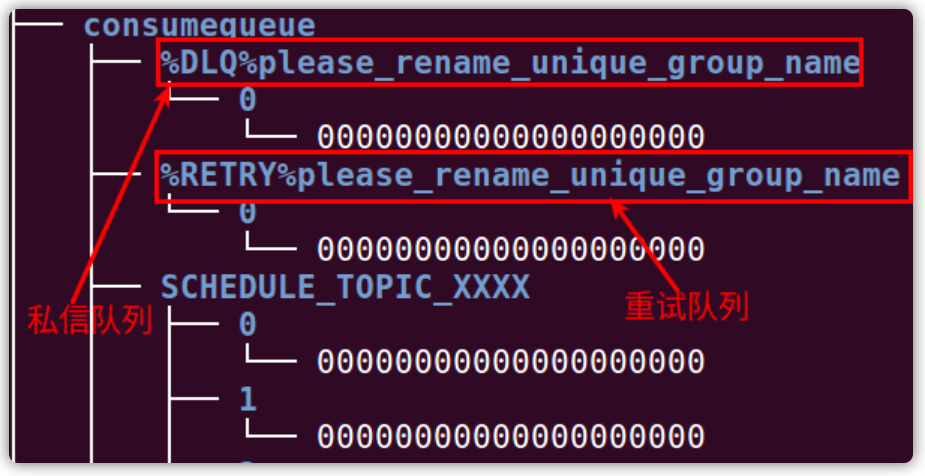
上述客户端消费失败的流程图如下所示:
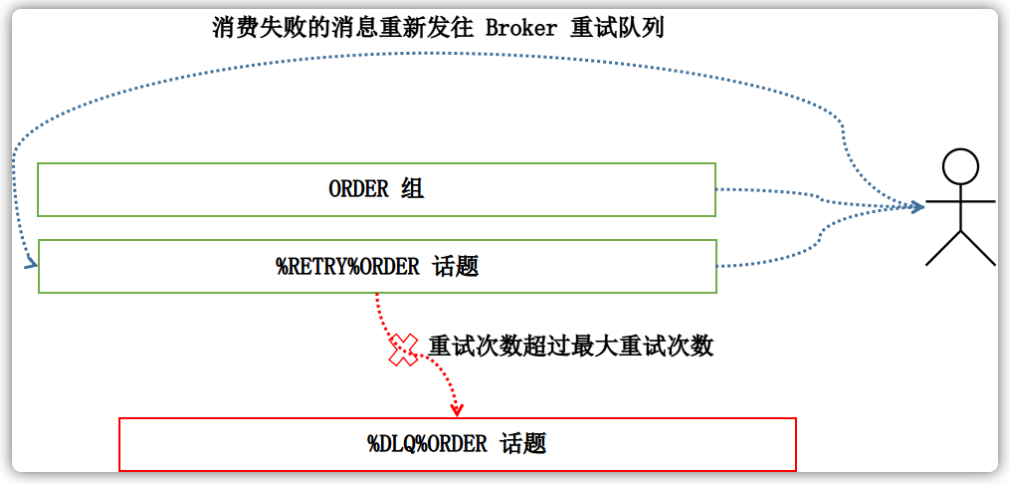
主备同步
RocketMQ通过Master-Slave主备机制,来实现整个系统的高可用,具体表现在:
- Master磁盘坏掉,Slave依然保存了一份
- Master宕机,不影响消费者继续消费
假设我们在同一台机器上搭建了一个Master和一个Slave的环境:
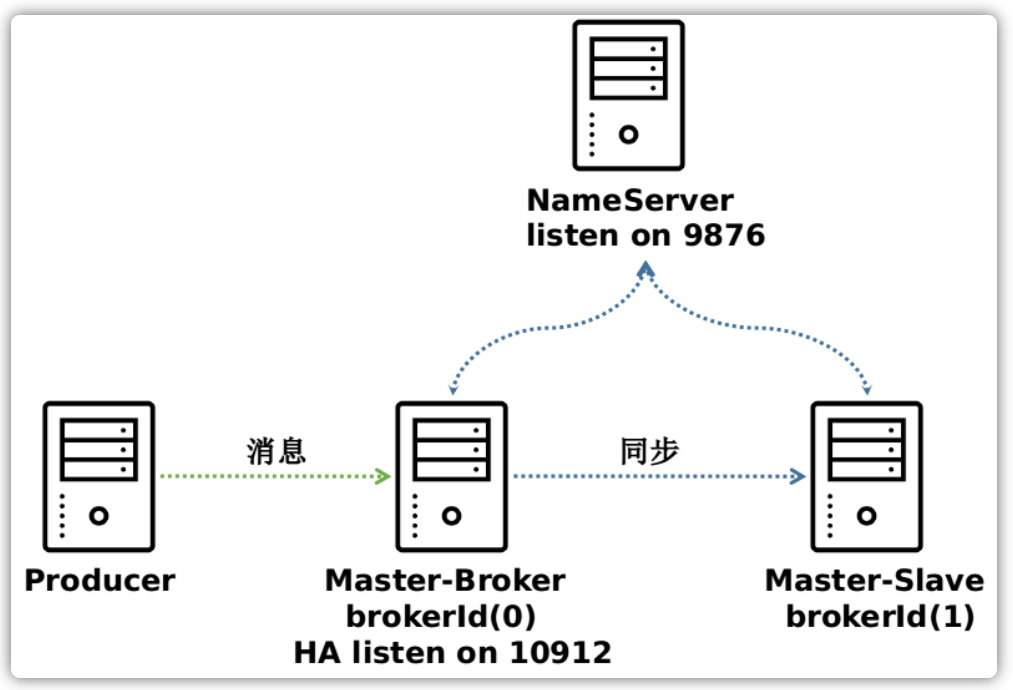
为了能够将Master和Slave搭建在同一台计算机上,我们除了需要将Broker的角色设置为SLAVE,还需要为其指定单独的brokerId、storePathRootDir、storePathCommitLog。
// SLAVE 角色
messageStoreConfig.setBrokerRole(BrokerRole.SLAVE);
// 一个机器如果要启动多个 Broker,那么每个 Broker 的 store 根目录必须不同
messageStoreConfig.setStorePathRootDir(storePathRootDir);
// 一个机器如果要启动多个 Broker,那么每个 Broker 的 storePathCommitLog 根目录必须不同
messageStoreConfig.setStorePathCommitLog(storePathCommitLog);
// 设置 Slave 的 Master HA 地址
messageStoreConfig.setHaMasterAddress("localhost:10912");
// SLAVE 角色的 brokerId 必须大于 0
brokerConfig.setBrokerId(1);
注意Slave和Master的brokerName必须一致,即它们必须处于同一个BrokerData数据结构里面。实际上在做了如上的修改之后,Slave和Master依旧不能同时运行在同一台机器上,因为Slave本身也可以称为Master,接收来自其它Slave的请求,因此当运行Slave的时候,需要将HAService里面的启动AcceptSocketService运行的相关方法注释掉。
建立连接
当一个Broker在启动的时候,会调用HAService的start()方法:
public class HAService {
public void start() throws Exception {
this.acceptSocketService.beginAccept();
this.acceptSocketService.start();
this.groupTransferService.start();
this.haClient.start();
}
}
AcceptSocketService服务的功能是Master等待接收来自其它客户端Slave的连接,当成功建立连接后,会将这条连接HAConnecion放入到connectionList连接列表里面,而HAClient服务的功能是Slave主动发起同其它Master的连接。
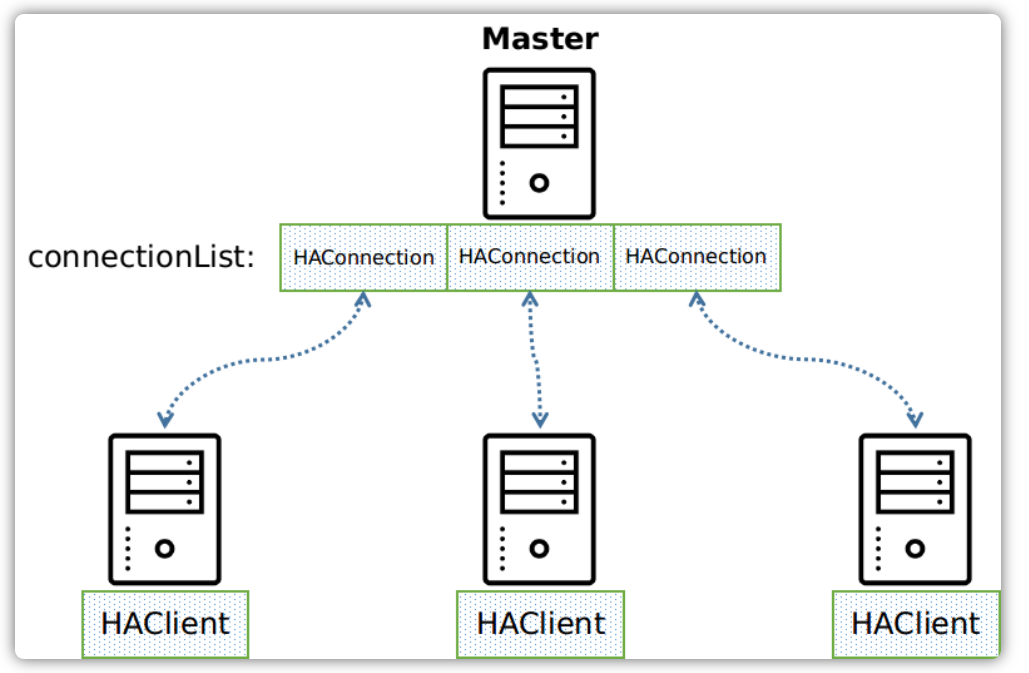
数据传输
当启动HAService之后,一旦Master发现和Slave不同步,那么Master会自动开始同步消息到Slave,无需其它的触发机制。

消息的传输方式主要分为两种:
- 消息异步传输
- 消息同步传输
消息异步传输
如果Mater Broker的角色是ASYNC_MASTER,那么消息等待从Master同步到Slave的方式是异步传输的方式。这意味当一条消息发送到Master Broker的时候,Master Broker在存储完这条消息到本地之后,并不会等待消息同步到Slave Broker才返回。这种方式会缩短发送消息的响应时间。
消息同步传输
如果Master Broker的角色是SYNC_MASTER,那么消息等待从Master同步到Slave的方式是同步传输方式。除此之外,进入同步方式还得满足另外两个条件:
- 消息体的PROPERTY_WAIT_STORE_MSG_OK属性值为true,即这条消息允许等待
- Slave相比Master落下的同步进度不能超过265MB
public class CommitLog {
public void handleHA(AppendMessageResult result, PutMessageResult putMessageResult, MessageExt messageExt) {
if (BrokerRole.SYNC_MASTER == this.defaultMessageStore.getMessageStoreConfig().getBrokerRole()) {
HAService service = this.defaultMessageStore.getHaService();
// 消息是否允许等待同步
if (messageExt.isWaitStoreMsgOK()) {
// Slave 是否没有落下 Master 太多
if (service.isSlaveOK(result.getWroteOffset() + result.getWroteBytes())) {
// 等待同步完成
// ...
}
// Slave problem
else {
// Tell the producer, slave not available
putMessageResult.setPutMessageStatus(PutMessageStatus.SLAVE_NOT_AVAILABLE);
}
}
}
}
}
其中isSlaveOK方法就是用来检测Slave和Master落下的同步进度是否太大的:
public class HAService {
public boolean isSlaveOK(final long masterPutWhere) {
boolean result = this.connectionCount.get() > 0;
result =
result
&& ((masterPutWhere - this.push2SlaveMaxOffset.get()) <
this.defaultMessageStore
.getMessageStoreConfig()
.getHaSlaveFallbehindMax()); // 默认 256 * 1024 * 1024 = 256 MB
return result;
}
}
如果上面两个条件不满足的话,那么Master便不会再等待消息同步到Slave之后再返回,能尽早返回便尽早返回了。
消息等待是否同步到Slave是借助CountDownLatch来实现的。当消息需要等待的时候便会构建一个GroupCommitRequest,每个请求在其内部都维护了一个CountDownLatch,然后通过调用await(timeout)方法来等待消息同步到Slave之后,或者超时之后自动返回。
public static class GroupCommitRequest {
private final CountDownLatch countDownLatch = new CountDownLatch(1);
public void wakeupCustomer(final boolean flushOK) {
this.flushOK = flushOK;
this.countDownLatch.countDown();
}
public boolean waitForFlush(long timeout) {
try {
this.countDownLatch.await(timeout, TimeUnit.MILLISECONDS);
return this.flushOK;
} catch (InterruptedException e) {
log.error("Interrupted", e);
return false;
}
}
}
我们需要重点掌握几个循环体和唤醒点:
GroupTransferService服务的是否处理请求的循环体和唤醒点:
class GroupTransferService extends ServiceThread { public synchronized void putRequest(final CommitLog.GroupCommitRequest request) { // ... // 放入请求,唤醒 if (hasNotified.compareAndSet(false, true)) { waitPoint.countDown(); // notify } } public void run() { // 循环体 while (!this.isStopped()) { try { // putRequest 会提前唤醒这句话 this.waitForRunning(10); this.doWaitTransfer(); } catch (Exception e) { log.warn(this.getServiceName() + " service has exception. ", e); } } } }HAConnection的是否进行消息传输的循环体和唤醒点:
class WriteSocketService extends ServiceThread { @Override public void run() { // 循环体 while (!this.isStopped()) { SelectMappedBufferResult selectResult = HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere); if (selectResult != null) { // 传输(写入)消息 } else { // 等待 100 毫秒或者提前被唤醒 HAConnection.this.haService.getWaitNotifyObject().allWaitForRunning(100); } } } } public class CommitLog { public void handleHA(AppendMessageResult result, PutMessageResult putMessageResult, MessageExt messageExt) { GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes()); service.putRequest(request); // 提前唤醒 WriteSocketService service.getWaitNotifyObject().wakeupAll(); } }Slave汇报进度唤醒GroupTransferService,等待同步完成唤醒GroupCommitRequest的CountDownLatch:
class ReadSocketService extends ServiceThread { private boolean processReadEvent() { // 唤醒 GroupTransferService HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset); } } class GroupTransferService extends ServiceThread { // 被唤醒 public void notifyTransferSome() { this.notifyTransferObject.wakeup(); } private void doWaitTransfer() { for (CommitLog.GroupCommitRequest req : this.requestsRead) { boolean transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset(); // 5 次重试 for (int i = 0; !transferOK && i < 5; i++) { // 等待被唤醒或者超时 this.notifyTransferObject.waitForRunning(1000); transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset(); } // 唤醒 GroupCommitRequest 的 CountDownLatch req.wakeupCustomer(transferOK); } } } public static class GroupCommitRequest { // 被唤醒 public void wakeupCustomer(final boolean flushOK) { this.flushOK = flushOK; this.countDownLatch.countDown(); } }
完整的消息唤醒链:
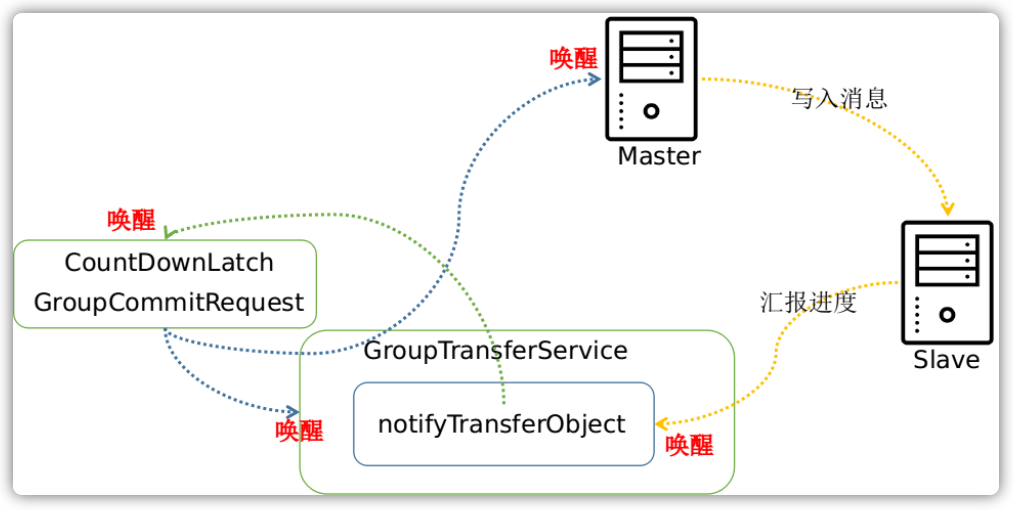
消费建议
当消费者在消费的时候,如果Master突然宕机,那么消费者会自动切换到Slave机器上继续进行消费。
RocketMQ提供了自动从Slave读取老数据的功能,这个功能主要由slaveReadEnable这个参数控制。默认是关的(slaveReadEnable=false)。推荐主从都打开,这个参数打开之后,在客户端消费数据时,会判断,当前读取消息的物理偏移量跟最新的位置的差值,是否超过了内存容量的一个百分比(accessMessageInMemoryMaxRatio = 40 by default)。如果超过了,就会告诉客户端去备机上消费数据。如果采用异步主从,也就是broekrRole等于ASYNC_AMSTER的时候,备机IO爆了,其实影响不太大,但是如果采用同步主从,就会收到影响,这个时候,最好是有两个备机,因为RocketMQ的主从同步复制,只要一个备机响应了确认写入就可以了,另一台IO爆了,问题不是很大。
异常处理
一、Master(Slave)读取来自Slave(Master)的消息异常(IOException、read()返回-1等)的时候怎么处理?
答:打印日志+关闭这条连接。
二、Master(Slave)长时间没有收到来自Slave(Master)的进度汇报怎么处理?
答:每次读取之后更新lastReadTimeStamp或者lastWriteTimestamp,一旦发现在haHousekeepingInterval间隔内(默认20秒)这个时间戳没有改变的话,关闭这条连接。
三、Slave检测到来自Master汇报的本次传输偏移量和本地的传输偏移量不同时怎么处理?
答:打印日志+关闭这条连接。
四、Master如何知道Slave是否真正的存储了刚才发送过去的消息?
答:Slave存储完毕之后,通过向Master汇报进度来完成。相当于TCP的ACK机制。
五、Master宕机
答:无论Master是主动关闭Master,还是Master因为异常而退出,Slave都会每隔5秒重连一次Master。
事务消息
发送事务消息
发送事务大致分为三个步骤:
- 初始化事务环境
- 发送消息并执行本地事务
- 结束事务
初始化事务环境是为了构建checkExecutor线程池:
public class TransactionMQProducer extends DefaultMQProducer {
@Override
public void start() throws MQClientException {
this.defaultMQProducerImpl.initTransactionEnv();
super.start();
}
}
发送消息并执行本地事务:
public class TransactionMQProducer extends DefaultMQProducer {
@Override
public TransactionSendResult sendMessageInTransaction(final Message msg, final Object arg) throws MQClientException {
return this.defaultMQProducerImpl.sendMessageInTransaction(msg, null, arg);
}
}
下面是DefaultMQProducerImpl类的发送事务消息的具体实现:
public TransactionSendResult sendMessageInTransaction(final Message msg, final LocalTransactionExecuter localTransactionExecuter, final Object arg) throws MQClientException {
// 标识这条消息的属性:TRANSACTION_PREPARED
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_TRANSACTION_PREPARED, "true");
// 发送消息
sendResult = this.send(msg);
// 根据消息的发送状态决定是否执行本地事务
switch (sendResult.getSendStatus()) {
// 发送消息成功
case SEND_OK: {
// 获取事务 ID
if (sendResult.getTransactionId() != null) {
msg.putUserProperty("__transactionId__", sendResult.getTransactionId());
}
String transactionId = msg.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);
if (null != transactionId && !"".equals(transactionId)) {
msg.setTransactionId(transactionId);
}
// 执行本地事务
if (null != localTransactionExecuter) {
localTransactionState = localTransactionExecuter.executeLocalTransactionBranch(msg, arg);
} else if (transactionListener != null) {
log.debug("Used new transaction API");
localTransactionState = transactionListener.executeLocalTransaction(msg, arg);
}
}
break;
// 发送消息失败
case FLUSH_DISK_TIMEOUT:
case FLUSH_SLAVE_TIMEOUT:
case SLAVE_NOT_AVAILABLE:
localTransactionState = LocalTransactionState.ROLLBACK_MESSAGE;
break;
}
// 事务结束
this.endTransaction(sendResult, localTransactionState, localException);
}
从上述代码可以看出,RocketMQ是先发送消息,然后再执行本地事务。
在endTransaction内部,需要根据本地事务执行的状态,来决定是COMMIT还是ROLLBACK已经发送到服务器的消息:
switch (localTransactionState) {
case COMMIT_MESSAGE:
requestHeader.setCommitOrRollback(MessageSysFlag.TRANSACTION_COMMIT_TYPE);
break;
case ROLLBACK_MESSAGE:
requestHeader.setCommitOrRollback(MessageSysFlag.TRANSACTION_ROLLBACK_TYPE);
break;
case UNKNOW:
requestHeader.setCommitOrRollback(MessageSysFlag.TRANSACTION_NOT_TYPE);
break;
default:
break;
}
// 调用 API: 只调用一次,不重试
this.mQClientFactory.getMQClientAPIImpl().endTransactionOneway(brokerAddr, requestHeader, remark, this.defaultMQProducer.getSendMsgTimeout());
其中endTransactionOneway()发送的是到Server的END_TRANSACTION命令:
RemotingCommand request = RemotingCommand.createRequestCommand(RequestCode.END_TRANSACTION, requestHeader);
接收事务消息
接收事务消息大致分为两个阶段:
- 接收事务准备消息
- 接收事务结束消息
接收事务准备消息
Broker检查收到的消息是否是PROPERTY_TRANCSACTION_PREPARED消息:
// SendMessageProcessor
String transFlag = origProps.get(MessageConst.PROPERTY_TRANSACTION_PREPARED);
if (transFlag != null && Boolean.parseBoolean(transFlag)) {
if (this.brokerController.getBrokerConfig().isRejectTransactionMessage()) {
// 没有发送事务的权限
response.setCode(ResponseCode.NO_PERMISSION);
return CompletableFuture.completedFuture(response);
}
putMessageResult = this.brokerController.getTransactionalMessageService().asyncPrepareMessage(msgInner);
}
异步准备消息内部,其实就是存储half消息的过程:
// org.apache.rocketmq.broker.transaction.queue.TransactionalMessageServiceImpl
@Override
public CompletableFuture<PutMessageResult> asyncPrepareMessage(MessageExtBrokerInner messageInner) {
return transactionalMessageBridge.asyncPutHalfMessage(messageInner);
}
将消息的Topic替换为了RMQ_SYS_TRANS_HALF_TOPIC:
// 备份原来真正的 Topic
MessageAccessor.putProperty(msgInner, MessageConst.PROPERTY_REAL_TOPIC, msgInner.getTopic());
msgInner.setTopic(TransactionalMessageUtil.buildHalfTopic());
public static String buildHalfTopic() {
return TopicValidator.RMQ_SYS_TRANS_HALF_TOPIC;
}
下图是,刚发送完PREPARED消息后,consumequeue文件夹中存放的文件:

PREPARED消息不会被消费吗?
PREPARED消息在存储到磁盘之前,会将Topic改为RMQ_SYS_TRANS_HALF_TOPIC,因此通过订阅该消息关联的原来的Topic,是消费不到该消息的。
另外就是在Broker分发消息的时候,正常情况下,当收到了一条消息,后台会根据消息,构建consume文件(下面代码中的putMessagePositionInfo()方法就是为了构建消费文件),以供消费者消费。但是在遇到PREPARED消息的时候,就不再构建consume文件了,即消费者根本看不到这条消息。
// DefaultMessageStore.java
class CommitLogDispatcherBuildConsumeQueue implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
final int tranType = MessageSysFlag.getTransactionValue(request.getSysFlag());
switch (tranType) {
case MessageSysFlag.TRANSACTION_NOT_TYPE:
case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
DefaultMessageStore.this.putMessagePositionInfo(request);
break;
case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
break;
}
}
}
接收事务结束的消息
对于END_TRANSACTION的请求,BrokerController注册了单独的处理器来处理事务结束的命令:
// BrokerController
this.remotingServer.registerProcessor(RequestCode.END_TRANSACTION, new EndTransactionProcessor(this), this.endTransactionExecutor);
EndTransactionProcessor内部,处理命令的逻辑如下:
// SLAVE 不支持接受 END_TRANSACTION 命令
if (BrokerRole.SLAVE == brokerController.getMessageStoreConfig().getBrokerRole()) {
response.setCode(ResponseCode.SLAVE_NOT_AVAILABLE);
return response;
}
if (MessageSysFlag.TRANSACTION_COMMIT_TYPE == requestHeader.getCommitOrRollback()) {
// COMMIT 消息
} else if (MessageSysFlag.TRANSACTION_ROLLBACK_TYPE == requestHeader.getCommitOrRollback()) {
// ROLLBACK 消息
}
COMMIT消息的实现:
result = this.brokerController.getTransactionalMessageService().commitMessage(requestHeader);
MessageExtBrokerInner msgInner = endMessageTransaction(result.getPrepareMessage());
msgInner.setSysFlag(MessageSysFlag.resetTransactionValue(msgInner.getSysFlag(), requestHeader.getCommitOrRollback()));
MessageAccessor.clearProperty(msgInner, MessageConst.PROPERTY_TRANSACTION_PREPARED);
RemotingCommand sendResult = sendFinalMessage(msgInner);
if (sendResult.getCode() == ResponseCode.SUCCESS) {
this.brokerController.getTransactionalMessageService().deletePrepareMessage(result.getPrepareMessage());
}
上述代码第一行commitMessage内部是根据commitLogOffset这个偏移量,从commitLog的MappedFile文件中查找消息的过程。
第二行的endMessageTransaction内部根据preparedMessage构建了新的Message,恢复了Topic、拷贝了这个消息上其它的属性信息,最重要的是清除了MessageConst、PROPERTY_TRANSACTION_PREPARED属性,以便这个消息可以构建消费队列文件,从而让消费者能够消费。
最后sendMessage内部就是将构建好的新的消息体,重新调用Broker端的发送消息的流程,来发送消息。所以消费端消费已经不是之前发送的PREPARED消息,而是根据PREPARED消息重新克隆出来的新的消息体,当然内容、属性等都是一样的。
最后deletePrepareMessage的过程,内部其实只是给这条消息打赏了一个TransactionMessageUtil.REMOVETAG标签,然后重新putMessage()。
下图展示的是,执行COMMIT之后的,consumequeue存放文件的情况:
RollBack回滚消息的实现:
回滚消息第一步也是根据commitOffset查找消息,然后再给这条消息打上TransactionalMessageUtil.REMOVETAG 的过程。
下图是消息执行ROLLBACK之后的consumequeue所存储的文件的状态:
扫描事务状态
加入Client执行本地事务,运行时间过长,或者发送了COMMIT消息或者ROLLBACK消息,但是这条消息由于网络原因等没有到达Server端,那么可能会导致PREPARED的消息越来越多。因此Broker会在后台定期给Client发送检查事务状态的消息,主要通过如下三种方式:
- Server定时扫描
- Server检查事务状态
- 客户端检查事务状态
Server定时扫描
public class TransactionalMessageCheckService extends ServiceThread {
@Override
public void run() {
long checkInterval = brokerController.getBrokerConfig().getTransactionCheckInterval();
while (!this.isStopped()) {
this.waitForRunning(checkInterval);
}
}
@Override
protected void onWaitEnd() {
long timeout = brokerController.getBrokerConfig().getTransactionTimeOut();
int checkMax = brokerController.getBrokerConfig().getTransactionCheckMax();
// 检查事务状态
this.brokerController.getTransactionalMessageService().check(timeout, checkMax, this.brokerController.getTransactionalMessageCheckListener());
}
}
- transactionCheckInterval = 60 * 1000:每隔60s执行一次check方法
- transactionTimeOut = 6 * 1000:第一次检查事务消息的时间,一条消息只有大于这个时间还没有收到COMMIT或者ROLLBACK,那么就执行检查
- transactionCheckMax = 15:最多执行多少次检查后,如果依然还没有收到这条消息是提交还是回滚,那么这条消息将被丢弃
Server检查事务状态
在check方法内部,Server端需要扫描是否有消息需要取检查事务的状态,如果需要,则会给Client发送CHECK_TRANSACTION_STATE命令。
首先,Broker将自己作为一个客户端来去订阅消费RMQ_SYS_TRANS_OP_HALF_TOPIC Topic中的消息。
// TransactionalMessageBridge.java
public PullResult getOpMessage(int queueId, long offset, int nums) {
String group = TransactionalMessageUtil.buildConsumerGroup();
String topic = TransactionalMessageUtil.buildOpTopic();
SubscriptionData sub = new SubscriptionData(topic, "*");
return getMessage(group, topic, queueId, offset, nums, sub);
}
那么每一次消费,我们怎么知道上一次消费到哪里了呢?实际上,最新的消息偏移量存储在了offsetTable中:
// ConsumerOffsetManager.java
public long queryOffset(final String group, final String topic, final int queueId) {
// topic@group
String key = topic + TOPIC_GROUP_SEPARATOR + group;
ConcurrentMap<Integer, Long> map = this.offsetTable.get(key);
if (null != map) {
Long offset = map.get(queueId);
if (offset != null)
return offset;
}
return -1;
}
offsetTable在后台也会定时地将里面的信息保存到磁盘上的config/consumerOffset.json文件中(如下图所示)。0:9的0表示queueId,9表示最新的offset。
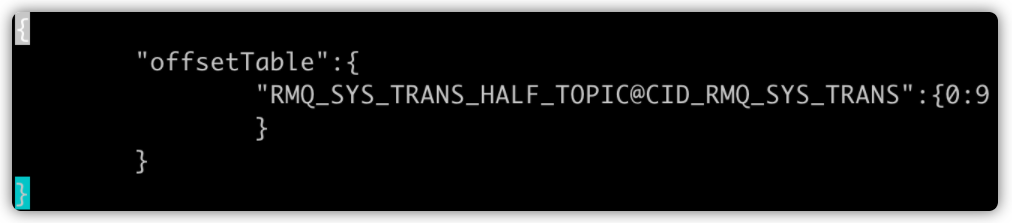
在获取到上一轮offset到最新的offset之间的消息列表后,那么就需要逐一检查这些消息的事务状态了:
PullResult pullResult = fillOpRemoveMap(removeMap, opQueue, opOffset, halfOffset, doneOpOffset);
long i = halfOffset;
while (true) {
// ...
GetResult getResult = getHalfMsg(messageQueue, i);
// ...
if (isNeedCheck) {
// ...
listener.resolveHalfMsg(msgExt);
}
}
msgExt的内部状态:
那么在每一轮循环中,即每一条消息内部,逻辑又是怎么样执行的呢?
// TransactionalMessageServiceImpl
if (System.currentTimeMillis() - startTime > MAX_PROCESS_TIME_LIMIT) {
break;
}
if (needDiscard(msgExt, transactionCheckMax) || needSkip(msgExt)) {
continue;
}
long valueOfCurrentMinusBorn = System.currentTimeMillis() - msgExt.getBornTimestamp();
long checkImmunityTime = transactionTimeout;
boolean isNeedCheck = (opMsg == null && valueOfCurrentMinusBorn > checkImmunityTime);
if (isNeedCheck) {
if (!putBackHalfMsgQueue(msgExt, i)) {
continue;
}
listener.resolveHalfMsg(msgExt);
}
我们可以看到:
首先对于while(true)的时间设定了限制,不能超过MAX_PROCESS_TIME_LIMIT这个值
其次,needDiscard这个方法检查的就是从消息的MessageConst.PROPERTY_TRANSACTION_CHECK_TIMES属性中,获取到这个消息已经检查了多少次,如果超过transactionCheckMax,那么就需要丢弃
needSkip()函数判断的是这条消息自诞生以来,在Broker端放置的时间是否超过了3天,如果超过3天,这条消息也没有必要检查了,因此RocketMQ默认存储消息的最长时间就是3天
isNeedCheck看的主要就是消息诞生的时间是否超过了transactionTimeout
putBackHalfMsgQueue主要就是将当前的消息,最新修改的属性等,重新拷贝一份,然后将新的消息追加到MappedFile的末尾
resolveHalfMsg就是在线程池中执行发送检查事务状态的任务:
public void resolveHalfMsg(final MessageExt msgExt) { executorService.execute(new Runnable() { @Override public void run() { try { sendCheckMessage(msgExt); } catch (Exception e) { LOGGER.error("Send check message error!", e); } } }); }
sendCheckMessage的内部实现:
// AbstractTransactionalMessageCheckListener.java
String groupId = msgExt.getProperty(MessageConst.PROPERTY_PRODUCER_GROUP);
Channel channel = brokerController.getProducerManager().getAvaliableChannel(groupId);
if (channel != null) {
brokerController.getBroker2Client().checkProducerTransactionState(groupId, channel, checkTransactionStateRequestHeader, msgExt);
}
checkProducerTransactionState的内部实现,就是发送了CHECK_TRANSACTION_STATE报文给Client:
// Broker2Client.java
RemotingCommand request =
RemotingCommand.createRequestCommand(RequestCode.CHECK_TRANSACTION_STATE, requestHeader);
request.setBody(MessageDecoder.encode(messageExt, false));
try {
this.brokerController.getRemotingServer().invokeOneway(channel, request, 10);
} catch (Exception e) {
log.error("Check transaction failed because invoke producer exception. group={}, msgId={}, error={}",
group, messageExt.getMsgId(), e.toString());
}
客户端检查事务状态
Producer也通过Netty监听了一个端口上,这样也能接收来自外界的命令了:
public class ClientRemotingProcessor extends AsyncNettyRequestProcessor implements NettyRequestProcessor {
@Override
public RemotingCommand processRequest(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
switch (request.getCode()) {
case RequestCode.CHECK_TRANSACTION_STATE:
return this.checkTransactionState(ctx, request);
}
}
}
当收到CHECK_TRANSACTION_STATE命令后,Client会解析出消息的事务ID、存放消息的Broker地址等:
String transactionId = messageExt.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);
final String group = messageExt.getProperty(MessageConst.PROPERTY_PRODUCER_GROUP);
if (group != null) {
MQProducerInner producer = this.mqClientFactory.selectProducer(group);
if (producer != null) {
// Broker 地址
final String addr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
producer.checkTransactionState(addr, messageExt, requestHeader);
}
}
然后checkTransactionState内部则通过线程池提交了一个新的任务,检查事务的状态,并反馈给Broker。
localTransactionState = transactionListener.checkLocalTransaction(message);
// COMMIT_TYPE 或者 ROLLBACK_TYPE 等
thisHeader.setCommitOrRollback(MessageSysFlag.TRANSACTION_COMMIT_TYPE);
DefaultMQProducerImpl.this.mQClientFactory.getMQClientAPIImpl().endTransactionOneway(brokerAddr, thisHeader, remark, 3000);
ACL权限控制
RocketMQ从4.4.0版本引入了ACL权限控制功能,可以给Topic指定全选,只有拥有权限的消费者才可以进行消费。
使用示例
首先定义一个RPCHook:
private static final String ACL_ACCESS_KEY = "RocketMQ";
private static final String ACL_SECRET_KEY = "1234567";
static RPCHook getAclRPCHook() {
return new AclClientRPCHook(new SessionCredentials(ACL_ACCESS_KEY,ACL_SECRET_KEY));
}
然后在发消息的时候指定RPCHook:
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName", getAclRPCHook());
接收消息的时候也需要指定具有同样ACCESS_KEY和SECRET_KEY的RPCHook:
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("please_rename_unique_group_name_6", getAclRPCHook());
RPCHook
从示例代码中,我们可以看出可以为Producer指定一个RPCHook,随后此RPCHook会被注册进来:
// org.apache.rocketmq.client.impl.MQClientAPIImpl.class
this.remotingClient.registerRPCHook(rpcHook);
注册的实质就是将其放入了rpcHooks列表中:
// org.apache.rocketmq.remoting.netty.NettyRemotingAbstract.java
protected List<RPCHook> rpcHooks = new ArrayList<RPCHook>();
在Producer端调用底层API发送命令的前后,调用RPCHook上面的doBeforeRequest和doAfterRequest方法,便于在发送命令的前后拦截:
@Override
public RemotingCommand invokeSync(String addr, final RemotingCommand request, long timeoutMillis) {
doBeforeRpcHooks(addr, request);
// ...
doAfterRpcHooks(RemotingHelper.parseChannelRemoteAddr(channel), request, response);
}
protected void doBeforeRpcHooks(String addr, RemotingCommand request) {
if (rpcHooks.size() > 0) {
for (RPCHook rpcHook: rpcHooks) {
rpcHook.doBeforeRequest(addr, request);
}
}
}
protected void doAfterRpcHooks(String addr, RemotingCommand request, RemotingCommand response) {
if (rpcHooks.size() > 0) {
for (RPCHook rpcHook: rpcHooks) {
rpcHook.doAfterResponse(addr, request, response);
}
}
}
AclClientRPCHook
下面来看AclClientRPCHook在发送命令的前后做了什么事情:
@Override
public void doBeforeRequest(String remoteAddr, RemotingCommand request) {
// 生成签名
byte[] total = AclUtils.combineRequestContent(request,
parseRequestContent(request, sessionCredentials.getAccessKey(), sessionCredentials.getSecurityToken()));
String signature = AclUtils.calSignature(total, sessionCredentials.getSecretKey());
// 添加扩展字段
request.addExtField(SIGNATURE, signature);
request.addExtField(ACCESS_KEY, sessionCredentials.getAccessKey());
// The SecurityToken value is unneccessary,user can choose this one.
if (sessionCredentials.getSecurityToken() != null) {
request.addExtField(SECURITY_TOKEN, sessionCredentials.getSecurityToken());
}
}
@Override
public void doAfterResponse(String remoteAddr, RemotingCommand request, RemotingCommand response) {
// 空实现
}
可以看到doBeforeRequest主要完成了两件事情:
- 生成签名
- 添加扩展字段
生成签名
parseRequestContent方法内部将request的自定义头部上面的所有字段的name和value放入到了一个SortedMap中,同时将ACCESS_KEY和SECURITY_TOKEN(如果有)也放了进去:
map.put(ACCESS_KEY, ak);
if (securityToken != null) {
map.put(SECURITY_TOKEN, securityToken);
}
当然获取类上面的所有字段是通过反射实现的,为了提高性能,也是使用了Map进行了缓存。缓存的只是Field字段,而非value。
protected ConcurrentHashMap<Class<? extends CommandCustomHeader>, Field[]> fieldCache =
new ConcurrentHashMap<Class<? extends CommandCustomHeader>, Field[]>();
之所以获取到所有字段的值,是为了计算签名,计算签名的方法如下:
首先将上述所有的字段的值拼接成字段,然后获取字节数组,再与请求本身的body的字节数组拼接在一起,获取到最终的byte[]数组。
// AclUtils.java public static byte[] combineRequestContent(RemotingCommand request, SortedMap<String, String> fieldsMap) { StringBuilder sb = new StringBuilder(""); for (Map.Entry<String, String> entry : fieldsMap.entrySet()) { if (!SessionCredentials.SIGNATURE.equals(entry.getKey())) { sb.append(entry.getValue()); } } return AclUtils.combineBytes(sb.toString().getBytes(CHARSET), request.getBody()); }然后通过calSignature方法计算签名,在内部默认采用SigningAlgorithm.HmacSHA1算法获取到签名后的byte[]数组,再通过Base64.encodeBase64将其转为字符串,返回最终的签名。
// AclClientRPCHook.java String signature = AclUtils.calSignature(total, sessionCredentials.getSecretKey());
添加扩展字段
生成签名以后,将签名、ACCESS_KEY、SECURITY_TOKEN(如果有)添加到请求的扩展字段中。
request.addExtField(SIGNATURE, signature);
request.addExtField(ACCESS_KEY, sessionCredentials.getAccessKey());
// The SecurityToken value is unneccessary,user can choose this one.
if (sessionCredentials.getSecurityToken() != null) {
request.addExtField(SECURITY_TOKEN, sessionCredentials.getSecurityToken());
}
Broker权限验证
Broker在初始化ACL的时候会判断用户是否启用了ACL:
// BrokerController.java
if (!this.brokerConfig.isAclEnable()) {
return;
}
如果用户开启了ACL,那么会从META-INF路径下去加载所有实现了AccessValidator接口的实现类:
// ServiceProvider.java
public static final String ACL_VALIDATOR_ID = "META-INF/service/org.apache.rocketmq.acl.AccessValidator";
// BrokerController.java
List<AccessValidator> accessValidators = ServiceProvider.load(ServiceProvider.ACL_VALIDATOR_ID, AccessValidator.class);
if (accessValidators == null || accessValidators.isEmpty()) {
return;
}
如果有AccessValidator的实现,那么会注册到Server端的rpcHooks列表中:
for (AccessValidator accessValidator: accessValidators) {
final AccessValidator validator = accessValidator;
accessValidatorMap.put(validator.getClass(),validator);
this.registerServerRPCHook(new RPCHook() {
@Override
public void doBeforeRequest(String remoteAddr, RemotingCommand request) {
//Do not catch the exception
validator.validate(validator.parse(request, remoteAddr));
}
@Override
public void doAfterResponse(String remoteAddr, RemotingCommand request, RemotingCommand response) {
}
});
}
而Broker中的META-INF/service/org.apache.rocketmq.acl.AccessValidator文件存储的内容如下,即采用PlainAccessValidator作为默认的权限访问校验器。
org.apache.rocketmq.acl.plain.PlainAccessValidator
Broker端收到请求后,会将请求解析为AcessResource。解析的过程就是要将RemotingCommand中附带的ip地址、ACESS_KEY、签名、SECRET_TOKEN等添加到PlainAccessResource中,并根据不同的命令,给资源添加上不同的访问权限。
@Override
public AccessResource parse(RemotingCommand request, String remoteAddr) {
PlainAccessResource accessResource = new PlainAccessResource();
// 将远程的地址放到白名单里面
accessResource.setWhiteRemoteAddress(remoteAddr.substring(0, remoteAddr.lastIndexOf(':')));
// 将 ACCESS_KEY、SIGNATURE、SECRET_TOKEN 解析出来
accessResource.setAccessKey(request.getExtFields().get(SessionCredentials.ACCESS_KEY));
accessResource.setSignature(request.getExtFields().get(SessionCredentials.SIGNATURE));
accessResource.setSecretToken(request.getExtFields().get(SessionCredentials.SECURITY_TOKEN));
// 根据不同的请求,添加不同的资源访问权限
switch (request.getCode()) {
case RequestCode.SEND_MESSAGE:
accessResource.addResourceAndPerm(request.getExtFields().get("topic"), Permission.PUB);
break;
case RequestCode.QUERY_MESSAGE:
accessResource.addResourceAndPerm(request.getExtFields().get("topic"), Permission.SUB);
break;
// ...
}
}
其中RocketMQ的Topic资源访问控制权限定义主要如下所示,分为以下四种:
public class Permission {
// 拒绝
public static final byte DENY = 1;
// PUB或者SUB权限
public static final byte ANY = 1 << 1;
// 发送权限,即从Producer端发送出来的命令,所具有的权限
public static final byte PUB = 1 << 2;
// 订阅权限,即从消费端发送出来的命令,所具有的权限
public static final byte SUB = 1 << 3;
}
以上述示例代码为例,SEND_MESSAGE命令只能是Producer端发送,因此它的权限PUB;而QUERY_MESSAGE命令只能是Consumer端查询,因此它的权限是SUB。
校验权限
生成AccessResource后,便需要对这个资源进行权限校验,校验的具体规则如下:
(1)检查是否命中全局IP白名单;如果是,则认为校验通过;否则走2;
// PlainPermissionManager.java for (RemoteAddressStrategy remoteAddressStrategy : globalWhiteRemoteAddressStrategy) { if (remoteAddressStrategy.match(plainAccessResource)) { return; } }(2)检查是否命中用户IP白名单;如果是,则认为校验通过;否则走3;
// PlainPermissionManager.java PlainAccessResource ownedAccess = plainAccessResourceMap.get(plainAccessResource.getAccessKey()); if (ownedAccess.getRemoteAddressStrategy().match(plainAccessResource)) { return; }(3)校验签名,校验不通过,抛出异常;校验通过,则走4;
// PlainPermissionManager.java String signature = AclUtils.calSignature(plainAccessResource.getContent(), ownedAccess.getSecretKey()); if (!signature.equals(plainAccessResource.getSignature())) { throw new AclException(String.format("Check signature failed for accessKey=%s", plainAccessResource.getAccessKey())); }(4)对用户请求所需要的权限和用户所拥有的权限进行校验;不通过,则抛出异常;
// 如果是 Admin 那么直接通过 if (ownedPermMap == null && ownedAccess.isAdmin()) { // If the ownedPermMap is null and it is an admin user, then return return; } // Permission.java public static boolean checkPermission(byte neededPerm, byte ownedPerm) { if ((ownedPerm & DENY) > 0) { return false; } if ((neededPerm & ANY) > 0) { return ((ownedPerm & PUB) > 0) || ((ownedPerm & SUB) > 0); } return (neededPerm & ownedPerm) > 0; }
用户所需要的权限校验需要注意以下内容:
特殊的请求如UPDATE_AND_CREATE_TOPIC等,只能由admin账户进行操作;
// PlainPermissionManager.java if (Permission.needAdminPerm(needCheckedAccess.getRequestCode()) && !ownedAccess.isAdmin()) { throw new AclException(String.format("Need admin permission for request code=%d, but accessKey=%s is not", needCheckedAccess.getRequestCode(), ownedAccess.getAccessKey())); }对于某个资源,如果由显性配置权限,则采用配置的权限;如果没有显性配置权限,则采用默认的权限;
ACL权限管理器
上述校验规则的validate方法是放在权限管理器PlainPermissionManager上面的,在新建该类实例的时候,其内部会首先加载YAML格式的权限配置文件,然后在监听这个文件的变化,做到运行时动态的更新权限。
private static final String DEFAULT_PLAIN_ACL_FILE = "/conf/plain_acl.yml";
private String fileName = System.getProperty("rocketmq.acl.plain.file", DEFAULT_PLAIN_ACL_FILE);
public void load() {
JSONObject plainAclConfData = AclUtils.getYamlDataObject(fileHome + File.separator + fileName, JSONObject.class);
// ...
}
RocketMQ在distribution/conf目录下,给出了一个默认的权限配置文件plain_acl.yml:
globalWhiteRemoteAddresses:
- 10.10.103.*
- 192.168.0.*
accounts:
- accessKey: RocketMQ
secretKey: 12345678
whiteRemoteAddress: 192.168.0.*
admin: false
defaultTopicPerm: DENY
defaultGroupPerm: SUB
topicPerms:
- topicA=DENY
- topicB=PUB|SUB
- topicC=SUB
groupPerms:
# the group should convert to retry topic
- groupA=DENY
- groupB=SUB
- groupC=SUB
- accessKey: rocketmq2
secretKey: 12345678
whiteRemoteAddress: 192.168.1.*
# if it is admin, it could access all resources
admin: true
对于此文件的监听,是通过FileWatchService进行的:
FileWatchService fileWatchService = new FileWatchService(new String[] {watchFilePath}, new FileWatchService.Listener() {
@Override
public void onChanged(String path) {
log.info("The plain acl yml changed, reload the context");
load();
}
});
fileWatchService.start();
在FileWatchService内部,其每隔WATCH_INTERVAL=500毫秒,扫描一次指定的所有文件列表。如果某个文件的MD5哈希值有变化,就会调用listener.onChanged方法来通知这个文件发生了变化。
逻辑队列
当前,MessageQueue和Broker耦合在一起,这意味着Broker数量变化之后,消息队列的数量也会发生变化,这会造成所有的队列都需要一个重新平衡的过程,这个过程可能需要数分钟才能恢复。增加逻辑队列之后,Broker数量的变化不会影响逻辑队列数量的变化,二者可以独立变化。
架构实现
假设当前一个LogicalQueue从boker1迁移到了broker2,我们迁移仅仅是映射关系,而非实际的数据,所以broker1依然能够正常消费LogicalQueue-0这个逻辑队列里面的数据,我们会将这个队列的状态置为只读,故这个队列不能再写入消息:
当broker1从commit log和consume queue中清除了所有数据后,QueueStatus变为Expired(不可读也不可写):
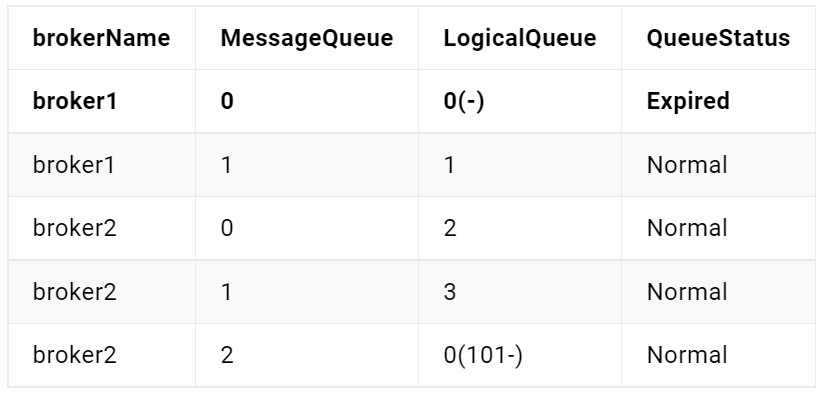
如果这个LogicQueue再次迁移回broker1,它会重用这个过期的MessageQueue:
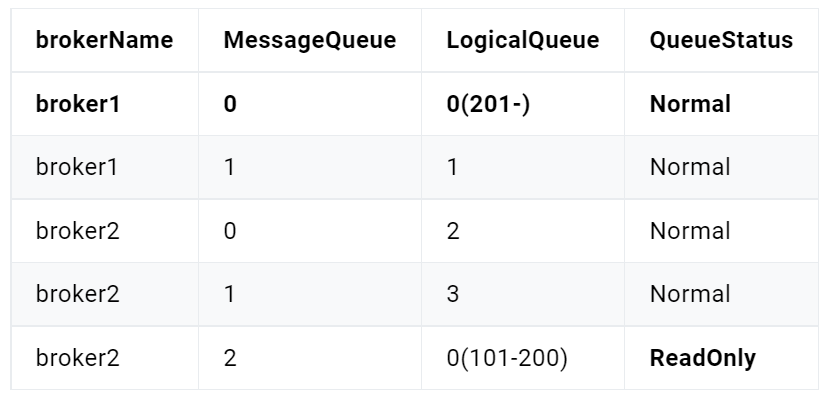
如果这个LogicQueue再次迁移回broker1的时候,当前没有过期的MessageQueue,它会创建一个新的MessageQueue:
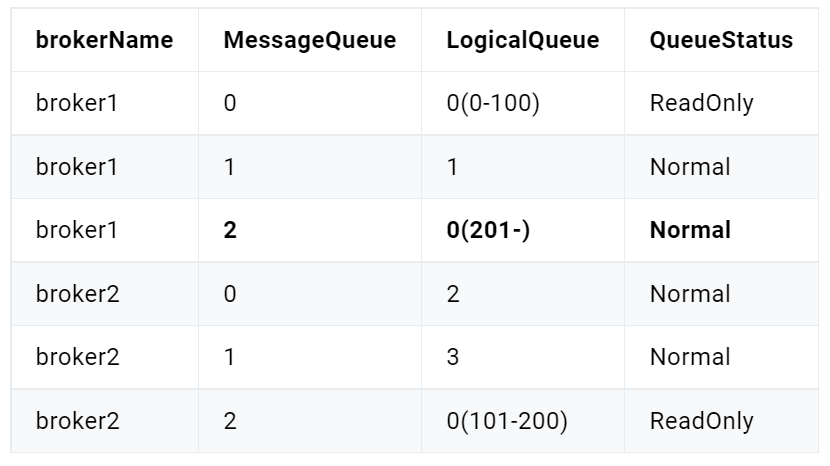
如果broker2下线了,那么上面的所有的LogicQueue都应该进行迁移:
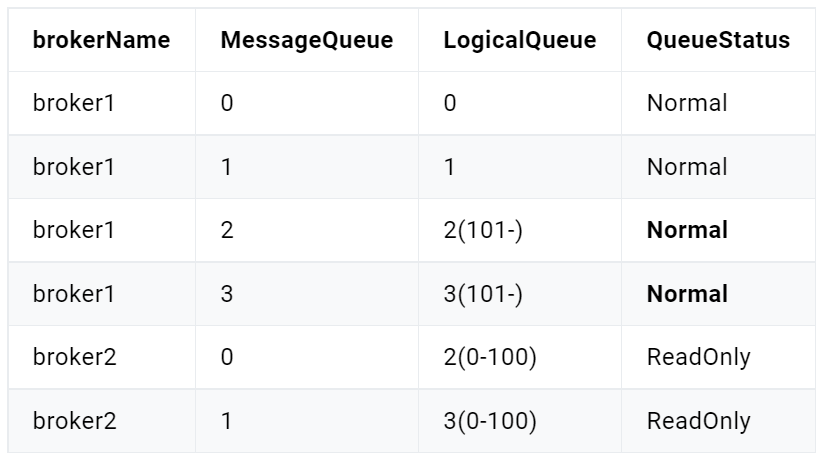
当broker2上面的所有数据包括commit log和consume queue被消费完后,那么broker2可以被移除掉了:
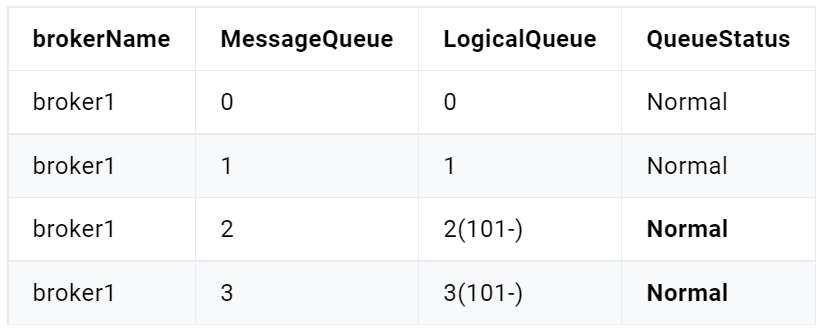
当部署了新的broker后,我们可以使用命令来迁移一些LogicQueue到这个broker上,来分担一些流量:
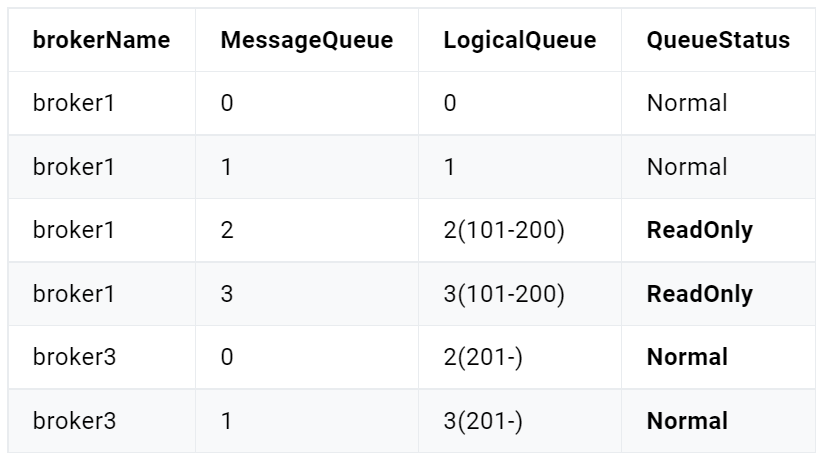
实现
public class LogicalQueuesInfo extends HashMap<Integer, List<LogicalQueueRouteData>> {
}
/**
* logical queue offset -> message queue offset mapping
*/
public class LogicalQueueRouteData implements Comparable<LogicalQueueRouteData> {
private volatile int logicalQueueIndex = -1; /* -1 means not set */
private volatile long logicalQueueDelta = -1; /* inclusive, -1 means not set, occurred in writeOnly state */
private MessageQueue messageQueue;
private volatile MessageQueueRouteState state = MessageQueueRouteState.Normal;
private volatile long offsetDelta = 0; // valid when Normal/WriteOnly/ReadOnly
private volatile long offsetMax = -1; // exclusive, valid when ReadOnly
}
Topic路由信息TopicRouteData中增加了和逻辑队列相关的信息:
public class TopicRouteData extends RemotingSerializable {
private LogicalQueuesInfo logicalQueuesInfo;
}
在构造器中,logicQueueIdx封装为了一个brokerName是__logical_queue_broker__,同时queueId是logicQueueIdx的MessageQueue:
public class SendResultForLogicalQueue extends SendResult {
public SendResultForLogicalQueue(SendResult sendResult, int logicalQueueIdx) {
super(sendResult.getSendStatus(), sendResult.getMsgId(), sendResult.getOffsetMsgId(),
new MessageQueue(sendResult.getMessageQueue().getTopic(), MixAll.LOGICAL_QUEUE_MOCK_BROKER_NAME, logicalQueueIdx),
sendResult.getQueueOffset());
// ...
}
}
public class PullResultWithLogicalQueues extends PullResultExt {
}
RocketMQ中的设计模式
监听者模式
参考文献
[1] RocketMQ官方文档
[2] RocketMQ源码分析